В хэшированием файле записи не обязательно должны вводиться в файл
последовательно. Вместо этого для вычисления адреса страницы, на которой должна
находиться запись, используется хэш-функция (hash function), параметрами которой
являются значения одного или нескольких полей этой записи. Подобное поле
называется полем хэширования (hash field), а если поле является также ключевым
полем файла, то оно называется хэш-ключом (hash key). Записи в хэшированием
файле распределены произвольным образом по всему доступному для файла
пространству. По этой причине хэшированные файлы иногда называют файлами с
произвольным или прямым доступом (random file или direct file).
хэш-функция выбирается таким образом, чтобы записи внутри файла были
распределены наиболее равномерно. Один из методов создания хэш-функции
называется сверткой (folding) и основан на выполнении некоторых
арифметических действий над различными частями поля хэширования. При этом
символьные строки преобразуются в целые числа с использованием некоторой
кодировки (на основе расположения букв в алфавите или кодов символов ASCII).
Например, можно преобразовать в целое число первые два символа поля табельного
номера сотрудника (атрибут staffNo), а затем сложить полученное значение с
остальными цифрами этого номера. Вычисленная сумма используется в качестве
адреса дисковой страницы, на которой будет храниться данная запись. Более
популярный альтернативный метод основан на хэшировании с применением остатка
от деления. В этом методе используется функция MOD, которой передается
значение поля. Функция делит полученное значение на некоторое заранее заданное
целое число, после чего остаток от деления используется в качестве адреса на
диске.
Недостатком большинства хэш-функций является то, что они не гарантируют
получение уникального адреса, поскольку количество возможных значений поля
хэширования может быть гораздо больше количества адресов, доступных для записи.
Каждый вычисленный хэш-функцией адрес соответствует некоторой странице, или
сегменту (bucket), с несколькими ячейками (слотами), предназначенными для
нескольких записей. В пределах одного сегмента записи размещаются в слотах в
порядке поступления. Тот случай, когда один и тот же адрес генерируется для двух
или более записей, называется конфликтом (collision), a подобные записи —
синонимами. В этой ситуации новую запись необходимо вставить в другую позицию,
поскольку место с вычисленным для нее хэш-адресом уже занято. Разрешение
конфликтов усложняет сопровождение хэшированных файлов и снижает общую
производительность их работы.
Для разрешения конфликтов можно использовать следующие методы:
открытая адресация;
несвязанная область переполнения;
связанная область переполнения;
многократное хэширование.
Открытая адресация
При возникновении конфликта система выполняет линейный поиск первого
доступного слота для вставки в него новой записи. После неудачного поиска
пустого слота в последнем сегменте поиск продолжается с первого сегмента. При
выборке записи используется тот же метод, который применялся при сохранении
записи, за исключением того, что запись в данном случае рассматривается как не
существующая, если до обнаружения искомой записи будет обнаружен пустой слот.
На первый взгляд может показаться, что этот подход не дает большого выигрыша
в производительности. Однако при более внимательном анализе обнаруживается, что
при использовании открытой адресации конфликты, устраненные с помощью первого
свободного слота, могут вызвать дополнительные конфликты с записями, которые
будут иметь хэш-значение, равное адресу этого прежде свободного слота. Таким
образом, количество конфликтов будет возрастать, а производительность — падать.
С другой стороны, если количество конфликтов удастся свести к минимуму, то
линейный поиск в малой области переполнения будет выполняться достаточно быстро.
Связанная область переполнения
Как и в предыдущем методе, в этом методе для разрешения конфликтов с
записями, которые не могут быть размещены в слоте с их адресом хэширования,
используется область переполнения. Однако в данном методе каждому сегменту
выделяется дополнительное поле, которое иногда называется указателем синонима.
Оно определяет наличие конфликта и указывает страницу в области переполнения,
использованную для его разрешения. Если указатель равен нулю, то никаких
конфликтов нет.
Для более быстрого доступа к записи переполнения можно использовать указатель
синонима, который указывает на адрес слота внутри области переполнения, а не на
адрес сегмента. Записи внутри области переполнения также имеют указатели
синонима, которые содержат в области переполнения адрес следующего синонима для
такого же адреса, поэтому все синонимы одного адреса могут быть извлечены с
помощью цепочки указателей.
Многократное хэширование
Альтернативный способ разрешения конфликтов заключается в применении второй
хэш-функции, если первая функция приводит к возникновению конфликта. Цель второй
хэш-функции заключается в получении нового адреса хэширования, который позволил
бы избежать конфликта. Вторая хэш-функция обычно используется для размещения
записей в области переполнения.
При работе с хэшированными файлами запись может быть достаточно эффективно
найдена с помощью первой хэш-функции, а в случае возникновения конфликта для
определения ее адреса следует применить один из перечисленных выше способов.
Прежде чем обновить хэшированную запись, ее следует найти. Если обновляется
значение поля, которое не является хэш-ключом, то такое обновление может быть
выполнено достаточно просто, причем обновленная запись сохраняется в том же
слоге. Но если обновляется значение хэш-ключа, то до размещения обновленной
записи потребуется вычислить хэш-функцию. Если при этом будет получено новое
хэш-значение, то исходная запись должна быть удалена из текущего слота и
сохранена по вновь вычисленному адресу.
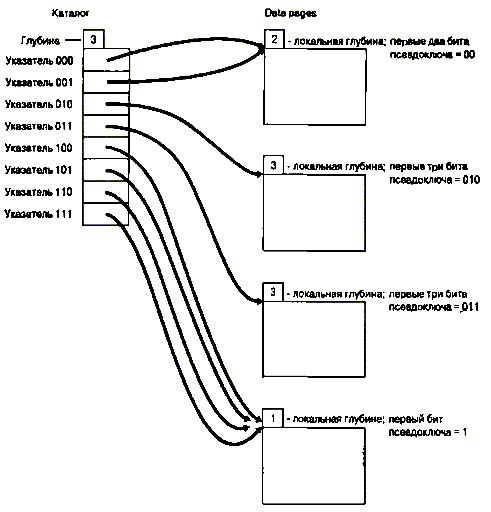
Динамическое хэширование
Динамическое хэширование
Перечисленные выше методы хэширования являются статическими, в том смысле,
что пространство хэш-адресов задается непосредственно при создании файла.
Считается, что пространство файла уже насыщено, когда оно уже почти полностью
заполнено и администратор базы данных вынужден реорганизовать его хэш-структуру.
Для этого может потребоваться создать новый файл большего размера, выбрать новую
хэш-функцию и переписать старый файл во вновь отведенное место. В альтернативном
подходе, получившем название динамического хэширования, допускается динамическое
изменение размера файла с целью его постоянной модификации в соответствии с
уменьшением или увеличением размеров базы данных.
Основной принцип динамического хэширования заключается в обработке числа,
выработанного хэш-функцией в виде последовательности битов, и распределении
записей по сегментам на основе так называемой прогрессирующей оцифровки
(progressive digitization) этой последовательности. Динамическая хэш-функция
вырабатывает значения в широком диапазоне, а именно b-битовые двоичные целые
числа, где b обычно равно 32.
Ограничения, свойственные методу хэширования
Использование метода хэширования для извлечения записей основано на полностью
известном значении хэш-поля. Поэтому, как правило, хэширование не подходит для
операций извлечения данных по заданному образцу или диапазону значений. Более
того, хэширование не подходит для поиска и извлечения данных по любому другому
полю, отличному от поля хэширования.
Знаете ли Вы, что такое "Большой Взрыв"? Согласно рупору релятивистской идеологии Википедии "Большой взрыв (англ. Big Bang) - это космологическая модель, описывающая раннее развитие Вселенной, а именно - начало расширения Вселенной, перед которым Вселенная находилась в сингулярном состоянии. Обычно сейчас автоматически сочетают теорию Большого взрыва и модель горячей Вселенной, но эти концепции независимы и исторически существовало также представление о холодной начальной Вселенной вблизи Большого взрыва. Именно сочетание теории Большого взрыва с теорией горячей Вселенной, подкрепляемое существованием реликтового излучения..." В этой тираде количество нонсенсов (бессмыслиц) больше, чем количество предложений, иначе просто трудно запутать сознание обывателя до такой степени, чтобы он поверил в эту ахинею. На самом деле взорваться что-либо может только в уже имеющемся пространстве. Без этого никакого взрыва в принципе быть не может, так как "взрыв" - понятие, применимое только внутри уже имеющегося пространства. А раз так, то есть, если пространство вселенной уже было до БВ, то БВ не может быть началом Вселенной в принципе. Это во-первых. Во-вторых, Вселенная - это не обычный конечный объект с границами, это сама бесконечность во времени и пространстве. У нее нет начала и конца, а также пространственных границ уже по ее определению: она есть всё (потому и называется Вселенной). В третьих, фраза "представление о холодной начальной Вселенной вблизи Большого взрыва" тоже есть сплошной нонсенс. Что могло быть "вблизи Большого взрыва", если самой Вселенной там еще не было? Подробнее читайте в FAQ по эфирной физике.