Мы рассмотрели
отдельные аспекты работы СУБД. Теперь попробуем кратко обобщить все, что узнали,
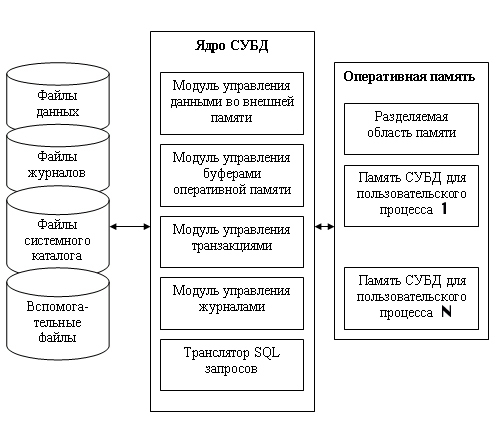
и построим некоторую условную обобщенную структуру СУБД. На рис. 14.1 нзрбражена
такая структура. Здесь условно показано, что СУБД должна управлять внешней памятью,
в котором расположены файлы с данными, файлы журналов и файлы системного каталога.
С другой
стороны, СУБД управляет и оперативной памятью, в которой располагаются буфера
с данными, буфера журналов, данные системного каталога, которые необходимы для
поддержки целостности и проверки привилегии пользователей. Кроме того, и оперативной
памяти во время работы СУБД располагается информация, которая соответствует
текущему состоянию обработки запросов, там хранятся планы выполнения скомпилированных
запросов и т. д.
Модуль управления
внешней памятью обеспечивает создание необходимых структур внешней памяти как
для хранения данных, непосредственно входящих в БД, так и для служебных целей,
например для ускорения доступа к данным в некоторых случаях (обычно для этого
используются индексы). Как мы рассматривали ранее, в некоторых реализациях СУБД
активно используются возможности существующих файловых систем, в других работа
производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в
развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД
файловую систему, и если использует, то как организованы файлы. В частности,
СУБД поддерживает собственную систему именования объектов БД.
Модуль управления
буферами оперативной памяти предназначен для решения задач эффективной буферизации,
которая используется практически для выполнения всех остальных функций СУБД.
Условно оперативную
память, которой управляет СУБД, можно представить как совокупность буферов,
хранящих страницы данных, буферов, хранящих страницы журналов транзакций и область
совместно используемого пула (см. рис. 14.2). Последняя область содержит фрагменты
системного каталога, которые необходимо постоянно держать в оперативной памяти,
чтобы ускорить обработку запросов пользователей, и область операторов SQL с
курсорами. Фрагменты системного
каталога в некоторых реализациях называются словарем данных. В стандарте SQL2
определены общие требования к системному каталогу.
Рис.
14.1. Обобщенная структура СУБД
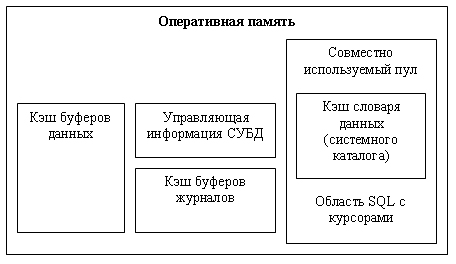
Рис.
14.2. Оперативная память, управляемая СУБД
Системный
каталог в реляционных СУБД представляет собой совокупность специальных таблиц,
которыми владеет сама СУБД. Таблицы системного каталога создаются автоматически
при установке программного обеспечения сервера БД. Все системные таблицы обычно
объединяются некоторым специальным «системным идентификатором пользователя».
При обработке SQL-запросов СУБД постоянно обращается к этим таблицам. В некоторых
СУБД разрешен ограниченный доступ пользователей к ряду системных таблиц, однако
только в режиме чтения. Только системный администратор имеет некоторые права
на модификацию данных в некоторых системных таблицах.
Каждая таблица
системного каталога содержит информацию об отдельных структурных элементах БД.
В стандарте SQL2 определены следующие системные таблицы:
Таблица
14.1. Содержание системного каталога по стандарту SQL2
|
Системная таблица |
Содержание |
|
USERS - |
Одна строка
для каждого идентификатора пользователя с зашифрованным паролем |
|
SCHEMA |
Одна строка
для каждой информационной схемы |
|
DATA_TYPE_DESCRIPTION |
Одна строка
для каждого домена или столбца, имеющего определенный тип данных |
|
DOMAINS |
Одна строка
для каждого домена |
|
DOMAIN_CONSTRA1NS |
Одна строка
для каждого ограничивающего условия, наложенного на домен |
|
TABLES |
Одна строка
для каждой таблицы с указанием имени, владельца, количества столбцов,
размеров данных столбцов, и т. д. |
|
VIEWS |
Одна строка
для каждого представления с указанием имени, имени владельца, запроса,
который определяет представление и т. д. |
|
COLUMNS |
Одна строка
для каждого столбца с указанием имени столбца, имени таблицы или представления,
к которому он относится, типа данных столбца, его размера, допустимости
или недопустимости неопределенных значений (NULL ) и т. д. |
|
VIEW_TABLE_USAGE |
Одна стр.ока
для каждой таблицы, на которую имеется ссылка в каком-либо представлении
(если представление многотабличное, то для каждой таблицы заносится
одна строка) |
|
VIEW_COLUMN_USAGE |
Одна строка
для каждого столбца, на который имеется ссылка в некотором представлении |
|
TABLE_CONSTRAINS |
Одна строка
для каждого условия ограничения, заданного в каком-либо определении
таблицы |
|
KEY_COLUMN_USAGE |
Одна строка
для каждого столбца, на который наложено условие уникальности и который
присутствует в определении первичного или внешнего ключа (если первичный
или внешний ключ заданы несколькими столбцами, то для каждого из них
задается отдельная строка) |
|
REFERENTIAL_CONSTRAINTS |
Одна строка
для каждого внешнего ключа, присутствующего в определении таблицы |
|
CHECK_ CONSTRAINTS |
Одна строка
для каждого условия проверки, заданного в определении таблицы |
|
CHECK_TABLE_USAGE |
Одна строка
для каждой таблицы, на которую имеется ссылка в условиях проверки,
ограничительном условии для домена или всей таблицы |
|
Системная таблица |
Содержание |
|
CHECK_COLUMN_USAGE |
Одна строка
для каждого столбца, на который имеется ссылка в условии проверки,
ограничительном условии для домена или ином ограничительном условии |
|
ASSERTIONS |
Одна строка
для каждого декларативного утверждения целостности |
|
TABLE_PRIVILEGES |
Одна строка
для каждой привилегии, предоставленной на какую-либо таблицу |
|
COLUMN_PRIVILEGES |
Одна строка
для каждой привилегии, предоставленной на какой-либо столбец |
|
USAGE_PRIVILEGES |
Одна строка
для каждой привилегии, предоставленной на какой-либо домен, набор
символов и т. д. |
|
CHARACTER_SETS |
Одна строка
для каждого заданного набора символов |
|
COLLATIONS |
Одна строка
для заданной последовательности |
|
TRANSLATIONS |
Одна строка
для каждого заданного преобразования |
|
SQL_LAGUAGES |
Одна строка
для каждого заданного языка, поддерживаемого СУБД |
Стандарт
SQL2 не требует, чтобы СУБД в точности поддерживала требуемый набор системных
таблиц. Стандарт ограничивается требованием того, чтобы для рядовых пользователей
были доступны некоторые специальные представления системного каталога. Поэтому
системные таблицы организованы по-разному в разных СУБД и имеют различные имена,
но большинство СУБД предо-ставля-ют ряд основных представлений рядовым пользователям.
Кроме того,
системный каталог отражает некоторые дополнительные возможности, предоставляемые
конкретными СУБД. Так, например, в системном каталоге Oracle присутствуют таблицы
синонимов.
Область SQL
содержит данные связывания, временные буферы, дерево разбора и план выполнения
для каждого оператора SQL, переданного серверу БД. Область разделяемого пула
ограничена в размере, поэтому, возможно, в ней не могут поместиться все операторы
SQL, которые были выполнены с момента запуска сервера БД. Ядро СУБД удаляет
старые, давно не используемые операторы, освобождая память под новые операторы
SQL. Если пользователь выполняет запрос, план выполнения которого уже хранится
в разделяемом пуле, то СУБД не производит его разбор и построение нового плана,
она сразу запускает его на выполнение, возможно, с новыми параметрами.
Модуль управления
транзакциями поддерживает механизмы фиксации и отката транзакций, он связан
с модулем управления буферами оперативной памяти и обеспечивает сохранение всей
информации, которая требуется после мягких или жестких сбоев в системе. Кроме
того, модуль управления транзакциями содержит специальный механизм поиска тупиковых
ситуаций или взаимоблокировок и реализует одну из принятых стратегий принудительного
завершения транзакций для развязывания тупиковых ситуаций.
Особое внимание
надо обратить на модуль поддержки SQL. Это практически транслятор с языка SQL
и блок оптимизации запросов.
В общем,
оптимизация запросов может быть разделена на синтаксическую и семантическую.
Методы синтаксической оптимизации запросов связаны с построением некоторой эквивалентной формы, называемой
иногда канонической формой, которая требует меньших затрат на выполнение запроса,
но дает результат, полностью эквивалентный исходному запросу.
К методам,
используемым при синтаксической оптимизации запросов, относятся следующие:
Канонические представления
могут быть различными для предикатов разных типов. Если предикат включает
только одно имя поля, то его каноническое представление может, например,
иметь вид имя поля ОС константное арифметическое выражение (эта форма предиката
— простой предикат селекции — очень полезна при выполнении следующего этапа
оптимизации). Если начальное представление предиката имеет вид
(n+12)*R.B OC 100
здесь n — переменная
языка, R.B — имя столбца В отношения R, ОС - допустимая операция сравнения.
Каноническим представлением
такого предиката может быть
R.В ОС 100/(n+12)
В этом случае мы один
раз для заданного значения переменной п вычисляем выражение в скобках и
правую часть операции сравнения 100/(n +12), а потом каждую строку можем
сравнивать с полученным значением.
Если предикат включает
в точности два имени поля разных отношений (или двух разных вхождений одного
отношения), то его каноническое представление может иметь вид имя поля ОС
арифметическое выражение, где арифметическое выражение в правой части включает
только константы и второе имя ноля (это тоже форма, полезная дпя выполнения
следующего шага оптимизации, —
предикат соединения;
особенно важен случай эквисоединения, когда ОС — это равенство). Если в
начальном представлении предикат имеет вид:
12*(Rl.A)-n*(R2.B) ОС
m,
то его каноническое
представление:
R1.A ОС (m+n*(R2.B)/12
В общем случае желательно
приведение предиката к каноническому представлению вида арифметическое выражение
ОС константное арифметическое выражение, где выражения правой и левой частей
также приведены к каноническому представлению. В дальнейшем можно произвести
поиск общих арифметических выражений в разных предикатах запроса. Это оправдано,
поскольку при выполнении запроса вычисление арифметических выражений будет
производиться при выборке каждого очередного кортежа, то есть потенциально
большое число раз.
При приведении предикатов
к каноническому представлению можно вычислять константные выражения и избавляться
от логических отрицаний.
Еще один класс логических
преобразований связан с приведением к каноническому виду логического выражения,
задающего условие выборки запроса. Как правило, используются либо дизъюнктивная,
либо конъюнктивная нормальные формы. Выбор канонической формы зависит от
общей организации оптимизатора.
При приведении логического
условия к каноническому представлению можно производить поиск общих предикатов
(они могут существовать изначально, могут появиться после приведения предикатов
к каноническому виду или в процессе нормализации логического условия) и
упрощать логическое выражение за счет, например, выявления конъюнкции взаимно
противоречащих предикатов.
Например, имеем следующий
запрос:
R1 NATURAL JOIN R2
WHERE R1.A ОС a AND
R2.B С b
Здесь а и b некоторые константы, которые ограничивают значение атрибутов отношений R1 и R2.
Если мы его рассмотрим в терминах реляционной алгебры, то это естественное соединение отношений R1 и R2, в которых заданы внутренние ограничения на кортежи каждого отношения.
Для уменьшения числа соединяемых кортежей резоннее сначала произвести операции выборки на каждом отношении и только после этого перейти в операции естественного соединения.
предикат соединения; особенно важен случай зквисоединения, когда ОС — это равенство). Если в начальном представлении предикат имеет вид:
12*(Rl.A)-n*(R2.B) ОС m,
то его каноническое представление:
R1.A ОС (m+n*(R2.B)/12
В общем случае желательно приведение предиката к каноническому представлению вида арифметическое выражение ОС константное арифметическое выражение, где выражения правой и левой частей также приведены к каноническому представлению. В дальнейшем можно произвести поиск общих арифметических выражений в разных предикатах запроса. Это оправдано, поскольку при выполнении запроса вычисление арифметических выражений будет производиться при выборке каждого очередного кортежа, то есть потенциально большое число раз.
При приведении предикатов к каноническому представлению можно вычислять константные выражения и избавляться от логических отрицаний.
Еще один класс логических преобразовании связан с приведением к каноническому виду логического выражения, задающего условие выборки запроса. Как правило, используются либо дизъюнктивная, либо конъюнктивная нормальные формы. Выбор канонической формы зависит от общей организации оптимизатора.
При приведении логического условия к каноническому представлению можно производить поиск общих предикатов (они могут существовать изначально, могут появиться после приведения предикатов к каноническому виду или в процессе нормализации логического условия) и упрощать логическое выражение за счет, например, выявления конъюнкции взаимно противоречащих предикатов.
Например, имеем следующий
запрос:
Rl NATURAL JOIN R2 WHERE
R1.A ОС a AND R2.B С b
Здесь а и b некоторые
константы, которые ограничивают значение атрибутов отношений R1 и R2.
Если мы его рассмотрим
в терминах реляционной алгебры, то это естественное соединение отношений
R1 и R2, в которых заданы внутренние ограничения на кортежи каждого отношения.
Для уменьшения числа
соединяемых кортежей резоннее сначала произвести операции выборки на каждом
отношении и только после этого перейти в операции естественного соединения.
Поэтому данный запрос
будет эквивалентен следующей последовательности операций реляционной алгебры:
R3 =.R1[R1.A ОС а] R4
= R2[R2.B С b] R5 = R3*[ ]*R4
Хотя немногие реляционные
системы имеют языки запросов, основанные в чистом виде на реляционной алгебре,
правила преобразований алгебраических выражений могут быть полезны и в других
случаях. Довольно часто реляционная алгебра используется в качестве основы
внутреннего представления запроса. Естественно, что после этого можно выполнять
и алгебраические преобразования.
В частности, существуют
подходы, связанные с преобразованием запросов на языке SQL к алгебраической
форме. Особенно важно то, что реляционная алгебра более проста, чем язык
SQL. Преобразование запроса к алгебраической форме упрощает дальнейшие действия
оптимизатора по выборке оптимальных планов. Вообще говоря, развитый оптимизатор
запросов системы, ориентированной на SQL, должен выявить все возможные планы
выполнения любого запроса, но «пространство поиска» этих планов
в общем случае очень велико; в каждом конкретном оптимизаторе используются
свои эвристики для сокращения пространства поиска. Некоторые, возможно,
наиболее оптимальные планы никогда не будут рассматриваться. Разумное преобразование
запроса на SQL к алгебраическому представлению сокращает пространство поиска
планов выполнения запроса с гарантией того, что оптимальные планы потеряны
не будут.
Каноническим представлением
запроса на п отношениях называется запрос, содержащий n-1 предикат соединения
и не содержащий предикатов с вложенными подзапросами. Фактически каноническая
форма — это алгебраическое представление запроса.
Например, запрос с
вложенным подзапросом:
(SELECT Rl.A
FROM Rl
WHERE Rl.B IN
(SELECT R2.B FROM R2 WHERE Rl.C = R2.D)
)
эквивалентен
(SELECT Rl.A
FROM Rl. R2
WHERE Rl.A = R2.B AND Rl.C = R2.D)
Второй запрос:
(SELECT Rl.A FROM Rl WHERE Rl.K =
(SELECT AVG (R2.B) FROM R2 WHERE Rl.C = R2.D)
или
(SELECT Rl.A FROM Rl. R3
WHERE Rl.C = R3.D AND Rl.K = R3.L)
R3 = SELECT R2.D, L AVG (R2.B)
FROM R2
GROUP BY R2.D
При использовании
подобного подхода в оптимизаторе запросов не обязательно производить формальные
преобразования запросов. Оптимизатор должен в большей степени использовать семантику
обрабатываемого запроса, а каким образом она будет распознаваться — это вопрос
техники.
Заметим,
что в кратко описанном нами подходе имеются некоторые тонкие семантические некорректности.
Известны исправленные методы, но они слишком сложны технически, чтобы рассматривать
их в данном пособии.
Рассмотренные ранее методы никак не связаны с семантикой конкретной БД, они применимы к любой
БД, вне зависимости от ее конкретного содержания. Семантические методы оптимизации
основаны как раз на учете семантики конкретной БД. Таких методов в различных
реализациях может быть множество, мы с вами коснемся лишь некоторых из них:
После оптимизации
запрос имеет непроцедурный вид, то есть в нем не определен жесткий порядок выполнения
элементарных операций над исходными объектами. На следующем этане строятся все
возможные планы выполнения запросов и для каждого из них производятся стоимостные
оценки. Оценка планов выполнения запроса основана на анализе текущих объемов
данных, хранящихся в отношениях БД, и на статистическом анализе хранимой информации.
В большинстве СУБД ведется учет диапазона значений отдельного столбца с указанием
процентного содержания для каждого диапазона. Поэтому при построении плана запроса
СУБД может оценить объем промежуточных отношений и построить план таким образом,
чтобы на наиболее ранних этапах выполнения запроса минимизировать количество
строк, включаемых в промежуточные отношения.
Кроме ядра
СУБД каждый поставщик обеспечивает специальные инструментальные средства, облегчающие
администрирование БД и разработку новых проектов БД и пользовательских приложений
для данного сервера. В последнее время практически все утилиты и инструментальные
средства имеют развитый графический интерфейс.
Для разработки приложений пользователи могут применять не только инструментальные средства, поставляемые вместе с сервером БД, но и средства сторонних поставщиков. Так, в нашей стране получила большую популярность инструментальная среда Delphi, которая позволяет разрабатывать приложения для различных серверов БД. За рубежом более популярными являются инструментальные системы быстрой разработки приложений RAD (Rapid Application Development) продукты компании Advanced Information System, инструментальной среды Power Builder фирмы Power Soft, системы SQL Windows фирмы Gtipta (Taxedo).
|
|
