Архитектура базы данных. Физическая и логическая независимость
Терминология
в СУБД, да и сами термины «база данных» и «банк данных»
частично заимствованы из финансовой деятельности. Это заимствование — не случайно
и объясняется тем, что работа с информацией и работа с денежными массами во
многом схожи, поскольку и там и там отсутствует персонификация объекта обработки:
две банкноты достоинством в сто рублей столь же неотличимы и взаимозаменяемы,
как два одинаковых байта (естественно, за исключением серийных номеров). Вы
можете положить деньги на некоторый счет и предоставить возможность вашим родственникам
или коллегам использовать их для иных целей. Вы можете поручить банку оплачивать
ваши расходы с вашего счета или получить их наличными в другом банке, и это
будут уже другие денежные купюры, но их ценность будет эквивалентна той, которую
вы имели, когда клали их на ваш счет.
В процессе
научных исследований, посвященных тому, как именно должна быть устроена СУБД,
предлагались различные способы реализации. Самым жизнеспособным из них оказалась
предложенная американским комитетом по стандартизации ANSI (American National
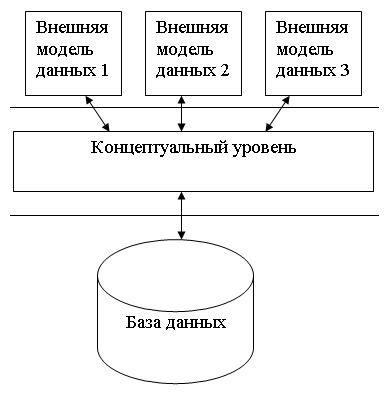
Standards Institute) трехуровневая система организации БД, изображенная на рис.
2.1:
Рис. 2.1. Трехуровневая модель системы управления базой данных, предложенная ANSI
Уровень внешних моделей
-
самый верхний уровень, где каждая модель имеет свое «видение»
данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое
приложение видит и обрабатывает только те данные, которые необходимы именно
этому приложению. Например, система распределения работ использует сведения
о квалификации сотрудника, но ее не
интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот,
именно эти сведения используются в подсистеме отдела кадров.
Концептуальный уровень
-
центральное управляющее звено, здесь база данных представлена в наиболее
общем виде, который объединяет данные, используемые всеми приложениями, работающими
с данной базой данных. Фактически концептуальный уровень отражает обобщенную
модель предметной области (объектов реального мира), для которой создавалась
база данных. Как любая модель, концептуальная модель отражает только существенные,
с точки зрения обработки, особенности объектов реального мира.
Физический уровень
-
собственно данные, расположенные в файлах или в страничных структурах, расположенных
на внешних носителях информации.
Эта архитектура
позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями
2 и 3) независимость при работе с данными. Логическая независимость предполагает
возможность изменения одного приложения без корректировки других приложений,
работающих с этой же базой данных. Физическая независимость предполагает возможность
переноса хранимой информации с одних носителей на другие при сохранении работоспособности
всех приложений, работающих с данной базой данных. Это именно то, чего не хватало
при использовании файловых систем.
Выделение
концептуального уровня позволило разработать аппарат централизованного управления
базой данных.
Процесс прохождения пользовательского запроса
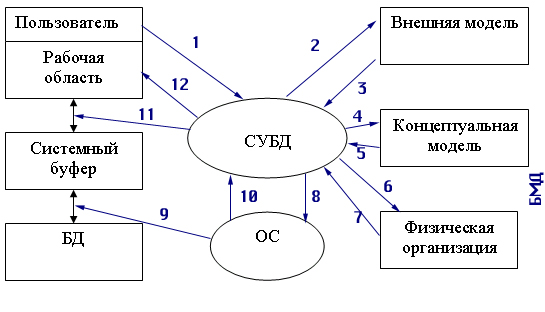
Рисунок 2.2
иллюстрирует взаимодействие пользователя, СУБД и ОС при обработке запроса на
получение данных. Цифрами помечена последовательность взаимодействий:
Рис.
2.2. Схема прохождения запроса к БД
Пользователь посылает
СУБД запрос на получение данных из БД.
Анализ прав пользователя
и внешней модели данных, соответствующей данному пользователю, подтверждает
или запрещает доступ данного пользователя к запрошенным данным.
В случае запрета на
доступ к данным СУБД сообщает пользователю об этом (стрелка 12) и прекращает
дальнейший процесс обработки данных, в противном случае СУБД определяет часть
концептуальной модели, которая затрагивается запросом пользователя.
СУБД получает информацию
о запрошенной части концептуальной модели.
СУБД запрашивает информацию
о местоположении данных на физическом уровне (файлы или физические адреса).
В СУБД возвращается
информация о местоположении данных в терминах операционной системы.
СУБД вежливо просит
операционную систему предоставить необходимые данные, используя средства операционной
системы.
Операционная система
осуществляет перекачку информации из устройств хранения и пересылает ее в
системный буфер.
Операционная система
оповещает СУБД об окончании пересылки.
СУБД выбирает из доставленной
информации, находящейся в системном буфере, только то, что нужно пользователю,
и пересылает эти данные в рабочую область пользователя.
БМД — это
База Метаданных, именно здесь и хранится вся информация об используемых
структурах данных, логической организации данных, правах доступа пользователей
и, наконец, физическом расположении данных. Для управления БМД существует специальное
программное обеспечение администрирования баз данных, которое предназначено
для корректного использования единого информационного пространства многими пользователями.
Всегда ли
запрос проходит полный цикл? Конечно, нет. СУБД обладает достаточно развитым
интеллектом, который позволяет ей не повторять бессмысленных действий. И поэтому,
например, если этот же пользователь повторно обратится к СУБД с новым запросом,
то для него уже не будут проверяться внешняя модель и права доступа, а если
дальнейший анализ запроса покажет, что данные могут находиться в системном буфере,
то СУБД осуществит только 11 и 12 шаги в обработке запроса.
Разумеется,
механизм прохождения запроса в реальных СУБД гораздо сложнее, но и эта упрощенная
схема показывает, насколько серьезными и сложными должны быть механизмы обработки
запросов, поддерживаемые реальными СУБД.
Пользователи банков данных
Как любой
программно-организационно-технический комплекс, банк данных существует во времени
и в пространстве. Он имеет определенные стадии своего развития:
Проектирование.
Реализация.
Эксплуатация;
Модернизация и развитие.
Полная реорганизация.
На каждом
этапе своего существования с банком данных связаны разные категории пользователей.
Определим
основные категории пользователей и их роль в функционировании банка данных:
Конечные пользователи
-
Это основная категория пользователей, в интересах которых и создается
банк данных. В зависимости от особенностей создаваемого банка данных круг
его конечных пользователей может существенно различаться. Это могут быть случайные
пользователи, обращающиеся к БД время от времени за получением некоторой информации,
а могут быть регулярные пользователи. В качестве случайных пользователей могут
рассматриваться, например, возможные клиенты вашей фирмы, просматривающие
каталог вашей продукции или услуг с обобщенным или подробным описанием того
и другого. Регулярными пользователями могут быть ваши сотрудники, работающие
со специально разработанными для них программами, которые обеспечивают автоматизацию
их деятельности при выполнении своих должностных обязанностей. Например, менеджер,
планирующий работу сервисного отдела компьютерной фирмы, имеет в своем распоряжении
программу, которая помогает ему планировать.и распределять текущие заказы,
контролировать ход их выполнения, заказывать на складе необходимые комплектующие
для новых заказов. Главный принцип состоит в том, что от конечных пользователей
не должно требоваться каких-либо специальных знаний в области вычислительной
техники и языковых средств.
Администраторы банка данных
-
Это группа пользователей, которая на начальной стадии разработки
банка данных отвечает за его оптимальную организацию с точки зрения одновременной
работы множества конечных пользователей, на стадии эксплуатации отвечает за
корректность работы данного банка информации в многопользовательском режиме.
На стадии развития и реорганизации эта группа пользователей отвечает за возможность
корректной реорганизации банка без изменения или прекращения его текущей эксплуатации.
Разработчики и администраторы приложений
-
Это группа пользователей, которая функционирует
во время проектирования, создания и реорганизации банка данных. Администраторы
приложений координируют работу разработчиков при разработке конкретного приложения
или группы приложений, объединенных в функциональную подсистему. Разработчики
конкретных приложений работают с той частью информации из базы данных, которая
требуется для конкретного приложения.
Не в каждом
банке данных могут быть выделены все типы пользователей. Мы уже знаем, что при
разработке информационных систем с использованием настольных
СУБД администратор банка данных, администратор приложений и разработчик часто
существовали в одном лице. Однако при построении современных сложных корпоративных
баз данных, которые используются для автоматизации всех или большей части бизнес-процессов
в крупной фирме или корпорации, могут существовать и группы администраторов
приложений, и отделы разработчиков. Наиболее сложные обязанности возложены на
группу администратора БД.
Рассмотрим
их более подробно.
В составе
группы администратора БД должны быть:
системные аналитики;
проектировщики структур данных и внешнего по отношению к банку данных информационного обеспечения;
проектировщики технологических процессов обработки данных;
системные программисты;
прикладные программисты;
специалисты по техническому обслуживанию;
операторы.
Если речь
идет о коммерческом банке данных, то важную роль здесь играют специалисты по
маркетингу.
Основные функции группы администратора БД
Анализ предметной
области: описание предметной области, выявление ограничений целостности, определение
статуса (доступности, секретности) информации, определение потребностей пользователей,
определение соответствия «данные—пользователь», определение объемно-временных
характеристик обработки данных.
Проектирование структуры
БД: определение состава и структуры файлов БД и связей между ними, выбор
методов упорядочения данных и методов доступа к информации, описание БД на
языке описания данных (ЯОД).
Задание ограничений
целостности при описании структуры БД и процедур обработки БД:
определение динамических
ограничений целостности, присущих предметной области в процессе изменения
информации, хранящейся в БД;
определение ограничений
целостности, вызванных структурой БД;
разработка процедур
обеспечения целостности БД при вводе и корректировке данных;
определение ограничений
целостности при параллельной работе пользователей в многопользовательском
режиме.
Первоначальная
загрузка и ведение БД:
разработка технологии
первоначальной загрузки БД, которая будет отличаться от процедуры модификации
и дополнения данными при штатном использовании базы данных;
разработка технологии
проверки соответствия введенных данных реальному состоянию предметной
области. База данных моделирует реальные объекты некоторой предметной
области и взаимосвязи между ними, и на момент начала штатной эксплуатации
эта модель должна полностью соответствовать состоянию объектов предметной
области на данный момент времени;
в соответствии
с разработанной технологией первоначальной загрузки может понадобиться
проектирование системы первоначального ввода данных.
Защита данных:
определение системы
паролей, принципов регистрации пользователей, создание групп пользователей,
обладающих одинаковыми правами доступа к данным;
разработка принципов
защиты конкретных данных и объектов проектирования; разработка специализированных
методов кодирования информации при ее циркуляции в локальной и глобальной
информационных сетях;
разработка средств
фиксации доступа к данным и попыток нарушения системы защиты;
тестирование системы
защиты;
исследование случаев
нарушения системы защиты и развитие динамических методов защиты информации
в БД.
Обеспечение восстановления
БД:
разработка организационных
средств архивирования и принципов восстановления БД;
разработка дополнительных
программных средств и технологических процессов восстановления БД после
сбоев.
Анализ обращений
пользователей БД: сбор статистики по характеру запросов, по времени их
выполнения, по требуемым выходным документам
Анализ эффективности
функционирования БД:
анализ показателей
функционирования БД;
планирование реструктуризации
(изменение структуры) БД и реорганизации БнД.
Работа с конечными
пользователями:
сбор информации
об изменении предметной области;
сбор информации
об оценке работы БД;
обучение пользователей,
консультирование пользователей;
разработка необходимой
методической и учебной документации по работе конечных пользователей.
Подготовка и поддержание
системных средств:
анализ существующих
на рынке программных средств и анализ возможности и необходимости их использования
в рамках БД;
разработка требуемых
организационных и программно-технических мероприятий по развитию БД;
проверка работоспособности
закупаемых программных средств перед подключением их к БД;
курирование подключения
новых программных средств к БД. 11. Организационно-методическая работа по
проектированию БД:
выбор или создание
методики проектирования БД;
определение целей
и направления развития системы в целом;
планирование этапов
развития БД;
разработка общих
словарей-справочников проекта БД и концептуальной модели;
стыковка внешних
моделей разрабатываемых приложений;
курирование подключения
нового приложения к действующей БД;
обеспечение возможности
комплексной отладки множества приложений, взаимодействующих с одной БД.
Классификация моделей данных
Одними из
основополагающих в концепции баз данных являются обобщенные категории «данные»
и «модель данных».
Понятие «данные»
в концепции баз данных — это набор конкретных значений, параметров, характеризующих
объект, условие, ситуацию или любые другие факторы. Примеры данных: Петров Николай
Степанович, $30 и т. д. Данные не обладают определенной структурой, данные становятся
информацией тогда, когда пользователь задает им определенную структуру, то есть
осознает их смысловое содержание. Поэтому центральным понятием в области баз
данных является понятие модели. Не существует однозначного определения этого
термина, у разных авторов эта абстракция определяется с некоторыми различиями,
но тем не менее можно выделить нечто общее в этих определениях.
Модель данных
-
это некоторая абстракция, которая, будучи приложима к конкретным
данным, позволяет пользователям и разработчикам трактовать их уже как информацию,
то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
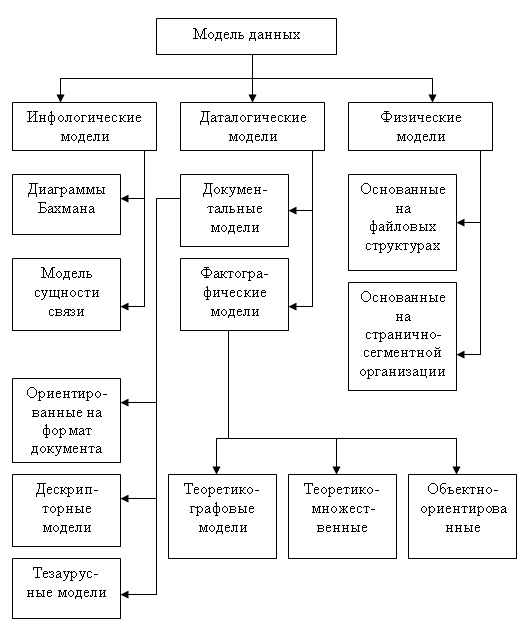
На рис. 2.3
представлена классификация моделей данных.
В соответствии
с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием
модели данных по отношению к каждому уровню. И действительно, физическая модель
данных оперирует категориями, касающимися организации внешней памяти и структур
хранения, используемых в данной операционной среде. В настоящий момент в качестве
физических моделей используются различные методы размещения данных, основанные
на файловых структурах: это организация файлов прямого и последовательного доступа,
индексных файлов и инвертированных файлов, файлов, использующих различные методы
хэширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют
страничную организацию данных. Физические модели
данных, основанные на страничной организации, являются наиболее перспективными.
Рис.
2.3. Классификация моделей данных
Наибольший
интерес вызывают модели данных, используемые на концептуальном уровне. По отношению
к ним внешние модели называются подсхемами и используют те же абстрактные категории,
что и концептуальные модели данных.
Кроме трех
рассмотренных уровней абстракции при проектировании БД существует еще один уровень,
предшествующий им. Модель этого уровня должна выражать информацию о предметной
области в виде, независимом от используемой СУБД. Эти модели называются инфологическими,
или семантическими.
Инфологические модели данных
-
отражают в естественной и удобной для разработчиков
и других пользователей форме информационно-логический уровень абстрагирования,
связанный с фиксацией и описанием объектов предметной области, их свойств и
их взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур
данных в процессе разработки приложения, а дата-логические модели уже
поддерживаются конкретной СУБД.
Документальные модели данных
-
соответствуют представлению о слабоструктурированной информации,
ориентированной в основном на свободные форматы документов, текстов на естественном
языке.
Модели, основанные
на языках разметки документов, связаны прежде всего со стандартным общим языком
разметки — SGML (Standart Generalised Markup Language),
который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен
для создания других языков разметки, он определяет допустимый набор тегов (ссылок),
их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования
тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями,
которые используются программой клиента при разборе документа. Для каждого класса
документов определяется свой набор правил, описывающих грамматику соответствующего
языка разметки. С помощью SGML можно описывать структурированные данные, организовывать
информацию, содержащуюся в документах, представлять эту информацию в некотором
стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался
в основном для описания синтаксиса других языков (наиболее известным из которых
является HTML), и немногие приложения работали с SGML-документами напрямую.
Гораздо более
простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов
документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых
осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены
для управления процессом вывода содержимого документа на экране программы-клиента
и определяют этим самым способ представления документа, но не его структуру.
В качестве элемента гипертекстовой базы данных, описываемой HTML, используется
текстовый файл, который может легко передаваться по сети с использованием протокола
HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное
количество пользователей имеет возможность применять возможности этого языка
для оформления своих документов, безусловно, повлияли на рост популярности HTML
и сделали его сегодня главным механизмом представления информации в Интернете.
Однако HTML
сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными
разработчиками к языкам подобного рода. И ему на смену был предложен новый язык
гипертекстовой разметки, мощный, гибкий и, одновременно с этим, удобный язык
XML. В чем же заключаются его достоинства?
XML (Extensible Markup Language)
-
это язык разметки, описывающий целый класс объектов данных,
называемых XML-документами. Он используется в качестве средства для описания
грамматики других языков и контроля за правильностью составления документов.
То есть сам по себе XML не содержит никаких тегов, предназначенных для разметки,
он просто определяет порядок их создания.
Тезаурусные модели
-
это модели, которые основаны на принципе организации словарей, содержат определенные
языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти
модели эффективно используются в системах-переводчиках, особенно многоязыковых
переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным
моделям.
Дескрипторные модели
-
самые простые из документальных моделей, они широко использовались
на ранних стадиях использования документальных баз данных. В этих моделях каждому
документу соответствовал дескриптор - описатель. Этот дескриптор имел жесткую
структуру и описывал документ в соответствии
с теми характеристиками, которые требуются для работы с документами в разрабатываемой
документальной БД. Например, для БД, содержащей описание патентов, дескриптор
содержал название области, к которой относился патент, номер патента, дату выдачи
патента и еще ряд ключевых параметров, которые заполнялись для каждого патента.
Обработка информации в таких базах данных велась исключительно по дескрипторам,
то есть по тем параметрам, которые характеризовали патент, а не по самому тексту
патента.
Знаете ли Вы, что в 1965 году два американца Пензиас (эмигрант из Германии) и Вильсон заявили, что они открыли излучение космоса. Через несколько лет им дали Нобелевскую премию, как-будто никто не знал работ Э. Регенера, измерившего температуру космического пространства с помощью запуска болометра в стратосферу в 1933 г.? Подробнее читайте в FAQ по эфирной физике.