
Инфологическая модель применяется на втором этапе проектирования БД (алгоритмическом), то есть после словесного описания предметной области, то есть после этапа постановки задачи.
Зачем нужна инфологическая модель и какую пользу она дает проектировщикам? Еще раз хотим напомнить, что процесс проектирования длительный, он требует обсуждений с заказчиком, со специалистами в предметной области. Наконец, при разработке серьезных корпоративных информационных систем проект базы данных является тем фундаментом, на котором строится вся система в целом, и вопрос о возможном кредитовании проекта часто решается экспертами банка на основании именно грамотно сделанного инфологического проекта БД. Следовательно, инфологическая модель должна включать такое формализованное описание предметной
области, которое будет «читабельно» не только для специалистов по базам данных, но и сторонних людей. И это описание должно быть настолько емким, чтобы можно было
оценить глубину и корректность проработки проекта БД, и конечно, как говорилось
раньше, оно не должно быть привязано к конкретной СУБД. Выбор СУБД — это отдельная
задача, для корректного ее решения необходимо иметь проект, который не привязан
ни к какой конкретной СУБД.
Инфологическое проектирование прежде всего связано с попыткой представления семантики, то есть смыслового содержания, предметной области в модели БД.
Реляционная модель данных в силу своей простоты и лаконичности не позволяет отобразить семантику, то есть смысл предметной области оставется за рамками реляционной модели. Ранние теоретико-графовые модели в большей степени, чем реляционная модель, отображали семантику предметной области. Они в явном виде определяли иерархические связи между объектами предметной
области.
Проблема представления семантики давно интересовала разработчиков, и в семидесятых годах было предложено несколько моделей данных, названных семантическими моделями. К ним можно отнести модель «сущность—связь», предложенную Ченом (Chen) в 1976 году, семантическую модель данных, предложенную Хаммером (Hammer) и Мак-Леоном (McLeon) в 1981 году, функциональную модель данных Шипмана (Shipman), также созданную в 1981 году, и ряд других моделей. У всех моделей были свои положительные и отрицательные стороны, но испытание временем выдержала только первая. И в настоящий момент именно модель Чена «сущность—связь», или «Entity Relationship», стала фактическим стандартом при инфологическом моделировании баз данных. Общепринятым стало сокращенное название ER-модель, большинство современных CASE-средств содержат инструментальные средства для описания данных в формализме этой модели. Кроме того, разработаны методы автоматического преобразования проекта БД из ER-модели в реляционную, при этом преобразование выполняется в даталогическую модель, соответствующую конкретной СУБД. Все CASE-системы имеют развитые средства документирования процесса разработки БД, автоматические генераторы отчетов позволяют подготовить отчет о текущем состоянии проекта БД с подробным описанием объектов БД и их отношений как в графическом виде, так и в виде готовых стандартных печатных отчетов, что существенно облегчает ведение проекта.
В настоящий момент не существует единой общепринятой системы обозначений для ER-модели и разные CASE-системы используют разные графические нотации, но разобравшись в одной, можно легко понять и другие нотации.
Как любая модель, модель «сущность—связь» имеет несколько базовых понятий,
которые образуют исходные кирпичики, из которых строятся уже более сложные объекты
по заранее определенным правилам.
Эта модель
в наибольшей степени согласуется с концепцией объектно-ориентированного проектирования,
которая в настоящий момент несомненно является базовой для разработки сложных
программных систем, поэтому многие понятия вам могут показаться знакомыми, и
если это действительно так, то тем проще вам будет освоить технологию проектирования
баз данных, основанную на ER-модели.
В основе
ER-модели лежат следующие базовые понятия:
Рис.
7.1. Пример определения сущности в модели ER
Между сущностями
могут быть установлены связи — бинарные ассоциации, показывающие, каким
образом сущности соотносятся или взаимодействуют между собой. Связь может существовать
между двумя разными сущностями или между сущностью и ей же самой (рекурсивная
связь). Она показывает, как связаны экземпляры сущностей между собой. Если
связь устанавливается между двумя сущностями, то она определяет взаимосвязь
между экземплярами одной и другой сущности. Например, если у нас есть связь
между сущностью «Студент» и сущностью «Преподаватель»
и эта связь — руководство дипломными проектами, то каждый студент имеет только
одного руководителя, но один и тот же преподаватель может руководить множеством
.студентов-дипломников. Поэтому это будет связь «один-ко-многим»
(1:М), один со стороны «Преподаватель» и многие со стороны «Студент»
(см. рис. 7.2).

Рис.
7.2. Пример отношения «один-ко-многим» при связывании
сущностей «Студент» и «Преподаватель»
В разных
нотациях мощность связи изображается по-разному. В нашем примере мы используем
нотацию CASE системы POWER DESIGNER, здесь .множественность изображается путем
разделения линии связи на 3. Связь имеет общее имя «Дипломное проектирование»
и имеет имена ролей со стороны обеих сущностей. Со стороны студента эта роль
называется «Пишет диплом под руководством», со стороны преподавателя
эта связь называется «Руководит». Графическая
интерпретация связи позволяет сразу прочитать смысл взаимосвязи между сущностями,
она наглядна и легко интерпретируема. Связи делятся на три типа по множественности:
один-к-одному (1:1), од и и-ко-многим (1:М), многие-ко-многим
(М:М). Связь один-к-одному означает, что экземпляр одной сущности связан
только с одним экземпляром другой сущности. Связь 1: М означает, что один экземпляр
сущности, расположенный слева по связи, может быть связан с несколькими экземплярами
сущности, расположенными справа по связи. Связь «один-к-одному»
(1:1) означает, что один экземпляр одной сущности связан только с одним экземпляром
другой сущности, а связь «многие-ко-мно-гим» (М:М) означает, что
один экземпляр первой сущности может быть связан с несколькими экземплярами
второй сущности, и наоборот, один экземпляр второй сущности может быть связан
с несколькими экземплярами первой сущности. Например, если мы рассмотрим связь
типа «Изучает» между сущностями «Студент» и «Дисциплина»,
то это связь типа «многие-ко-многим» (М:М), потому что каждый студент
может изучать несколько дисциплин, но и каждая дисциплина изучается множеством
студентов.ч Такая связь изображена на рис. 7.3.
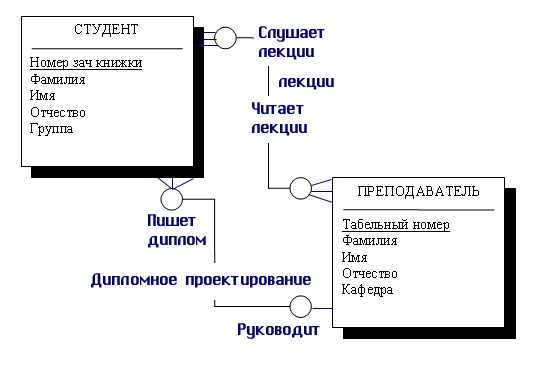
Рис.
7.3. Пример моделирования связи «многие-ко-многим»
Рассмотрим
для этого ранее приведенный пример связи «Дипломное проектирование».
На нашем рисунке эта связь интерпретируется как необязательная с двух сторон.
Но ведь на самом деле каждый студент, который пишет диплом, должен иметь своего
руководителя дипломного проектирования, но, с другой стороны, не каждый преподаватель
должен вести дипломное проектирование. Поэтому в данной смысловой постановке
изображение этой связи изменится и будет выглядеть таким, как представлено на
рис. 7.4.
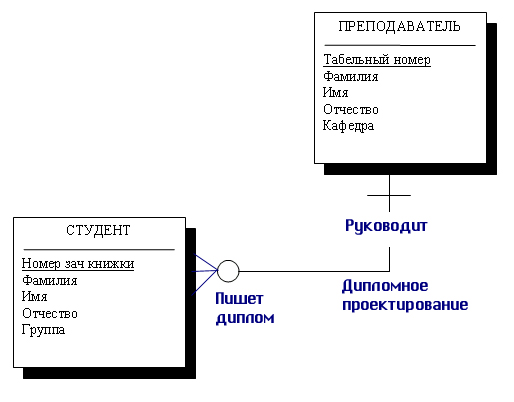
Рис.
7.4. Пример обязательной и необязательной связи между сущностями
Кроме того,
в ER-модели допускается принцип категоризации сущностей. Это значит, что, как
и в объектно-ориентированных языках программирования, вводится понятие подтипа
сущности, то«есть сущность может быть представлена в виде двух или более
своих подтипов — сущностей, каждая из которых может иметь общие атрибуты
и отношения и/или атрибуты и отношения, которые определяются однажды на верхнем
уровне и наследуются на нижнем уровне. Все подтипы одной сущности рассматриваются
как взаимоисключающие, и при разделении сущности па подтипы она должна быть
представлена в виде полного набора взаимоисключающих подтипов. Если на уровне
анализа не удается выявить полный Перечень подтипов, то вводится специальный
подтип, называемый условно ПРОЧИЕ, который в дальнейшем может быть уточнен.
В реальных системах бывает достаточно ввести подтипизацпю на двух-трех уровнях.
Сущность,
на основе которой строятся подтипы, называется супертипом. Любой экземпляр
супертипа должен относиться к конкретному подтипу. Для графического изображения
принципа категоризации или типизации сущности вводится специальный графический
элемент, называемый узел-дискриминатор, в нотации POWER DESIGNER он изображается
в виде полукруга, выпуклой стороной обращенного к суперсущности. Эта сторона
соединяется направленной стрелкой с суперсущностью, а к диаметру этого круга
стрелками подсоединяются подтипы данной сущности (см. рис. 7.5).
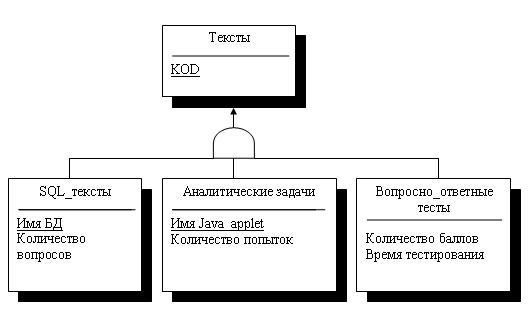
Рис.
7.5. Диаграмма подтипов сущности ТЕСТ
Эту диаграмму
можно расшифровать следующим образом. Каждый тест в некоторой системе тестирования
является либо тестом проверки знаний языка SQL, либо некоторой аналитической
задачей, которая выполняется с использованием заранее написанных Java-апплетов,
либо тестом по некоторой области знаний, состоящим из набора вопросов и набора
ответов, предлагаемых к каждому вопросу.
В результате
построения модели предметной области в виде набора сущностей и связей получаем
связный граф. В полученном графе необходимо избегать циклических связей — они
выявляют некорректность модели.
В качестве
примера спроектируем инфологическую модель системы, предназначенной для хранения
информации о книгах ц областях знаний, представленных в библиотеке. Описание
предметной области было приведено ранее. Разработку модели начнем с выделения
основных сущностей.
Прежде всего,
существует сущность «Книги», каждая книга имеет уникальный шифр,
крторый является ее ключом, и ряд атрибутов, которые взяты из описания предметной
области. Множество экземпляров сущности определяет множество книг, которые хранятся
в библиотеке. Каждый экземпляр сущности «Книги» соответствует не
конкретной книге, стоящей на полке, а описанию некоторой книги, которое дается
обычно в предметном каталоге библиотеке. Каждая книга может присутствовать в
нескольких экземплярах, и это как раз те конкретные книги, которые стоят на
полках библиотеки. Для того чтобы отразить это, мы должны ввести сущность «Экземпляры»,
которая будет содержать описания всех экземпляров книг, которые хранятся в библиотеке.
Каждый экземпляр сущности «Экземпляры» соответствует конкретной
книге на полке. Каждый экземпляр имеет уникальный инвентарный номер, однозначно
определяющий конкретную книгу. Кроме того, каждый экземпляр книги может находиться
либо в библиотеке, либо на руках у некоторого читателя, и в последнем случае
для данного экземпляра указываются дополнительно дата взятия книги читателем
и дата предполагаемого возврата книги.
Между сущностями
«Книги» и «Экземпляры» существует связь «один-ко-многим»
(1:М), обязательная с двух сторон. Чем определяется данный тип связи? Мы можем
предположить, что каждая книга может присутствовать в библиотеке в нескольких
экземплярах, поэтому связь «один-ко-многим». При этом если в библиотеке
нет ни одного экземпляра дайной книги, то мы не будем хранить ее
описание, поэтому если книга описана в сущности «Книги», то по крайней
мере один экземпляр этой книги присутствует в библиотеке. Это означает, что
со стороны книги связь обязательная. Что касается сущности «Экземпляры»,
то не может существовать в библиотеке ни одного экземпляра, который бы не относился
к конкретной книге, поэтому и со стороны «Экземпляры» связь тоже
обязательная.
Теперь нам
необходимо определить, как в нашей системе будет представлен читатель. Естественно
предложить ввести для этого сущность «Читатели», каждый экземпляр
которой будет соответствовать конкретному читателю. В библиотеке каждому читателю
присваивается уникальный номер читательского билета, который будет однозначно
идентифицировать нашего читателя. Номер читательского билета будет ключевым
атрибутом сущности «Читатели». Кроме того, в сущности «Читатели»
должны присутствовать дополнительные атрибуты, которые требуются для решения
поставленных задач, этими атрибутами будут: «Фамилия Имя Отчество»,
«Адрес читателя», «Телефон домашний» и «Телефон
рабочий». Почему мы ввели два отдельных атрибута под телефоны? Потому
что надо в разное время звонить по этим телефонам, чтобы застать читателя, поэтому
администрации библиотеки будет важно знать, к какому типу относится данный телефон.
В описании нашей предметной области существует ограничение на возраст наших
читателей, поэтому в сущности «Читатели» надо ввести обязательный
атрибут «Дата рождения», который позволит нам контролировать возраст
наших читателей.
Из описания
предметной области мы знаем, что каждый читатель может держать на руках несколько
экземпляров книг. Для отражения этой ситуации нам надо провести связь между
сущностями «Читатели» и «Экземпляры». А почему не между
сущностями «Читатели» и «Книги»? Потому что читатель
берет из библиотеки конкретный экземпляр конкретной книги, а не просто книгу.
А как же узнать, какая книга у данного читателя? А это можно будет узнать по
дополнительной связи между сущностями «Экземпляры» и «Книги»,
и эта связь каждому экземпляру ставит в соответствие одну книгу, поэтому мы
в любой момент можем однозначно определить, какие книги находятся на руках у
читателя, хотя связываем с читателем только инвентарные номера взятых книг.
Между сущностями «Читатели» и «Экземпляры» установлена
связь «один-ко-многим», и при этом она не обязательная с двух сторон.
Читатель в данный момент может не держать ни одной книги на руках, а с другой
стороны, данный экземпляр книги может не находиться ни у одного читателя, а
просто стоять на полке в библиотеке.
Теперь нам
надо отразить последнюю сущность, которая связана с системным каталогом. Системный
каталог содержит перечень всех областей знаний, сведения по которым содержатся
в библиотечных книгах. Мы можем вспомнить системный каталог в библиотеке, с
которого мы обычно начинаем поиск нужных нам книг, если мы не знаем их авторов
и названий. Название области знаний может быть длинным и состоять из нескольких
слов, поэтому для моделирования системного каталога мы введем сущность «Системный
каталог» с двумя атрибутами: «Код области знаний» и «Название
области знаний». Атрибут «Код области знаний» будет ключевым
атрибутом сущности.
Из описания
предметной области нам известно, что каждая книга может содержать сведения из
нескольких областей знаний, а с другой стороны, из практики известно, что в
библиотеке может присутствовать множество книг, относящихся к одной и той же
области знаний, поэтому нам необходимо установить между сущностями «Системный
каталог» и «Книги» связь «миогие-ко-многим», обязательную
с двух сторон. Действительно, в системном1 каталоге не должно присутствовать
такой области знаний, сведения по которой не представлены ни в одной книге нашей
библиотеки, противное было бы бессмысленно. И обратно, каждая книга должна быть
отнесена к одной или нескольким областям знаний для того, чтобы читатель мог
ее быстрее найти.
Инфологическая
модель предметной области «Библиотека» представлена на рис. 7.6.
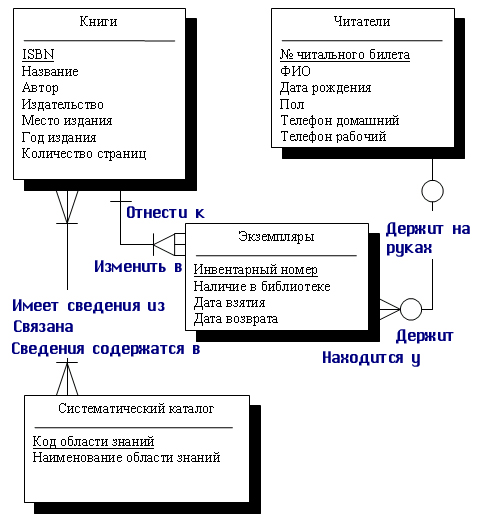
Рис.
7.6. Инфологическая модель «Библиотека»
Инфологическая
модель «Библиотека» разработана нами под те задачи, которые были
перечислены ранее. В этих задачах мы не ставили условие хранения истории чтения
книги, например, с целью поиска того, кто раньше держал книгу и мог нанести
ей вред или забыть в ней случайно большую сумму денег. Если бы мы ставили перед
собой задачу хранения и этой информации, то наша инфо-логическая модель была
бы другой. Я оставлю эту задачу для вашего самостоятельного творчества.
Переход к реляционной модели данных
Инфологическая
модель используется на ранних стадиях разработки проекта. Если понимать язык
условных обозначений, которые соответствуют категориям ER-модели, то ее можно
легко «читать», следовательно, она доступна для анализа программистам-разработчикам,
которые будут разрабатывать отдельные приложения. Она имеет однозначную интерпретацию,
в отличие от некоторых предложений естественного языка, и поэтому здесь не может
быть никакого недопонимания со стороны разработчиков.
Все специалисты
всегда предпочитают выражать свои мысли на некотором формальном языке, который
обеспечивает однозначную их трактовку. Таким языком для программистов раньше
был язык алгоритмов. Любой алгоритм имел однозначную интерпретацию. Он мог быть
реализован на разных языках программирования, но сам алгоритм был и оставался
одним и тем же. В первые годы развития вычислительной техники широко издавались
сборники алгоритмов для широко распространенных математических задач. Эти сборники
программистами прочитывались как увлекательные детективные романы, и они все
настоящим программистам были понятны, хотя специалисты других профилей смотрели
на эти сборники как на издания на иностранных, неведомых им, языках. Для описания
алгоритмов могли использоваться разные формализмы. Одним из таких формализмов
был метаязык, в котором использовались слова на естественном языке и каждый
мог прочесть эти слова, но смысл самого алгоритма мог понять только тот, кто
владел знаниями трактовки алгоритмов.
Вот таким
условным общепринятым языком описания базы данных и стал язык ER-модели. Для
ER-модели существует алгоритм однозначного преобразования ее в реляционную модель
данных, что позволило в дальнейшем разработать множество инструментальных систем,
поддерживающих процесс разработки информационных систем, базирующихся на технологии
баз данных. И во всех этих системах существуют средства описания инфологической
модели разрабатываемой БД с возможностью автоматической генерации той даталогической
модели, на которой будет реализовываться проект в дальнейшем.
Рассмотрим
правила преобразования ER-модели в реляционную.
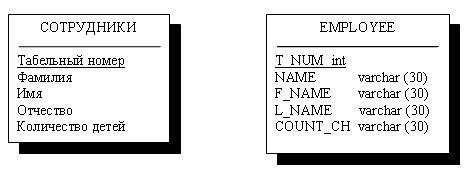
Рис.
7.7. Преобразование сущности СОТРУДНИК к отношению EMPLOYEE
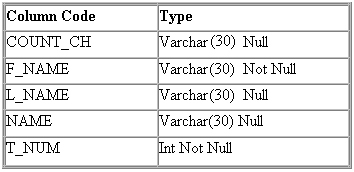
Рис. 7.8. Свойства
атрибутов отношения EMPLOYEE
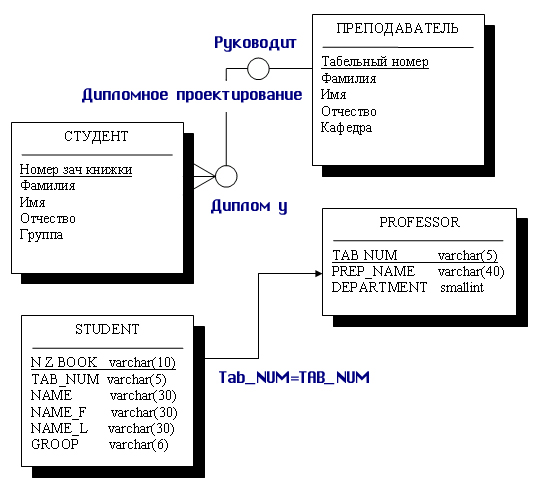
Рис.
7.9. Преобразование взаимосвязанных сущностей СТУДЕНТ и
ПРЕПОДАВАТЕЛЬ к взаимосвязанным отношениям STUDENT
и PROFESSOR
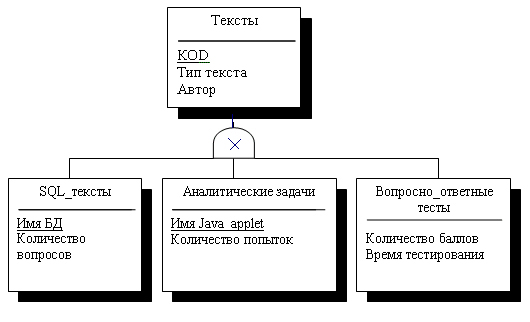
Рис.
7.10. Исходная модель взаимосвязи супертипа и подтипов
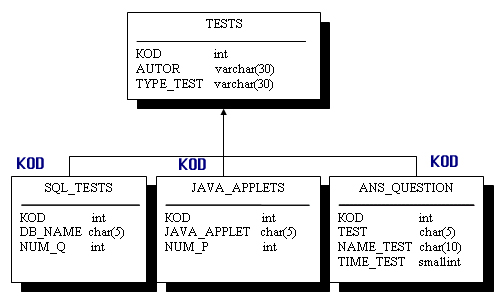
Рис.7.11.
Результирующая модель с наследованием только идентификатора суперсущности
Разрешение
связей типа «многие-ко-многим». Так как в реляционной модели данных
поддерживаются между отношениями только связи типа «один-ко-мно-гим»,
а в ER-модели допустимы связи «многие-ко-многим», то необходим специальный
механизм преобразования, который позволит отразить множественные связи, неспецифические
для реляционной модели, с помощью допустимых для нее категорий. Это делается
введением специального дополнительного связующего отношения, которое связано
с каждым исходным связью «один-ко-мно-гим», атрибутами этого отношения
являются первичные ключи связываемых отношений. Так, например, в схеме «Библиотека»
присутствует связь такого типа между сущностью «Книги» и «Системный
каталог». Для разрешения этой неспецифической связи при переходе к реляционной
модели должно быть введено специальное дополнительное отношение, которое имеет
всего два атрибута: ISBN (шифр книги) и KOD (код области знаний). При этом каждый
из атрибутов нового отношения является внешним ключом (FORKING KEY), а вместе
они образуют первичный ключ (PRIMARY KEY) новой связующей сущности. На рис.
7.12 представлена реляционная модель, соответствующая представленной ранее на
рис. 7.6 инфологической модели «Библиотека».
Теория нормализации,
которую мы рассматривали ранее применительно к реляционной модели, применима
и к модели «сущность—связь». Поэтому нормализацию можно проводить
и на уровне инфологической (семантической) модели и
смысл ее аналогичен нормализации реляционной модели. Алгоритм приведения семантической
модели к 5-й нормальной форме может быть следующим:
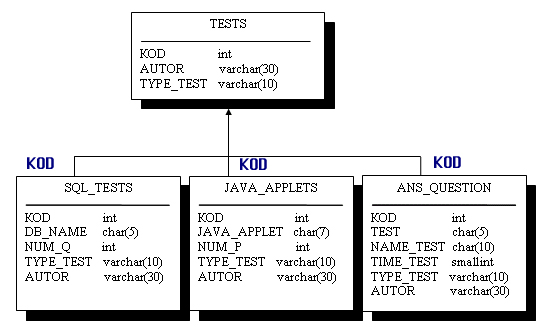
Рис.
7.12. Результирующая модель с наследованием всех атрибутов суперсущности
Шаг 1.
Проанализировать схему на присутствие сущностей, которые скрыто моделируют
несколько разных взаимосвязанных классов объектов реального мира (именно это
соответствует ненормализованным отношениям). Если такое выявлено, то разделить
каждую из этих сущностей на несколько новых сущностей и установить между ними
соответствующие связи, полученная схема будет находиться в первой нормальной
форме. Перейти к шагу 2.
Шаг 2.
Проанализировать все сущности, имеющие составные первичные ключи, на наличие
неполных функциональных зависимостей непервичных атрибутов от атрибутов возможного
ключа. Если такие зависимости обнаружены, то разделить данные сущности на 2,
определить для каждой сущности первичные ключи и установить между ними соответствующие
связи. Полученная схема будет находиться во второй нормальной форме. Перейти
к шагу 3.
Шаг 3.
Проанализировать неключевые атрибуты всех сущностей на наличие транзитивных
функциональных зависимостей. При обнаружении таковых расщепить каждую сущность
на несколько таким образом, чтобы ликвидировать транзитивные зависимости. Схема
находится в третьей нормальной форме. Перейти к шагу 4.
Шаг 4.
Проанализировать все сущности на наличие детерминантов, которые не являются
возможными ключами. При обнаружении подобных расщепить сущность на две, установив
между ними соответствующие связи. Полученная схема соответствует нормальной
форме Бойса—Кодда. Перейти к шагу 5.
Шаг 5.
Проанализировать все сущности на наличие многозначных зависимостей. Если
обнаружатся сущности, у которых имеется более одной многозначной зависимости,
то расщепить такие сущности на две, установив между ними соответствующие связи.
Полученная схема будет находиться в четвертой нормальной форме. Перейти к шагу
6.
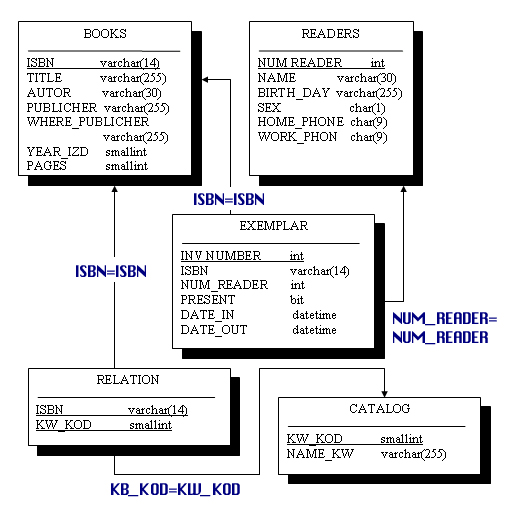
Рис.
7.13. Реляционная схема «Библиотека»
Шаг 6.
Проанализировать сущности на наличие в них зависимостей проекции-соединения.
При обнаружении таковых расщепить сущность на требуемое число взаимосвязанных
сущностей и установить между ними требуемые связи. Полученная таким образом
схема будет находиться в пятой нормальной форме и, будучи формально преобразованной
к реляционной схеме по указанным выше принципам, даст реляционную схему также
в пятой нормальной форме.
|
|
