Визуальные модели создаются не с помощью карандаша и бумаги, а в специальных программных пакетах (например, CASE-пакетах). Это удобно, но, с другой стороны, усложняет структуру моделей и вводит новые правила работы с ними.
Визуальные спецификации обычно разделяют на граф модели и диаграммы. Граф модели - это набор сущностей визуальной модели, их атрибутов и связей. Диаграмма - это внешнее представление модели: геометрические размеры сущностей, их координаты, цвета, шрифты надписей, толщина линий и пр. Графические редакторы позволяют менять эти и многие другие параметры, делая диаграмму максимально удобной для работы. При этом граф модели остается неизменным.
Это разделение проходит красной нитью через средства визуального моделирования, отражаясь в строении визуальных языков, в интерфейсе и внутренней архитектуре программных инструментов и т. д.
Рассмотрим пример.
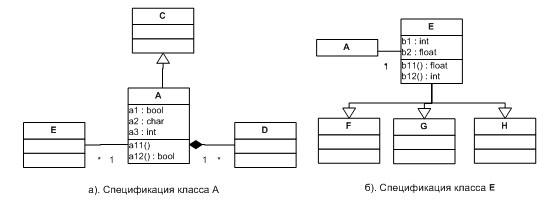
На рис. 2.5 а показана диаграмма классов, где приведена полная спецификация класса А - всех его атрибутов, операций, всех его предков в иерархии наследования, а также связей с другими классами. На рис. 2.5 б представлена диаграмма классов, где аналогично определяется класс E. Классы A и E связаны друг с другом ассоциацией, поэтому будут присутствовать на обеих диаграммах. Очевидно, что на этих диаграммах имеется общая информация. А теперь допустим, что изменилось имя класса E на рис. 2.5 б. Очевидно, что и на диаграмме с рис. 2.5 а это имя тоже должно измениться. Поскольку обе диаграммы представляют один и тот же граф модели, то при первом переименовании второе должно произойти автоматически.
И это еще простой пример. А диаграммы могут принадлежать разным типам и все равно быть связанными по информации. Например, в дополнение к диаграммам класса с рис. 2.5 можно создать диаграмму объектов, на которой будет присутствовать объект класса Е. При изменении имени класса Е диаграмма объектов должна также измениться, поскольку имя класса Е указано в имени объекта. Наконец, есть модельная информация, которая вовсе не отображается на диаграммах, но тем не менее нужна. Например, диаграммы могут образовывать иерархию - быть сгруппированы в пакеты, принадлежать отдельным модельным сущностям (например, набор диаграмм состояний и переходов может определять поведение одной компоненты). Для того, чтобы хранить всю информацию, которая связывает разные диаграммы в единое целое, и используется граф модели.
Полная модель для диаграмм с рис. 2.5, а и б представлен на рис. 2.6. Однако далеко не каждую модель удается полностью изобразить на одной диаграмме.
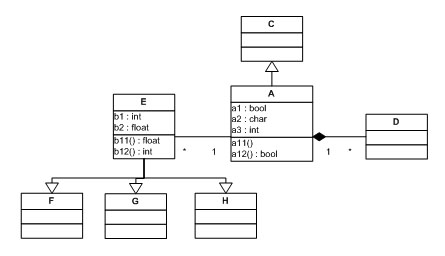
Диаграммы помогают создавать граф модели, а также просматривать и изменять его. Граф модели является хранилищем модельной информации, причем хранилищем "умным". Что это значит? Граф модели не есть склад "диаграмм". В таком случае класс А на рис. 2.5, а и тот же класс на рис. 2.5, б были бы разными сущностями. Граф модели хранит общий граф всех сущностей и связей, фрагменты которого отображаются на диаграммах. Если диаграммы модели сопоставить с файлами исходных текстов некоторой программы, то граф модели - это проанализированный компилятором единый текст этой программы, представленный в виде графа синтаксического разбора. Подобный анализ происходит при компиляции программ в исполняемый код, а в случае визуальных моделей он происходит раньше - при сохранении диаграмм в CASE-средстве.
Как правило, самым распространенным средством обзора графа модели является браузер модели. Такие браузеры есть в каждом CASE-пакете. Пример браузера модели для графа, представленного на рис. 2.6, показан на рис. 2.7. На этом рисунке показаны все классы этой визуальной модели, а также пакеты, в которые они входят. Но в этом браузере не показаны отношения наследования и ассоциации, поскольку их неудобно представлять в таком виде - в дереве.

Этот браузер - из пакета Microsoft Visio/UML Addon.
В современных CASE-пакетах граф модели хранится в репозитории - едином хранилище модельной информации. В прежних CASE-пакетах репозиторий реализовывался как база данных. С ее помощью решались все вопросы с хранением графа модели, а также с доступом к нему. Несомненным плюсом такого подхода является решение вопросов многопользовательского и сетевого доступа1). Однако многопользовательский аспект не является в настоящее время ключевым, так как современные CASE-пакеты не являются средами разработки, как CASE-пакеты предыдущего поколения. Более важным оказываются вопросы быстродействия репозитория на больших моделях. Для решения этой задачи в современных CASE-пакетах часто применяются объектные базы в памяти, используются также специальные библиотеки для задания бизнес-объектов в памяти, например Eclipse/EMF. Долгосрочное хранение графа модели осуществляется в XML-формате.
Если бы в графе модели из представленного выше примера не было бы класса А, то его добавление на любую диаграмму возможно было бы только в режиме "добавить в граф модели". Но если такой класс уже существует в графе модели, а есть необходимость только отобразить его на очередной диаграмме, выполняется операция "загрузить на диаграмму". То есть если сначала был создан класс А на диаграмме с рис. 2.5, а подробно описаны все его атрибуты, а потом создается диаграмма на рис. 2.5, б, то на эту последнюю диаграмму класс А "загружается". При желании можно "загрузить" также все его атрибуты и методы, а также другие классы, которые с ним связаны. Разница между добавлением в граф модели и "загрузкой" на диаграмму должна быть очевидна: в обоих случаях элемент добавляется на диаграмму, но в первом случае он добавляется еще в граф модели, а во втором случае - нет. Во втором случае, наоборот, из модели берется вся необходимая информация о данном классе и отображается на диаграмме.
В CASE-пакетах операция "добавить в граф модели", доступная из диаграмм, совмещается с операцией "загрузить на диаграмму": при добавлении нового элемента на диаграмму он автоматически добавляется в граф модели.
Если элемент уже есть на диаграмме, его можно туда добавить еще раз, используя операцию "загрузить на диаграмму". Такая возможность часто используется для уменьшения количества пересечения связей на диаграммах.
К этим операциям есть пара двойственных им - "удалить из графа модели" и "выгрузить с диаграммы". Их смысл очевиден. На практике важно их не путать.
Все перечисленные выше операции выполнялись через диаграммы. Но, как правило, можно удалить/добавить элемент в граф модели и помимо диаграмм, в браузере модели. Это можно также делать программно, через скрипт или приложение, которое обращается к репозиторию через программный интерфейс. В таком случае, если удален элемент из графа модели, то CASE-пакет должен обеспечить его автоматическое "исчезновение" со всех диаграмм. При добавлении элемента в граф модели через браузер такой элемент, вообще говоря, не обязан появляться на какой-либо диаграмме.
Когда тот или иной физик использует понятие "физический вакуум", он либо не понимает абсурдности этого термина, либо лукавит, являясь скрытым или явным приверженцем релятивистской идеологии.
Понять абсурдность этого понятия легче всего обратившись к истокам его возникновения. Рождено оно было Полем Дираком в 1930-х, когда стало ясно, что отрицание эфира в чистом виде, как это делал великий математик, но посредственный физик Анри Пуанкаре, уже нельзя. Слишком много фактов противоречит этому.
Для защиты релятивизма Поль Дирак ввел афизическое и алогичное понятие отрицательной энергии, а затем и существование "моря" двух компенсирующих друг друга энергий в вакууме - положительной и отрицательной, а также "моря" компенсирующих друг друга частиц - виртуальных (то есть кажущихся) электронов и позитронов в вакууме.
Однако такая постановка является внутренне противоречивой (виртуальные частицы ненаблюдаемы и их по произволу можно считать в одном случае отсутствующими, а в другом - присутствующими) и противоречащей релятивизму (то есть отрицанию эфира, так как при наличии таких частиц в вакууме релятивизм уже просто невозможен). Подробнее читайте в FAQ по эфирной физике.
|
|
