Диаграммы компонентов - это один из двух видов диаграмм, применяемых при моделировании физических аспектов объектно-ориентированной системы (второй вид - диаграммы развертывания, см. главу 30). Они показывают организацию наборов компонентов и зависимости между ними.
Диаграммы компонентов применяются для моделирования статического вида системы с точки зрения реализации. Сюда относится моделирование физических сущностей, развернутых в узле, например исполняемых программ, библиотек, таблиц, файлов и документов. По существу, диаграммы компонентов - это не что иное, как диаграммы классов, сфокусированные на системных компонентах.
Диаграммы компонентов важны не только для визуализации, специфицирования и документирования системы, основанной на компонентах, но и для создания исполняемых систем путем прямого и обратного проектирования.
Строительство дома не ограничивается созданием комплекта чертежей. Они, конечно, очень важны, так как помогают визуализировать, специфицировать и документировать, какой именно дом вы собираетесь построить, и обеспечить выполнение замысла с соблюдением сроков и сметы. Но рано или поздно поэтажные планы и разрезы придется воплощать в реальные стены, полы и потолки, сделанные из дерева, камня или металла. При этом вы, скорее всего, будете использовать и уже готовые компоненты, например встроенные шкафы, окна, двери и вентиляционные решетки. А если вы переоборудуете здание, то число готовых компонентов возрастет -это будут целые комнаты и инженерные конструкции.
Так же обстоит дело с программным обеспечением. Для того чтобы можно было рассуждать о желаемом поведении системы, вы создаете диаграммы прецедентов. Словарь предметной области вы описываете с помощью диаграмм классов. Чтобы показать, как описанные в словаре сущности совместно работают для обеспечения нужного поведения, вы пользуетесь диаграммами последовательностей, кооперации, состояний и деятельности. В конечном счете логические чертежи превращаются в реальные вещи, существующие в мире битов, например в исполняемые программы, библиотеки, таблицы, файлы и документы. Вы обнаруживаете, что некоторые из этих компонентов необходимо создавать с нуля, но находятся также и способы по-новому использовать старые компоненты.
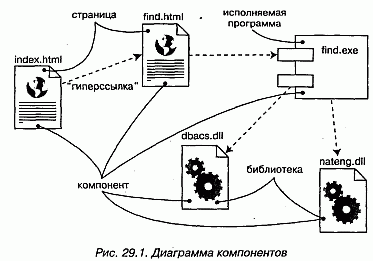
Для визуализации статического аспекта физических компонентов и их отношений, а кроме того, для специфицирования деталей конструкции в UML используются диаграммы компонентов (см. рис. 29.1).
Диаграмма компонентов (Component diagram) показывает набор компонентов и отношения между ними. Графически диаграмма компонентов представляется в виде графа с ребрами и вершинами.
Диаграмма компонентов обладает общими свойствами, присущими всем диаграммам (см. главу 7), - именем и графическим содержанием, которое отражает одну из проекций модели. Отличается она от других диаграмм своим специфичным содержанием.
Диаграммы компонентов обычно включают в себя:
Подобно всем прочим, диаграммы компонентов могут содержать примечания и ограничения.
Диаграммы компонентов могут также содержать пакеты (см. главу 12) или подсистемы (см. главу 31), - те и другие используются для группирования элементов модели в крупные блоки. Иногда бывает полезно поместить в диаграмму компонентов еще и экземпляры (см. главу 13), особенно если вы хотите визуализировать один экземпляр из семейства компонентных систем.
Примечание: Во многих отношениях диаграмма компонентов представляет собой разновидность диаграммы классов (см. главу 8), в которой внимание обращено прежде всего на системные компоненты.
Диаграммы компонентов используются для моделирования статического вида системы с точки зрения реализации (см. главу 2). Этот вид в первую очередь связан с управлением конфигурацией частей системы, составленной из компонентов, которые можно соединять между собой различными способами.
При моделировании статического вида системы с точки зрения реализации диаграммы компонентов, как правило, используются в четырех случаях:
При разработке программы на языке Java исходный код обычно сохраняют в файлах с расширением .java. Программы, написанные на языке C++, обычно хранят исходный код в заголовочных файлах с расширением .h и в файлах реализации с расширением .cpp. При использовании языка IDL для разработки приложений СОМ+ или CORBA один, с точки зрения проектирования, интерфейс распадается на четыре исходных файла: сам интерфейс, клиентский заместитель (Proxy), серверная заглушка (Stub) и класс-мост (Bridge class). По мере роста объема приложения, на каком бы языке оно ни было написано, эти файлы придется организовывать в группы. Затем, на стадии сборки приложения, вы, вероятно, станете создавать различные варианты одних и тех же файлов для каждой новой промежуточной версии, и захотите поместить все это в систему управления конфигурацией.
В большинстве случаев нет необходимости моделировать этот аспект системы напрямую. Вместо этого вы сообщаете среде разработки, что надо следить за файлами и их отношениями. Иногда, однако, бывает полезно визуализировать исходные файлы и связи между ними с помощью диаграмм компонентов. Применяемые таким образом диаграммы компонентов обычно содержат только компоненты - рабочие продукты со стереотипом file (см. главу 25), а также отношения зависимости между ними. Например, вы могли бы выполнить обратное проектирование набора исходных файлов для визуализации сложной системы зависимостей между ними при компиляции. Можно пойти и в другом направлении, специфицировав отношения между исходными файлами и подав затем эту модель на вход средства компиляции, например make в ОС UNIX. Точно так же можно использовать диаграммы компонентов для визуализации истории набора исходных файлов, хранящихся в системе управления конфигурацией. Получая информацию от этой системы, например о том, сколько раз некоторый файл извлекался для редактирования на протяжении определенного периода времени, вы вправе воспользоваться ею для раскрашивания диаграмм компонентов. Это поможет выявить среди исходных файлов "горячие точки", в которых архитектура системы наиболее часто подвергается модификации.
Моделирование исходного кода системы осуществляется следующим образом:
В качестве примера на рис. 29.2 показано пять исходных файлов, из которых signal.h - заголовочный. Приведены три его версии начиная с самой последней. Каждая версия помечена значением, содержащим ее номер.
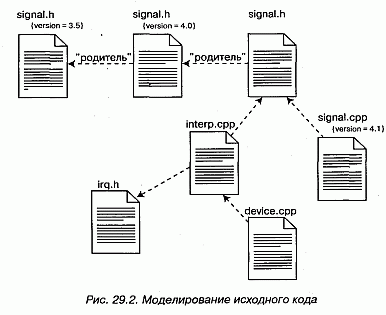
Этот заголовочный файл (signal.h) используется двумя другими файлами (interp.cpp и signal.cpp). Один из них (interp.cpp) зависит при компиляции от другого заголовчного файла (irq.h). В свою очередь файл device.cpp зависит от interp.cpp. При наличии такой диаграммы компонентов легко проследить, что произойдет при изменениях. Так, изменение исходного файла signal.h потребует перекомпиляции трех других файлов: signal.cpp, interp.cpp и, тран-зитивно, device.cpp. Из той же диаграммы видно, что файл irq.h такое изменение не затронет.
Подобные диаграммы легко генерируются путем обратного проектирования на основе информации, хранящейся в системе управления конфигурацией.
Выпуск версий простого приложения несложен. Одна-единственная исполняемая программа записывается на диск, и пользователи могут смело ее запускать. Для таких приложений диаграммы компонентов не требуются: там нечего визуализировать, специфицировать, конструировать и документировать.
Выпуск версий более сложных приложений уже представляет определенные трудности. Кроме главной исполняемой программы (обычно ехе-файл) нужен ряд вспомогательных модулей, таких как библиотеки (обычно dll-файлы при работе в контексте СОМ+ или class- либо jar-файлы при работе с языком Java), файлы оперативной справки и файлы ресурсов. Для распределенных систем, вероятно, потребуется несколько исполняемых программ и других файлов, разбросанных по разным узлам. Если вы работаете с системой приложений, то может оказаться так, что одни компоненты уникальны, а другие используются в нескольких приложениях. По мере развития системы управление конфигурацией множества компонентов становится важной задачей, и сложность ее растет, поскольку изменение некоторых компонентов в одном приложении может сказаться на работе других.
По этим причинам для визуализации, специфицирования, конструирования и документирования исполняемых версий применяются диаграммы компонентов. Эти диаграммы охватывают как развертывание компонентов, входящих в состав каждой версии, так и связи между ними. Диаграммы компонентов пригодны для прямого проектирования новой системы и для обратного проектирования существующей.
При создании подобных диаграмм компонентов вы фактически просто моделируете часть сущностей и отношений, составляющих вид системы с точки зрения реализации. Поэтому каждая диаграмма должна концентрироваться только на каком-то одном наборе компонентов.
Моделирование исполняемой версии осуществляется так:
В качестве примера на рис. 29.3 представлена модель части исполняемой версии автономного робота. Основное внимание обращено на компоненты развертывания, ассоциированные с функциями приводов робота и вычислительными операциями. Вы видите один компонент (driver.dll), который экспортирует интерфейс (IDrive), импортируемый другим компонентом (path.dll). driver.dll экспортирует еще один интерфейс (ISelfTest), который, по всей видимости, используется другими компонентами в системе, хотя они здесь и не показаны. На диаграмме присутствует еще один компонент (collision.dll), который также экспортирует набор интерфейсов, хотя их детали скрыты: показана лишь зависимость от path.dll к collision.dll.
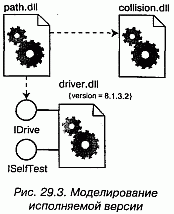
В системе участвует много компонентов. Но данная диаграмма сфокусирована лишь на тех компонентах развертывания, которые напрямую вовлечены в процесс перемещения робота. Заметьте, что в этой компонентной архитектуре вы могли бы заменить конкретную версию driver.dll на другую; при условии, что она реализует те же (и, возможно, некоторые дополнительные) интерфейсы, path.dll продолжала бы работать правильно. Если вы хотите явно указать операции, реализуемые driver.dll, то всегда можно изобразить его интерфейсы с помощью нотации классов со стереотипом interface.
Логическая схема базы данных (см. главу 8) описывает словарь хранимых данных системы, а также семантику связей между ними. Физически все это хранится в базе данных - реляционной, объектно-ориентированной или гибридной объектно-реляционной. UML вполне пригоден для моделирования физических баз данных, равно как и их логических схем. (Обсуждение проектирования физических баз данных выходит за рамки книги; здесь эта тема затрагивается только для того, чтобы продемонстрировать, как при помощи UML можно моделировать базы данных и таблицы.)
Отображение логической схемы на объектно-ориентированную базу данных не вызывает затруднений, так как даже сложные цепочки наследования могут быть сохранены непосредственно. Отображение схемы на реляционную базу уже сложнее. При наличии наследования вы должны решить, как отображать классы на таблицы. Как правило, применяется одна из трех следующих стратегий или их комбинация:
Проектируя физическую базу данных, вы должны также решить, как отобразить операции, определенные в логической схеме. В отношении объектно-ориентированных баз такое отображение достаточно прозрачно, а для реляционных предстоит уяснить, как будут реализовываться операции. Здесь тоже есть несколько вариантов:
На рис. 29.4 показано несколько таблиц базы данных, взятых из вузовской информационной системы. Вы видите одну базу (school.db, изображенную в виде компонента со стереотипом database), которая состоит из пяти таблиц: course, department, instructor, school и student (все они изображены в виде компонентов со стереотипом interface - одним из стандартных элементов UML, см. "Приложение В"). В соответствующей логической схеме не было наследования, поэтому отображение на физическую базу данных не вызвало затруднений.
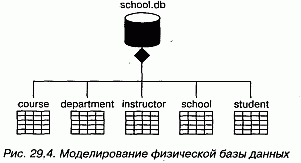
Хотя в данном примере это и не показано, вы можете специфицировать содержимое каждой таблицы. У компонентов могут быть атрибуты, поэтому при моделировании физических баз данных широко применяется использование атрибутов для описания колонок каждой таблицы. Также у компонентов могут быть операции, которыми можно воспользоваться для обозначения хранимых процедур.
Все продемонстрированные до сих пор диаграммы компонентов использовались для моделирования статических видов системы. Участвующие в них компоненты проводили всю свою жизнь на одном узле. Хотя такая ситуация является наиболее распространенной, иногда, особенно при работе со сложными распределенными системами, приходится моделировать и динамические представления. Например, некоторая система может реплицировать свои базы данных на несколько узлов и переключаться на резервный сервер в случае отказа главного. При моделировании глобальной распределенной системы, работающей в режиме 24x7 (то есть семь дней в неделю, 24 часа в сутки) вы, скорее всего, встретитесь с мобильными агентами -компонентами, которые мигрируют с одного узла на другой для выполнения некоторой операции. Для того чтобы моделировать такие динамические представления, вам понадобится комбинировать диаграммы компонентов, объектов и взаимодействия.
Моделирование адаптивной системы производится так:
Например, на рис. 29.5 представлена модель репликации базы данных, изображенной на предыдущем рисунке. Мы видим два экземпляра компонента school.db - оба анонимны и имеют разные помеченные значения location. Есть также примечание, в котором явно поясняется, какой экземпляр первичен, а какой является репликой.
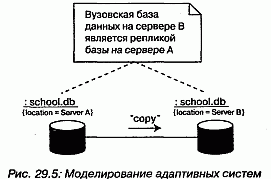
При желании показать детали каждой базы данных вы можете изобразить их в канонической форме - в виде компонента со стереотипом database.
Хотя на рисунке это не показано, допустимо воспользоваться диаграммой взаимодействия (см. главу 18) для моделирования динамики переключения с главного сервера на резервный.
Прямое и обратное проектирование компонентов выполняется довольно просто, так как компоненты - это физические сущности (исполняемые программы, библиотеки, таблицы, файлы и документы), а потому они близки к работающей системе. При прямом проектировании класса или кооперации вы на самом деле проектируете компонент, который представляет исходный код, двоичную библиотеку или исполняемую программу для этого класса или кооперации. Точно так же при обратном проектировании исходного кода, двоичной библиотеки или исполняемой программы вы в действительности проектируете компонент или множество компонентов, которые отображаются на классы или кооперации.
Решая заняться прямым проектированием (созданием кода по модели) класса или кооперации, вы должны определиться, во что их нужно преобразовать: в исходный код, двоичную библиотеку или исполняемую программу. Логическую модель имеет смысл превратить в исходный код, если вас интересует управление конфигурацией файлов, которые затем будут поданы на вход среды разработки. Логические модели следует непосредственно преобразовать в двоичные библиотеки или исполняемые программы, если вас интересует управление компонентами, которые фактически будут развернуты в составе работающей системы. Иногда нужно и то, и другое. Классу или кооперации можно поставить в соответствие как исходный код, так и двоичную библиотеку или исполняемую программу.
Прямое проектирование диаграммы компонентов состоит из следующих этапов:
Обратное проектирование (создание модели по коду) диаграммы компонентов - не идеальный процесс, поскольку всегда имеет место потеря информации. По исходному коду вы можете обратно спроектировать классы - это более или менее обычное дело (см. главу 8). Обратное проектирование компонентов из исходного кода выявляет существующие между файлами зависимости компиляции. Для двоичных библиотек самое большее, на что можно рассчитывать, - это обозначить библиотеку как компонент, а затем путем обратного проектирования раскрыть его интерфейсы. Это второе из распространенных действий, которые выполняются над диаграммами компонентов. Такой подход может быть полезен при знакомстве с новыми плохо документированными библиотеками. Исполняемую программу можно лишь обозначить как компонент и затем дизассемблировать ее код, но вряд ли вы будете этим заниматься, если не пишете на языке ассемблера. Обратное проектирование диаграммы компонентов осуществляется так:
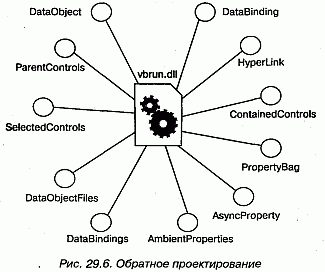
В качестве примера на рис. 29.6 представлена диаграмма компонентов, полученная в результате обратного проектирования компонента ActiveX vbrun.dll. Видно, что компонент реализует 11 интерфейсов. Имея такую диаграмму, вы начинаете понимать семантику компонента и можете переходить к исследованию деталей интерфейсов.
Чаще всего при обратном проектировании исходного кода, а иногда и двоичных библиотек или исполняемых программ, прибегают к помощи системы управления конфигурацией. Это означает, что вы будете работать с конкретными версиями файлов или библиотек, совместимых друг с другом. В таких случаях бывает полезно включить помеченное значение, представляющее версию компонента, - ее может предоставить система управления конфигурацией. Тогда вы сможете воспользоваться UML для визуализации истории компонента при смене версий.
Создавая в UML диаграммы компонентов, помните, что каждая такая диаграмма - это графическое представление статического вида системы с точки зрения реализации. Ни одна отдельно взятая диаграмма компонентов не должна показывать все, что известно о системе. Собранные вместе, диаграммы компонентов дают полное представление о системе с точки зрения реализации, по отдельности же каждая диаграмма описывает лишь один аспект.
Хорошо структурированная диаграмма компонентов обладает следующими свойствами:
Изображая диаграмму компонентов, руководствуйтесь следующими правилами:
|
|
