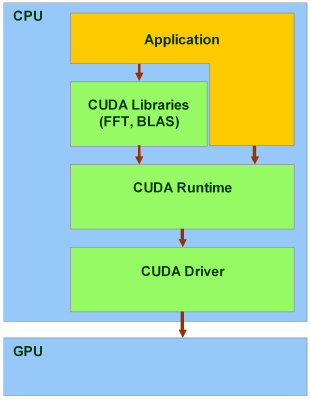
Есть и ещё один уровень, даже более высокий — две библиотеки:
CUBLAS — CUDA вариант BLAS (Basic Linear Algebra Subprograms), предназначенный для вычислений задач линейной алгебры и использующий прямой доступ к ресурсам GPU;
CUFFT — CUDA вариант библиотеки Fast Fourier Transform для расчёта быстрого преобразования Фурье, широко используемого при обработке сигналов. Поддерживаются следующие типы преобразований: complex-complex (C2C), real-complex (R2C) и complex-real (C2R).
Рассмотрим эти библиотеки подробнее. CUBLAS — это переведённые на язык CUDA стандартные алгоритмы линейной алгебры, на данный момент поддерживается только определённый набор основных функций CUBLAS. Библиотеку очень легко использовать: нужно создать матрицу и векторные объекты в памяти видеокарты, заполнить их данными, вызвать требуемые функции CUBLAS, и загрузить результаты из видеопамяти обратно в системную. CUBLAS содержит специальные функции для создания и уничтожения объектов в памяти GPU, а также для чтения и записи данных в эту память. Поддерживаемые функции BLAS: уровни 1, 2 и 3 для действительных чисел, уровень 1 CGEMM для комплексных. Уровень 1 — это векторно-векторные операции, уровень 2 — векторно-матричные операции, уровень 3 — матрично-матричные операции.
CUFFT — CUDA вариант функции быстрого преобразования Фурье — широко используемой и очень важной при анализе сигналов, фильтрации и т.п. CUFFT предоставляет простой интерфейс для эффективного вычисления FFT на видеочипах производства NVIDIA без необходимости в разработке собственного варианта FFT для GPU. CUDA вариант FFT поддерживает 1D, 2D, и 3D преобразования комплексных и действительных данных, пакетное исполнение для нескольких 1D трансформаций в параллели, размеры 2D и 3D трансформаций могут быть в пределах [2, 16384], для 1D поддерживается размер до 8 миллионов элементов.
Среда программирования
В состав CUDA входят runtime библиотеки:
- общая часть, предоставляющая встроенные векторные типы и подмножества вызовов RTL, поддерживаемые на CPU и GPU;
- CPU-компонента, для управления одним или несколькими GPU;
- GPU-компонента, предоставляющая специфические функции для GPU.
Основной процесс приложения CUDA работает на универсальном процессоре (host), он запускает несколько копий процессов kernel на видеокарте. Код для CPU делает следующее: инициализирует GPU, распределяет память на видеокарте и системе, копирует константы в память видеокарты, запускает несколько копий процессов kernel на видеокарте, копирует полученный результат из видеопамяти, освобождает память и завершает работу.
В качестве примера для понимания приведем CPU код для сложения векторов, представленный в CUDA:

Функции, исполняемые видеочипом, имеют следующие ограничения: отсутствует рекурсия, нет статических переменных внутри функций и переменного числа аргументов. Поддерживается два вида управления памятью: линейная память с доступом по 32-битным указателям, и CUDA-массивы с доступом только через функции текстурной выборки
.Программы на CUDA могут взаимодействовать с графическими API: для рендеринга данных, сгенерированных в программе, для считывания результатов рендеринга и их обработки средствами CUDA (например, при реализации фильтров постобработки). Для этого ресурсы графических API могут быть отображены (с получением адреса ресурса) в пространство глобальной памяти CUDA. Поддерживаются следующие типы ресурсов графических API: Buffer Objects (PBO / VBO) в OpenGL, вершинные буферы и текстуры (2D, 3D и кубические карты) D
irect3D9.Стадии компиляции CUDA-приложения:
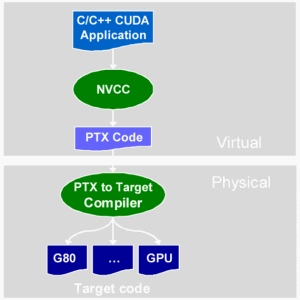
Файлы исходного кода на CUDA C компилируются при помощи программы NVCC, которая является оболочкой над другими инструментами, и вызывает их: cudacc, g++, cl и др. NVCC генерирует: код для центрального процессора, который компилируется вместе с остальными частями приложения, написанными на чистом Си, и объектный код PTX для видеочипа. Исполнимые файлы с кодом на CUDA в обязательном порядке требуют наличия библиотек CUDA runtime library (cudart) и CUDA core library (cuda).
Практические выводы
CUDA — это доступная каждому разработчику ПО технология, её может использовать любой программист, знающий язык Си. Придётся только привыкнуть к иной парадигме программирования, присущей параллельным вычислениям. Но если алгоритм в принципе хорошо распараллеливается, то изучение и затраты времени на программирование на CUDA вернутся в многократном размере.
Вполне вероятно, что в силу широкого распространения видеокарт в мире, развитие параллельных вычислений на GPU сильно повлияет на индустрию высокопроизводительных вычислений. Эти возможности уже вызвали большой интерес в научных кругах, да и не только в них. Ведь потенциальные возможности ускорения хорошо поддающихся распараллеливанию алгоритмов (на доступном аппаратном обеспечении, что не менее важно) сразу в десятки раз бывают не так часто.
Определение функций
Перед функциями в .cu файле могут стоять следующие “модификаторы”:
__device__ — это означает, что функция выполняется только на видеокарте. Из программы выполняющейся на обычном процессоре(host) её вызвать нельзя.
__global__ — Эта функция — начало вашего вычислительного ядра. Выполняется на видеокарте, но запускается только с хоста.
__host__ — Выполняется и запускается только с хоста (т.е. обычная функция C++). Если вы перед функцией укажите например __host__ и __device__ — то будут скомпилированы 2 версии функции (не все комбинации допустимы).
Определение данных
__device__ — означает что переменная находится в глобальной памяти видеокарты (т.е. которой там 512-1024Мб и выше). Очень медленная память по меркам вычислений на видеокарте(хоть и быстрее памяти центрального процессора в несколько раз), рекомендуется использовать как можно реже. В этой памяти данные сохраняются между вызовами разных вычислительных ядер. Данные сюда можно записывать и читать из host-части с помощью
cudaMemcpy(device_variable, host_variable, size, cudaMemcpyHostToDevice); //cudaMemcpyDeviceToHost - в обратную сторону
__constant__ — задает переменную в константной памяти. Следует обратить внимание, что значения для констант нужно загружать функцией cudaMemcpyToSymbol. Константы доступны из всех тредов, скорость работы сравнима с регистрами(когда в кеш попадает).
__shared__ — задает переменную в общей памяти блока тредов (т.е. и значение будет общее на всех). Тут нужно подходить с осторожностью — компилятор агрессивно оптимизирует доступ сюда(можно придушить модификатором volatile), можно получать race condition, нужно использовать __syncthreads(); чтобы данные гарантированно записались. Shared memory разделена на банки, и когда 2 потока одновременно пытаются обратиться к одному банку, возникает bank conflict и падает скорость.
Все локальные переменные которые вы определеили в ядре (__device__) — в регистрах, самая высокая скорость доступа.
Как поток узнает над чем ему работать
Допустим, надо сделать какую-то операцию над картинкой 200x200. Картинка разбивается на куски 10x10, и на каждый пиксел такого кусочка запускаем по потоку. Выглядить это будет так:
dim3 threads(10, 10);//размер квардатика, 10*10
dim3 grid(20, 20);//сколько квадратиков нужно чтобы покрыть все изображение
your_kernel<<<grid, threads>>>(image, 200,200);//Эта строка запустит 40'000 потоков (не одновременно, одновременно работать будет 200-2000 потоков примерно).
В отличии от Brook+ от AMD, где мы сразу определяем какому потоку над какими данными работать, в CUDA все не так: передаваеиые kernel-у параметры одинаковые для всех потоков, и поток должен сам получить данные для себя, чтобы сделать это, потоку нужно вычислить, в каком месте изображения он находится. В этом помогают магические переменные blockDim, blockIdx.
const int ix = blockDim.x * blockIdx.x + threadIdx.x;
const int iy = blockDim.y * blockIdx.y + threadIdx.y;
В ix и iy — координаты, с помощью которых можно получить исходные данные из массива image, и записать результат работы.
Оптимизация
Пару слов о том, как не сделать вашу программу очень медленной (написать программу работающую медленее чем CPU намного проще, чем работающую в 10 раз быстрее.
•Как можно меньше используйте __global__ память.
•При работе с __shared__ памятью избегайте конфлктов банков (впрочем многие задачи могут быть решены без shared памяти).
•Как можно меньше ветвлений в коде, где разные потоки идут по разным путям. Такой код не выполняется параллельно.
•Используйте как можно меньше памяти. Чем меньше памяти вы используете, тем агрессивнее компилятор и железо смогут запускать ваш kernel (например он может взять 100 тредов, и используя в 100 больше регистров запустить одновременно на одном MP, радикально уменьшая задержки)
Примеры Программ на CUDA C++
Исходные данные:
A[n][n] – матрица размерности n x n;
b[n] – вектор, состоящий из n элементов.
Результат:
c[n] – вектор из n элементов.
//Последовательный алгоритм умножения матрицы на вектор
for (i=0; i<n; i++)
{
c[i]=0;
for (j=0; j<m; j++)
{
c[i]=A[i][j]*b[j];
}
}
Теперь рассмотрим решение этой задачи на видеокарте. Следующий код иллюстрирует пример вызова функции CUDA:
// инициализация CUDA
if(!InitCUDA()) { return 0; }
int Size = 1000;
// обычные массивы в оперативной памяти
float *h_a,*h_b,*h_c;
h_a = new float[Size*Size];
h_b = new float[Size];
h_c = new float[Size];
for (int i=0;i<Size;i++) // инициализация массивов a и b
{
for (int k=0;k<Size;k++)
{
h_a[i*Size+k]=1;
}
h_b[i]=2;
}
// указатели на массивы в видеопамяти
float *d_a,*d_b,*d_c;
// выделение видеопамяти
cudaMalloc((void **)&d_a, sizeof(float)*Size*Size);
cudaMalloc((void **)&d_b, sizeof(float)*Size);
cudaMalloc((void **)&d_c, sizeof(float)*Size);
// копирование из оперативной памяти в видеопамять
CUDA_SAFE_CALL(cudaMemcpy(d_a, h_a, sizeof(float)*Size*Size,
cudaMemcpyHostToDevice) );
CUDA_SAFE_CALL(cudaMemcpy(d_b, h_b, sizeof(float)*Size,
cudaMemcpyHostToDevice) );
// установка количества блоков
dim3 grid((Size+255)/256, 1, 1);
// установка количества потоков в блоке
dim3 threads(256, 1, 1);
// вызов функции
MatrVectMul<<< grid, threads >>> (d_c, d_a, d_b,Size);
// копирование из видеопамяти в оперативную память
CUDA_SAFE_CALL(cudaMemcpy(h_c, d_c, sizeof(float)*Size,
cudaMemcpyDeviceToHost) );
// освобождение памяти
CUDA_SAFE_CALL(cudaFree(d_a));
CUDA_SAFE_CALL(cudaFree(d_b));
CUDA_SAFE_CALL(cudaFree(d_c));
В принципе структуру любой программы с использованием CUDA можно представить аналогично рассмотренному выше примеру. Таким образом, можно предложить следующую последовательность действий:
1. инициализация CUDA
2. выделение видеопамяти для хранения данных программы
3. копирование необходимых для работы функции данных из оперативной памяти в видеопамять
4. вызов функции CUDA
5. копирование возвращаемых данных из видеопамяти в оперативную
6. освобождение видеопамяти
Пример функции, исполнимой на видеокарте
extern "C" __global__ void MatrVectMul(float *d_c, float *d_a, float *d_b, int Size)
{
int i = blockIdx.x*blockDim.x+threadIdx.x;
int k;
d_c[i]=0;
for (k=0;k<Size;k++)
{
d_c[i]+=d_a[i*Size+k]*d_b[k];
}
}
Здесь:
threadIdx.x – идентификатор потока в блоке по координате x,
blockIdx.x – идентификатор блока в гриде по координате x,
blockDim.x – количество потоков в одном блоке.
Пока же следует запомнить, что таким образом получается уникальный идентификатор потока (в данном случае i), который можно использовать в программе, работая со всеми потоками как с одномерным массивом.
Важно помнить, что функция, предназначенная для исполнения на видеокарте, не должна обращать к оперативной памяти. Подобное обращение приведет к ошибке. Если необходимо работать с каким-либо объектом в оперативной памяти, предварительно его надо скопировать в видеопамять, и обращаться из функции CUDA к этой копии.
Среди основных особенностей CUDA следует отметить отсутствие поддержки двойной точности (типа double). Также для функций CUDA установлено максимальное время исполнения, отсутствует рекурсия, нельзя объявить функцию с переменным числом аргументов.
Следует отметить следующее, что функция, работающая на видеокарте, должна выполняться не более 1 секунды. Иначе, функция будет не завершена, и программа завершится с ошибкой.
Для синхронизации потоков в блоке существует функция __syncthreads(), которая ждет, пока все запущенные потоки отработают до этой точки. Функция __syncthreads() необходима, когда данные, обрабатываемые одним потоком, затем используются другими потоками.
Замер времени в CUDA
Для измерения времени выполнения отдельных частей программы и анализа скорости выполнения того или иного участка кода удобно использовать встроенные в CUDA функции по замеру времени.
unsigned int timer;
// создание таймера
cutCreateTimer(&timer);
// запуск таймера
cutStartTimer(timer);
… // код, время исполнения которого необходимо замерить
// остановка таймера
cutStopTimer( timer);
// получение времени
printf("time: %f (ms)\n", cutGetTimerValue(timer));
// удаление таймера
cutDeleteTimer( timer);
Заключение
Технология CUDA позволяет ощутимо увеличить производительность персональных компьютеров лишь в определенных задачах. Но сфера применения подобной технологии будет расширяться, а процесс наращивания количества ядер в обычных процессорах свидетельствует о росте востребованности параллельных многопоточных вычислений в современных программных приложениях. Не зря в последнее время все лидеры индустрии загорелись идеей объединения CPU и GPU в рамках одной унифицированной архитектуры (вспомнить хотябы разрекламированный AMD Fusion). Возможно CUDA это один из этапов в процессе данного объединения.
Источники:
Это несуществующая практика, потусторонний опыт, воображение того, чего нет на самом деле. Мысленные эксперименты подобны снам наяву. Они рождают чудовищ. В отличие от физического эксперимента, который является опытной проверкой гипотез, "мысленный эксперимент" фокуснически подменяет экспериментальную проверку желаемыми, не проверенными на практике выводами, манипулируя логикообразными построениями, реально нарушающими саму логику путем использования недоказанных посылок в качестве доказанных, то есть путем подмены. Таким образом, основной задачей заявителей "мысленных экспериментов" является обман слушателя или читателя путем замены настоящего физического эксперимента его "куклой" - фиктивными рассуждениями под честное слово без самой физической проверки.
Заполнение физики воображаемыми, "мысленными экспериментами" привело к возникновению абсурдной сюрреалистической, спутанно-запутанной картины мира. Настоящий исследователь должен отличать такие "фантики" от настоящих ценностей.
Релятивисты и позитивисты утверждают, что "мысленный эксперимент" весьма полезный интрумент для проверки теорий (также возникающих в нашем уме) на непротиворечивость. В этом они обманывают людей, так как любая проверка может осуществляться только независимым от объекта проверки источником. Сам заявитель гипотезы не может быть проверкой своего же заявления, так как причина самого этого заявления есть отсутствие видимых для заявителя противоречий в заявлении.
Это мы видим на примере СТО и ОТО, превратившихся в своеобразный вид религии, управляющей наукой и общественным мнением. Никакое количество фактов, противоречащих им, не может преодолеть формулу Эйнштейна: "Если факт не соответствует теории - измените факт" (В другом варианте " - Факт не соответствует теории? - Тем хуже для факта").
Максимально, на что может претендовать "мысленный эксперимент" - это только на внутреннюю непротиворечивость гипотезы в рамках собственной, часто отнюдь не истинной логики заявителя. Соответсвие практике это не проверяет. Настоящая проверка может состояться только в действительном физическом эксперименте.
Эксперимент на то и эксперимент, что он есть не изощрение мысли, а проверка мысли. Непротиворечивая внутри себя мысль не может сама себя проверить. Это доказано Куртом Гёделем.
Понятие "мысленный эксперимент" придумано специально спекулянтами - релятивистами для шулерской подмены реальной проверки мысли на практике (эксперимента) своим "честным словом". Подробнее читайте в FAQ по эфирной физике.

|
|