
Методы минимизации приостановок работы конвейера из-за наличия в программах логических зависимостей по данным и по управлению, рассмотренные в предыдущих разделах, были нацелены на достижение идеального CPI (среднего количества тактов на выполнение команды в конвейере), равного 1. Чтобы еще больше повысить производительность процессора необходимо сделать CPI меньшим, чем 1. Однако этого нельзя добиться, если в одном такте выдается на выполнение только одна команда. Следовательно необходима параллельная выдача нескольких команд в каждом такте. Существуют два типа подобного рода машин: суперскалярные машины и VLIW-машины (машины с очень длинным командным словом). Суперскалярные машины могут выдавать на выполнение в каждом такте переменное число команд, и работа их конвейеров может планироваться как статически с помощью компилятора, так и с помощью аппаратных средств динамической оптимизации. В отличие от суперскалярных машин, VLIW-машины выдают на выполнение фиксированное количество команд, которые сформатированы либо как одна большая команда, либо как пакет команд фиксированного формата. Планирование работы VLIW-машины всегда осуществляется компилятором.
Суперскалярные машины используют параллелизм на уровне команд путем посылки нескольких команд из обычного потока команд в несколько функциональных устройств. Дополнительно, чтобы снять ограничения последовательного выполнения команд, эти машины используют механизмы внеочередной выдачи и внеочередного завершения команд, прогнозирование переходов, кэши целевых адресов переходов и условное (по предположению) выполнение команд. Возросшая сложность, реализуемая этими механизмами, создает также проблемы реализации точного прерывания.
В типичной суперскалярной машине аппаратура может осуществлять выдачу от одной до восьми команд в одном такте. Обычно эти команды должны быть независимыми и удовлетворять некоторым ограничениям, например таким, что в каждом такте не может выдаваться более одной команды обращения к памяти. Если какая-либо команда в потоке команд является логически зависимой или не удовлетворяет критериям выдачи, на выполнение будут выданы только команды, предшествующие данной. Поэтому скорость выдачи команд в суперскалярных машинах является переменной. Это отличает их от VLIW-машин, в которых полную ответственность за формирование пакета команд, которые могут выдаваться одновременно, несет компилятор, а аппаратура в динамике не принимает никаких решений относительно выдачи нескольких команд.
Предположим, что машина может выдавать на выполнение две команды в одном такте. Одной из таких команд может быть команда загрузки регистров из памяти, записи регистров в память, команда переходов, операции целочисленного АЛУ, а другой может быть любая операция плавающей точки. Параллельная выдача целочисленной операции и операции с плавающей точкой намного проще, чем выдача двух произвольных команд. В реальных системах (например, в микропроцессорах PA7100, hyperSPARC, Pentium и др.) применяется именно такой подход. В более мощных микропроцессорах (например, MIPS R10000, UltraSPARC, PowerPC 620 и др.) реализована выдача до четырех команд в одном такте.
Выдача двух команд в каждом такте требует одновременной выборки и декодирования по крайней мере 64 бит. Чтобы упростить декодирование можно потребовать, чтобы команды располагались в памяти парами и были выровнены по 64-битовым границам. В противном случае необходимо анализировать команды в процессе выборки и, возможно, менять их местами в момент пересылки в целочисленное устройство и в устройство ПТ. При этом возникают дополнительные требования к схемам обнаружения конфликтов. В любом случае вторая команда может выдаваться, только если может быть выдана на выполнение первая команда. Аппаратура принимает такие решения в динамике, обеспечивая выдачу только первой команды, если условия для одновременной выдачи двух команд не соблюдаются. На рис. 6.13 представлена диаграмма работы подобного конвейера в идеальном случае, когда в каждом такте на выполнение выдается пара команд.
| Тип команды | Ступень конвейера | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда ПТ | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| КомандаПТ | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда ПТ | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда ПТ | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 6.13. Работа суперскалярного конвейера
Такой конвейер позволяет существенно увеличить скорость выдачи команд. Однако чтобы он смог так работать, необходимо иметь либо полностью конвейеризованные устройства плавающей точки, либо соответствующее число независимых функциональных устройств. В противном случае устройство плавающей точки станет узким горлом и эффект, достигнутый за счет выдачи в каждом такте пары команд, сведется к минимуму.
При параллельной выдаче двух операций (одной целочисленной команды и одной команды ПТ) потребность в дополнительной аппаратуре, помимо обычной логики обнаружения конфликтов, минимальна: целочисленные операции и операции ПТ используют разные наборы регистров и разные функциональные устройства. Более того, усиление ограничений на выдачу команд, которые можно рассматривать как специфические структурные конфликты (поскольку выдаваться на выполнение могут только определенные пары команд), обнаружение которых требует только анализа кодов операций. Единственная сложность возникает, только если команды представляют собой команды загрузки, записи и пересылки чисел с плавающей точкой. Эти команды создают конфликты по портам регистров ПТ, а также могут приводить к новым конфликтам типа RAW, когда операция ПТ, которая могла бы быть выдана в том же такте, является зависимой от первой команды в паре.
Проблема регистровых портов может быть решена, например, путем реализации отдельной выдачи команд загрузки, записи и пересылки с ПТ. В случае составления ими пары с обычной операцией ПТ ситуацию можно рассматривать как структурный конфликт. Такую схему легко реализовать, но она будет иметь существенное воздействие на общую производительность. Конфликт подобного типа может быть устранен посредством реализации в регистровом файле двух дополнительных портов (для выборки и записи).
Если пара команд состоит из одной команды загрузки с ПТ и одной операции с ПТ, которая от нее зависит, необходимо обнаруживать подобный конфликт и блокировать выдачу операции с ПТ. За исключением этого случая, все другие конфликты естественно могут возникать, как и в обычной машине, обеспечивающей выдачу одной команды в каждом такте. Для предотвращения ненужных приостановок могут, правда потребоваться дополнительные цепи обхода.
Другой проблемой, которая может ограничить эффективность суперскалярной обработки, является задержка загрузки данных из памяти. В нашем примере простого конвейера команды загрузки имели задержку в один такт, что не позволяло следующей команде воспользоваться результатом команды загрузки без приостановки. В суперскалярном конвейере результат команды загрузки не может быть использован в том же самом и в следующем такте. Это означает, что следующие три команды не могут использовать результат команды загрузки без приостановки. Задержка перехода также становится длиною в три команды, поскольку команда перехода должна быть первой в паре команд. Чтобы эффективно использовать параллелизм, доступный на суперскалярной машине, нужны более сложные методы планирования потока команд, используемые компилятором или аппаратными средствами, а также более сложные схемы декодирования команд.
Рассмотрим, например, что дает разворачивание циклов и планирование потока команд для суперскалярного конвейера. Ниже представлен цикл, который мы уже разворачивали и планировали его выполнение на простом конвейере.
Loop: LD F0,0(R1) ;F0=элемент вектора
ADDD F4,F0,F2 ;добавление скалярной величины из F2
SD 0(R1),F4 ;запись результата
SUBI R1,R1,#8 ;декрементирование указателя
;8 байт на двойное слово
BNEZ R1,Loop ;переход R1!=нулю
Чтобы спланировать этот цикл для работы без задержек, необходимо его развернуть и сделать пять копий тела цикла. После такого разворачивания цикл будет содержать по пять команд LD, ADDD, и SD, а также одну команду SUBI и один условный переход BNEZ. Развернутая и оптимизированная программа этого цикла дана ниже:
| Целочисленная команда | Команда ПТ | Номер такта | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Loop: LD F0,0(R1) LD F8,-8(R1) LD F10,-16(R1) LD F14,-24(R1) LD F18,-32(R1) SD 0(R1),F4 SD -8(R1),F8 SD -16(R1),F12 SD -24(R1),F16 SUBI R1,R1,#40 BNEZ R1,Loop SD -32(R1),F20 |
ADDD F4,F0,F2 ADDD F8,F6,F2 ADDD F12,F10,F2 ADDD F16,F14,F2 ADDD F20,F18,F2 |
1 2 3 4 5 6 7 8 9 10 11 12 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Этот развернутый суперскалярный цикл теперь работает со скоростью 12 тактов на итерацию, или 2.4 такта на один элемент (по сравнению с 3.5 тактами для оптимизированного развернутого цикла на обычном конвейере. В этом примере производительность суперскалярного конвейера ограничена существующим соотношением целочисленных операций и операций ПТ, но команд ПТ не достаточно для поддержания полной загрузки конвейера ПТ. Первоначальный оптимизированный неразвернутый цикл выполнялся со скоростью 6 тактов на итерацию, вычисляющую один элемент. Мы получили таким образом ускорение в 2.5 раза, больше половины которого произошло за счет разворачивания цикла. Чистое ускорение за счет суперскалярной обработки дало улучшение примерно в 1.5 раза.
В лучшем случае такой суперскалярный конвейер позволит выбирать две команды и выдавать их на выполнение, если первая из них является целочисленной, а вторая - с плавающей точкой. Если это условие не соблюдается, что легко проверить, то команды выдаются последовательно. Это показывает два главных преимущества суперскалярной машины по сравнению с WLIW-машиной. Во-первых, малое воздействие на плотность кода, поскольку машина сама определяет, может ли быть выдана следующая команда, и нам не надо следить за тем, чтобы команды соответствовали возможностям выдачи. Во-вторых, на таких машинах могут работать неоптимизированные программы, или программы, откомпилированные в расчете на более старую реализацию. Конечно такие программы не могут работать очень хорошо. Один из способов улучшить ситуацию заключается в использовании аппаратных средств динамической оптимизации.
В общем случае в суперскалярной системе команды могут выполняться параллельно и возможно не в порядке, предписанном программой. Если не предпринимать никаких мер, такое неупорядоченное выполнение команд и наличие множества функциональных устройств с разными временами выполнения операций могут приводить к дополнительным трудностям. Например, при выполнении некоторой длинной команды с плавающей точкой (команды деления или вычисления квадратного корня) может возникнуть исключительная ситуация уже после того, как завершилось выполнение более быстрой операции, выданной после этой длинной команды. Для того, чтобы поддерживать модель точных прерываний, аппаратура должна гарантировать корректное состояние процессора при прерывании для организации последующего возврата.
Обычно в машинах с неупорядоченным выполнением команд предусматриваются дополнительные буферные схемы, гарантирующие завершение выполнения команд в строгом порядке, предписанном программой. Такие схемы представляют собой некоторый буфер "истории", т.е. аппаратную очередь, в которую при выдаче попадают команды и текущие значения регистров результата этих команд в заданном программой порядке.
В момент выдачи команды на выполнение она помещается в конец этой очереди, организованной в виде буфера FIFO (первый вошел - первый вышел). Единственный способ для команды достичь головы этой очереди - завершение выполнения всех предшествующих ей операций. При неупорядоченном выполнении некоторая команда может завершить свое выполнение, но все еще будет находиться в середине очереди. Команда покидает очередь, когда она достигает головы очереди и ее выполнение завершается в соответствующем функциональном устройстве. Если команда находится в голове очереди, но ее выполнение в функциональном устройстве не закончено, она очередь не покидает. Такой механизм может поддерживать модель точных прерываний, поскольку вся необходимая информация хранится в буфере и позволяет скорректировать состояние процессора в любой момент времени.
Этот же буфер "истории" позволяет реализовать и условное (speculative) выполнение команд (выполнение по предположению), следующих за командами условного перехода. Это особенно важно для повышения производительности суперскалярных архитектур. Статистика показывает, что на каждые шесть обычных команд в программах приходится в среднем одна команда перехода. Если задерживать выполнение следующих за командой перехода команд, потери на конвейеризацию могут оказаться просто неприемлемыми. Например, при выдаче четырех команд в одном такте в среднем в каждом втором такте выполняется команда перехода. Механизм условного выполнения команд, следующих за командой перехода, позволяет решить эту проблему. Это условное выполнение обычно связано с последовательным выполнением команд из заранее предсказанной ветви команды перехода. Устройство управления выдает команду условного перехода, прогнозирует направление перехода и продолжает выдавать команды из этой предсказанной ветви программы.
Если прогноз оказался верным, выдача команд так и будет продолжаться без приостановок. Однако если прогноз был ошибочным, устройство управления приостанавливает выполнение условно выданных команд и, если необходимо, использует информацию из буфера истории для ликвидации всех последствий выполнения условно выданных команд. Затем начинается выборка команд из правильной ветви программы. Таким образом, аппаратура, подобная буферу, истории позволяет не только решить проблемы с реализацией точного прерывания, но и обеспечивает увеличение производительности суперскалярных архитектур.
Архитектура машин с очень длинным командным словом (VLIW Very - Long Instruction Word) позволяет сократить объем оборудования, требуемого для реализации параллельной выдачи нескольких команд, и потенциально чем большее количество команд выдается параллельно, тем больше эта экономия. Например, суперскалярная машина, обеспечивающая параллельную выдачу двух команд, требует параллельного анализа двух кодов операций, шести полей номеров регистров, а также того, чтобы динамически анализировалась возможность выдачи одной или двух команд и выполнялось распределение этих команд по функциональным устройствам. Хотя требования по объему аппаратуры для параллельной выдачи двух команд остаются достаточно умеренными, и можно даже увеличить степень распараллеливания до четырех (что применяется в современных микропроцессорах), дальнейшее увеличение количества выдаваемых параллельно для выполнения команд приводит к нарастанию сложности реализации из-за необходимости определения порядка следования команд и существующих между ними зависимостей.
Архитектура VLIW базируется на множестве независимых функциональных устройств. Вместо того, чтобы пытаться параллельно выдавать в эти устройства независимые команды, в таких машинах несколько операций упаковываются в одну очень длинную команду. При этом ответственность за выбор параллельно выдаваемых для выполнения операций полностью ложится на компилятор, а аппаратные средства, необходимые для реализации суперскалярной обработки, просто отсутствуют.
WLIW-команда может включать, например, две целочисленные операции, две операции с плавающей точкой, две операции обращения к памяти и операцию перехода. Такая команда будет иметь набор полей для каждого функционального устройства, возможно от 16 до 24 бит на устройство, что приводит к команде длиною от 112 до 168 бит.
Рассмотрим работу цикла инкрементирования элементов вектора на подобного рода машине в предположении, что одновременно могут выдаваться две операции обращения к памяти, две операции с плавающей точкой и одна целочисленная операция либо одна команда перехода. На рис. 6.14 показан код для реализации этого цикла. Цикл был развернут семь раз, что позволило устранить все возможные приостановки конвейера. Один проход по циклу осуществляется за 9 тактов и вырабатывает 7 результатов. Таким образом, на вычисление каждого результата расходуется 1.28 такта (в нашем примере для суперскалярной машины на вычисление каждого результата расходовалось 2.4 такта).
Для машин с VLIW-архитектурой был разработан новый метод планирования выдачи команд, названный "трассировочным планированием". При использовании этого метода из последовательности исходной программы генерируются длинные команды путем просмотра программы за пределами базовых блоков. Как уже отмечалось, базовый блок - это линейный участок программы без ветвлений.
С точки зрения архитектурных идей машину с очень длинным командным словом можно рассматривать как расширение RISC-архитектуры. Как и в RISC-архитектуре аппаратные ресурсы VLIW-машины предоставлены компилятору, и ресурсы планируются статически. В машинах с очень длинным командным словом к этим ресурсам относятся конвейерные функциональные устройства, шины и банки памяти. Для поддержки высокой пропускной способности между функциональными устройствами и регистрами необходимо использовать несколько наборов регистров. Аппаратное разрешение конфликтов исключается и предпочтение отдается простой логике управления. В отличие от традиционных машин регистры и шины не резервируются, а их использование полностью определяется во время компиляции.
| Обращение к памяти 1 |
Обращение к памяти 2 |
Операция ПТ 1 | Операция ПТ 2 | Целочисленная операция/ переход |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LD F0,0(R1) LD F10,-16(R1) LD F18,-32(R1) LD F26,-48(R1) SD 0(R1),F4 SD -16(R1),F12 SD -32(R1),F20 SD 0(R1),F28 |
LD F6,-8(R1) LD F14,-24(R1) LD F22,-40(R1) SD -8(R1),F8 SD -24(R1),F16 SD -40(R1),F24 |
ADDD F4,F0,F2 ADDD F12,F10,F2 ADDD F20,F18,F2 ADDD F28,F26,F2 |
ADDD F8,F6,F2 ADDD F16,F14,F2 ADDD F24,F22,F2 |
SUBI R1,R1,#48 BNEZ R1,Loop |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 6.14.
В машинах типа VLIW, кроме того, этот принцип замены управления во время выполнения программы планированием во время компиляции распространен на системы памяти. Для поддержания занятости конвейерных функциональных устройств должна быть обеспечена высокая пропускная способность памяти. Одним из современных подходов к увеличению пропускной способности памяти является использование расслоения памяти. Однако в системе с расслоенной памятью возникает конфликт банка, если банк занят предыдущим обращением. В обычных машинах состояние занятости банков памяти отслеживается аппаратно и проверяется, когда выдается команда, выполнение которой связано с обращением к памяти. В машине типа VLIW эта функция передана программным средствам. Возможные конфликты банков определяет специальный модуль компилятора - модуль предотвращения конфликтов.
Обнаружение конфликтов не является задачей оптимизации, это скорее функция контроля корректности выполнения операций. Компилятор должен быть способен определять, что конфликты невозможны или, в противном случае, допускать, что может возникнуть наихудшая ситуация. В определенных ситуациях, например, в том случае, когда производится обращение к массиву, а индекс вычисляется во время выполнения программы, простого решения здесь нет. Если компилятор не может определить, что конфликт не произойдет, операции не могут планироваться для параллельного выполнения, а это ведет к снижению производительности.
Компилятор с трассировочным планированием определяет участок программы без обратных дуг (переходов назад), которая становится кандидатом для составления расписания. Обратные дуги обычно имеются в программах с циклами. Для увеличения размера тела цикла широко используется методика раскрутки циклов, что приводит к образованию больших фрагментов программы, не содержащих обратных дуг. Если дана программа, содержащая только переходы вперед, компилятор делает эвристическое предсказание выбора условных ветвей. Путь, имеющий наибольшую вероятность выполнения (его называют трассой), используется для оптимизации, проводимой с учетом зависимостей по данным между командами и ограничений аппаратных ресурсов. Во время планирования генерируется длинное командное слово. Все операции длинного командного слова выдаются одновременно и выполняются параллельно.
После обработки первой трассы планируется следующий путь, имеющий наибольшую вероятность выполнения (предыдущая трасса больше не рассматривается). Процесс упаковки команд последовательной программы в длинные командные слова продолжается до тех пор, пока не будет оптимизирована вся программа.
Ключевым условием достижения эффективной работы VLIW-машины является корректное предсказание выбора условных ветвей. Отмечено, например, что прогноз условных ветвей для научных программ часто оказывается точным. Возвраты назад имеются во всех итерациях цикла, за исключением последней. Таким образом, "прогноз", который уже дается самими переходами назад, будет корректен в большинстве случаев. Другие условные ветви, например ветвь обработки переполнения и проверки граничных условий (выход за границы массива), также надежно предсказуемы.
В этом разделе мы обсудим методы компиляции, которые позволяют увеличить степень параллелизма, который можно использовать при выполнении программы. Мы начнем с изучения методов обнаружения зависимостей и устранения зависимостей по именам.
Обнаружение и устранение зависимостей
Нахождение зависимостей по данным в программе является важной частью трех задач: (1) хорошее планирование программного кода, (2) определение циклов, которые могут содержать параллелизм, и (3) устранение зависимостей по именам. Сложность анализа зависимостей связана с наличием массивов (и указателей в языках, подобных языку Си). Поскольку обращения к скалярным переменным осуществляется явно по имени, они обычно могут анализироваться достаточно просто. При этом наличие указателей-алиасов и обращений к параметрам вызывает усложнения, поскольку они могут быть неизвестны в процессе анализа.
При анализе необходимо найти все зависимости и определить, имеется ли цикл в этих зависимостях, поскольку это то, что не позволяет нам выполнять цикл параллельно. Рассмотрим следующий пример:
for (i=1;i<=100;i=i+1) {
A[i] = B[i] + C[i];
D[i] = A[i] + E[i];
}
Поскольку в данном случае зависимость, связанная с А, не приводит к зависимости между итерациями цикла, можно развернуть цикл для выявления большей степени параллелизма. Мы не можем прямо поменять местами два обращения к А. Если цикл имеет зависимости между итерациями, которые не являются циклическими, можно сначала преобразовать цикл для устранения этих зависимостей, а затем развернуть цикл для выявления большей степени параллелизма. Во многих параллельных циклах степень параллелизма ограничена только количеством разворотов цикла, которое в свою очередь ограничивается только количеством итераций цикла. Конечно на практике, чтобы получить выигрыш от этой большей степени параллелизма, потребуется много функциональных устройств и огромное количество регистров. Отсутствие зависимости между итерациями цикла просто сообщает нам, что нам доступна большая степень параллелизма.
Фрагмент вышеприведенного кода иллюстрирует также другую возможность для улучшения машинного кода. Второе обращение к А не нужно транслировать в команду загрузки из памяти, поскольку мы знаем, что значение вычислено и записано предыдущим оператором. Поэтому второе обращение к А может выполняться с помощью обращения к регистру, в котором значение А было вычислено. Выполнение этой оптимизации требует знания того, что два обращения всегда относятся к одному и тому же адресу памяти, и что к той же самой ячейке между этими двумя обращениями другие обращения (по записи) отсутствуют. Обычно анализ зависимостей по данным дает информацию только о том, что одно обращение может зависеть от другого. Для определения того, что два обращения должны выполняться точно по одному и тому же адресу, требуется более сложный анализ. В вышеприведенном примере достаточно простейшей версии такого анализа, поскольку оба обращения находятся в одном и том же базовом блоке.
Часто зависимости между итерациями цикла появляются в форме рекуррентного отношения:
for (i=2;i<=100;i=i+1) {
Y[i] = Y[i-1] + Y[i];
}
Определение наличия рекуррентных отношений может оказаться важным по двум причинам. Некоторые архитектуры (особенно векторные машины) имеют специальную поддержку для выполнения рекуррентных отношений и некоторые рекуррентные отношения могут быть источником значительной степени параллелизма. Например, рассмотрим цикл:
for (i=6;i<=100;i=i+1) {
Y[i] = Y[i-5] + Y[i];
}
На итерации j цикл обращается к элементу j-5. Говорят, что цикл имеет зависимость с расстоянием 5. Предыдущий цикл имел зависимость с расстоянием 1. Чем больше расстояние, тем больше степень потенциального параллелизма, которую можно получить при помощи разворачивания цикла. Например, если мы разворачиваем первый цикл, имеющий зависимость с расстоянием 1, последовательные операторы зависят друг от друга; имеется некоторая степень параллелизма между отдельными командами, но не очень большая. Если мы разворачиваем цикл, который имеет зависимость с расстоянием 5, то имеется последовательность пяти команд, которые не имеют зависимостей, и тем самым обладают значительно большей степенью параллелизма уровня команд. Хотя многие циклы с зависимостями между итерациями имеют расстояние зависимостей 1, случаи с большими расстояниями в действительности возникают, и большее расстояние между зависимостями может обеспечивать достаточную степень параллелизма для поддержания машины занятой.
Как вообще компилятор обнаруживает зависимости? Почти все алгоритмы анализа зависимостей работают с предположением, что обращения к массивам являются аффинными. В простейшем случае индекс одномерного массива является аффинным, если он может быть записан в форме: a ( i + b, где a и b константы, а i - переменная индекса цикла. Индекс многомерного массива является аффинным, если индекс по каждой размерности является аффинным.
Таким образом, определение факта наличия зависимостей между двумя обращениями к одному и тому же массиву в цикле сводится к определению того, что две аффинные функции могут иметь одно и то же значение для различных индексов между границами цикла. Например, предположим, что мы выполнили запись в элемент массива со значением индекса a ( i + b, и выполняем загрузку из того же массива со значением индекса c ( i + d, где i - переменная индекса цикла for, которая меняется в пределах от m до n. Зависимость существует, если имеют место два условия:
В общем случае во время компиляции мы не можем определить, имеет ли место зависимость. Например, значения a, b, c и d могут быть неизвестными (они могут быть значениями другого массива), а, следовательно, невозможно сказать, что зависимость существует. В других случаях проверка зависимостей может оказаться очень дорогой, но в принципе возможной во время компиляции. Например, обращения могут зависеть от индексов итераций множества вложенных циклов. Однако многие программы содержат в основном простые индексы, где a, b, c и d все являются константами. Для этих случаев возможно придумать недорогие тесты для обнаружения зависимостей.
Например, простым и достаточным тестом отсутствия зависимостей является наибольший общий делитель, или тест НОД. Он основан на том, что если существует зависимость между итерациями цикла, то НОД(c,a) должен делить (d-b). (Вспомним, что целое x делит другое целое y, если отсутствует остаток от деления y/x). Тест НОД является достаточным, чтобы гарантировать, что зависимости отсутствуют. Однако имеются случаи, когда тест НОД достигает цели, но в реальной программе зависимость отсутствует. Это может возникнуть, например, поскольку тест НОД не рассматривает границы цикла.
В общем случае задача определения действительного наличия зависимостей является NP-полной. Однако на практике многие частые случаи могут быть точно проанализированы при вполне умеренных затратах. (Тест является точным, если он точно определяет наличие зависимости. Хотя общий случай является NP-полным (т.е. точное решение возможно найти путем полного перебора всех вариантов), имеются точные тесты для ограниченного числа ситуаций, которые являются намного более дешевыми).
Кроме определения наличия зависимостей, компилятор старается также классифицировать тип зависимости. Это позволяет компилятору распознать зависимости по именам и устранить их путем переименования и копирования.
Например, следующий цикл имеет несколько типов зависимостей. Попробуем найти все истинные зависимости, зависимости по выходу и антизависимости и устранить зависимости по выходу и антизависимости с помощью переименования.
for (i=1;i<=100;i=i+1) {
Y[i] = X[i] / c; /*S1*/
X[i] = X[i] + c; /*S2*/
Z[i] = Y[i] + c; /*S3*/
Y[i] = c - Y[i]; /*S4*/
}
В этих четырех операторах имеются следующие зависимости:
Следующая версия цикла устраняет эти ложные (или псевдо-) зависимости.
for (i=1;i<=100;i=i+1) {
/* Y переименовывается в T для устранения
зависимости по выходу */
T[i] = X[i] / c;
/* X переименовывается в X1 для устранения
антизависимости */
X1[i] = X[i] + c;
Z[i] = T[i] + c;
Y[i] = c - T[i];
}
После цикла переменная X оказалась переименованной в X1. В коде программы, следующем за циклом, компилятор просто может заменить имя X на имя X1. В данном случае переименование не требует действительной операции копирования, а может быть выполнено с помощью заменяющего имени или соответствующего распределения регистров. Однако в других случаях переименование может потребовать копирования.
Анализ зависимостей является важнейшей технологией для улучшения использования параллелизма. На уровне команд она дает информацию, необходимую для изменения в процессе планирования порядка обращений к памяти, а также для определения полезности разворачивания цикла. Для обнаружения параллелизма уровня цикла анализ зависимостей является базовым инструментом. Эффективная компиляция программ для векторных машин, а также для мультипроцессоров существенно зависит от этого анализа. Кроме того, при планировании потока команд полезно определить, являются ли потенциально зависимыми обращения к памяти. Главный недостаток анализа зависимостей заключается в том, что он применим при ограниченном наборе обстоятельств, а именно к обращениям внутри одного гнезда циклов и использует аффинные функции индексов. Таким образом, имеется огромное многообразие ситуаций, при которых анализ зависимостей не может сообщить нам то, что мы хотели бы знать, а именно:
Программная конвейеризация: символическое разворачивание циклов
Мы уже видели, что один из методов компиляции - разворачивание циклов - полезен для увеличения степени параллелизма на уровне команд посредством создания более длинных последовательностей линейного кода. Имеются два других важных метода, которые разработаны для этих целей: программная конвейеризация и планирование трасс.
Программная конвейеризация - это метод реорганизации циклов таким образом, что каждая итерация в программно конвейеризованном коде составляется из команд, выбранных из разных итераций первоначального цикла. Планировщик по существу чередует команды из разных итераций цикла так, чтобы отдалить друг от друга зависимые команды, которые возникают в одной итерации цикла. Программно конвейеризованный цикл чередует команды из разных итераций без реального разворачивания цикла (рис. 6.15). Этот метод по существу программно выполняет то, что алгоритм Томасуло делает с помощью аппаратных средств. Программно конвейеризованный цикл будет содержать по одной команде, каждая из которых относится к разным итерациям. Для начального запуска цикла (пролог цикла) и для завершения цикла (эпилог цикла) требуются некоторые команды.
Рис. 6.15. Программная конвейеризация
Например, рассмотрим программно конвейеризованную версию нижеприведенного цикла, который складывает с содержимым регистра F2 все элементы некоторого массива с начальным адресом, хранящимся в регистре R1.
Loop: LD F0,0(R1)
ADDD F4,F0,F2
SD 0(R1),F4
SUBI R1,R1,#8
BNEZ R1, Loop
Игнорируя пролог и эпилог мы можем переписать цикл следующим образом:
Loop: SD 0(R1),F4 ; записывает в M[i]
ADDD F4,F0,F2 ; складывает с M[i-1]
LD F0,-16(R1); загружает M[i-2]
BNEZ R1, Loop
SUBI R1,R1,#8 ; вычитает в слоте задержки
Если не принимать во внимание пролог и эпилог, этот цикл может работать со скоростью 5 тактов на один проход. Поскольку команда загрузки осуществляет выборку на расстоянии двух элементов от счетчика цикла, цикл должен выполнять на две итерации меньше. При этом перед началом цикла из содержимого регистра R1 необходимо вычесть 16. Заметим, что повторное использование регистров (например, F4, F0 и R1) требует использования специальных аппаратных средств, чтобы обойти конфликты типа WAR и приостановки конвейера. В данном случае это не должно привести к каким-либо проблемам, поскольку никаких приостановок по причине зависимостей по данным произойти не должно.
Управление регистрами в программно конвейеризуемых циклах может быть достаточно сложным. Вышеприведенный пример не слишком тяжелый, поскольку в регистры выполняется запись в одной итерации, а их чтение происходит в следующей. В других случаях может потребоваться увеличить количество итераций между моментом выдачи команды и моментом, когда используется ее результат. Это происходит, когда в теле цикла имеется небольшое количество команд, а задержки их выполнения достаточно большие. В этих случаях требуется комбинация методов программной конвейеризации и разворачивания цикла.
Программную конвейеризацию можно рассматривать как символическое разворачивание цикла. Действительно, некоторые алгоритмы программной конвейеризации используют разворачивание цикла в качестве исходного материала для расчета (вычисления) выполнения программной конвейеризации. Главное преимущество программной конвейеризации по отношению к прямому разворачиванию циклов заключается в том, что первая генерирует в результате меньший по размеру программный код. Программная конвейеризация и разворачивание циклов в дополнение к тому, что они дают лучше спланированный внутренний цикл, сами по себе сокращают разные типы накладных расходов. Разворачивание циклов сокращает накладные расходы на организацию цикла, связанные с командами перехода и изменения значения счетчика циклов. Программная конвейеризация сокращает время, когда цикл не работает с полной скоростью, что происходит только однажды в начале и в конце цикла. Если мы разворачиваем цикл, который выполняет 100 итераций постоянное количество раз, скажем 4 раза, мы будем иметь накладные расходы 100/4=25 раз - каждый раз, когда будет инициироваться внутренний развернутый цикл. На рис. 6.16 это поведение показано графически. Поскольку эти методы направлены на два различных типа накладных расходов, наилучший результат может быть получен при использовании обоих методов.
Другим методом, используемым для выделения дополнительного параллелизма, является трассировочное планирование. Трассировочное планирование расширяет метод разворачивания циклов методикой для нахождения параллелизма в программах с условными переходами, не связанными с организацией циклов. Трассировочное планирование полезно для машин с очень большим количеством команд, выдаваемых для выполнения в одном такте, где одного разворачивания циклов может оказаться недостаточно для выявления необходимой степени параллелизма уровня команд для поддержания машины в занятом состоянии. Трассировочное планирование является комбинацией двух отдельных процессов. Первый процесс, который называется выбором трассы (trace selection), старается найти возможную последовательность базовых блоков, операции которых будут собираться вместе в меньшее количество команд; эта последовательность называется трассой. Разворачивание циклов используется для генерации длинных трасс, поскольку переходы циклов выполняются с высокой вероятностью. Дополнительно при использовании статического прогнозирования направления переходов другие условные переходы (не связанные с организацией цикла) также выбираются как выполняемые или как невыполняемые, так что результирующая трасса представляет собой линейную последовательность, полученную в результате конкатенации (объединения) многих базовых блоков. Когда трасса выбрана, другой процесс, называемый уплотнением трассы (trace compaction), старается сжать трассу в небольшое количество широких команд. Процесс уплотнения трасс пытается перенести операции как можно ближе к началу последовательности (трассы), упаковывая операции насколько это возможно в минимальное количество широких команд (или пакетов для выдачи).
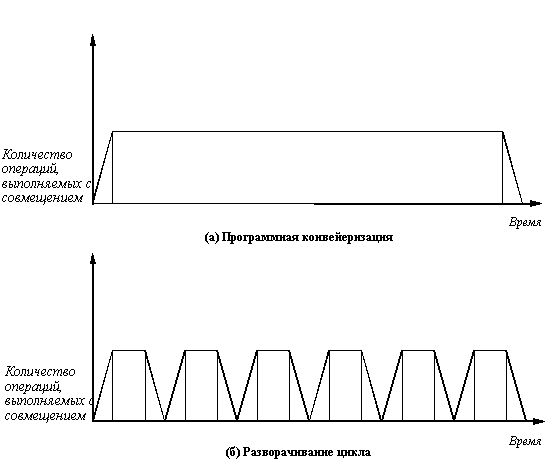
Рис. 6.16.
Уплотнение трассы представляет собой процесс глобального планирования кода. Имеются два разных ограничения, которые возникают и должны обрабатываться любой схемой глобальной оптимизации кода: зависимости по данным, которые задают определенный порядок операций, и точки условного перехода, которые создают места, через которые команды не могут просто перемещаться. По существу код должен быть уплотненным в наиболее короткую последовательность, которая сохраняет зависимости по данным и по управлению. Зависимости по данным преодолеваются посредством разворачивания циклов и использования анализа зависимостей для определения того, относятся ли два обращения к одному и тому же адресу. Зависимости по управлению также сокращаются при разворачивании циклов. Главным преимуществом методики трассировочного планирования по сравнению с более простым методом планирования загрузки конвейера заключается в том, что она обеспечивает схему для снижения эффекта зависимостей по управлению посредством переноса команд через условные переходы, не связанные с циклами, используя прогнозируемое поведение переходов. На рис. 6.17 показаны фрагмент кода, который может рассматриваться как итерация развернутого цикла, и выбранная трасса.

Рис. 6.17. Фрагмент кода с выбранной трассой
Когда трасса, как показано на рис. 6.17, выбрана, она должна быть уплотнена так, чтобы заполнить машинный ресурс. Уплотнение трассы приводит к перемещению операторов присваиваний переменным B и C вверх по блоку, чтобы разместить их перед точкой решения о направлении перехода. Любая схема глобального планирования, включая трассировочное планирование, выполняет такое перемещение команд при наличии набора ограничений. В трассировочном планировании условные переходы рассматриваются как безусловные переходы во внутрь или во вне выбранной трассы, которая предполагалась как наиболее вероятный путь. Когда команды перемещаются через такие точки входа и выхода трассы, во входной и выходной точке могут потребоваться дополнительные команды. Главное предположение состоит в том, что выбранная трасса является наиболее вероятным событием, в противном случае стоимость дополнительной работы (дополнительных команд) может оказаться чрезмерной.
Что включает в себя процесс перемещения присваиваний B и C? Вычисление и присваивание B является зависимым по управлению от условного перехода, а вычисление C нет. Перемещение этих операторов может быть выполнено только, если ни один из них не меняет зависимость по управлению или по данным, или эффект от изменения зависимости не виден и тем самым не приводит к изменению выполнения программы. Рассмотрим типичную последовательность генерации кода для диаграммы на рис. 6.16. Ниже представлена такая последовательность в предположении, что адреса для A, B и C находятся в регистрах R1, R2 и R3 соответственно:
LW R4,0(R1) ;загрузка A[i]
ADDI R4,R4,... ;добавление к A[i]
SW 0(R1),R4 ;запись в A[i]
...
BNEZ R4,elsepart ;проверка A[i]
... ;часть then
SW 0(R2),... ;запись в B[i]
J join ;прыжок через else
elsepart: ... ;часть else
X ;код для X
...
join: ... ;после if
SW 0(R3),... ;запись в C[i]
Сначала рассмотрим проблему перемещения операции присваивания B на место перед командой BNEZ. Поскольку B зависит по управлению от того перехода, перед которым мы ее хотим расположить, и не будет зависеть от него после перемещения, необходимо гарантировать, что выполнение оператора не может вызвать появление исключительной ситуации, поскольку такая исключительная ситуация не могла возникнуть в первоначальной программе, если бы была выбрана часть else условного оператора. Перемещение B не должно также воздействовать на поток данных. Чтобы более ясно определить требования, нам нужна концепция живучести переменной. Переменная Z живет в операторе, если имеется путь выполнения от этого оператора до использования переменной Z, на котором нового присваивания переменной Z не делается. На интуитивном уровне, переменная живет в операторе, если добавление операции присваивания этой переменной в операторе может изменить семантику программы.
Возвращаясь к нашему примеру, можно видеть, что имеются два возможных случая, когда перемещение B может изменить поток данных в этой программе:
В обоих случаях перемещение операции присваивания переменной B приведет к тому, что некоторая команда i (либо в X, либо далее в программе) станет зависимой по данным от этой перемещенной команды, а не от более ранней операции присваивания B, которая выполняется перед циклом и от которой i первоначально зависела. Поскольку это приведет к изменению результата программы, операция присваивания B не может быть перемещена в случае, если справедливо любое из приведенных выше условий. Можно представить себе более изощренные схемы: например, в первом случае перед оператором if можно сделать теневую копию B и использовать только эту теневую копию в X. Такие схемы в общем случае не используются, поскольку, во-первых, их сложно реализовать, и, во-вторых, поскольку они будут замедлять программу, если выбранная трасса не оптимальна и завершение операций требует выполнения дополнительных команд.
Для перемещения операции присваивания C на место сразу за первым условным переходом требуется, чтобы она переместилась выше точки объединения трассы (входа трассы) с направлением else. Это делает команды для C зависимыми по управлению от условного перехода и означает, что они не будут выполняться, если выбран путь else, который не находится на трассе. Поэтому будут затронуты команды, которые были зависимыми по данным от присваивания C и которые выполняются после этого кодового фрагмента. Для обеспечения вычисления корректного значения для этих команд делается копия команд, которые вычисляют и присваивают значение C на переходе на трасе, а именно в конце X на пути else. Мы можем переместить C из ветви then перехода через условие перехода, если это не воздействует ни на какой поток данных в условии перехода. Если C перемещается на место перед проверкой условия if, копия C в части else перехода может быть ликвидирована.
Все рассмотренные методы: разворачивание цикла, планирование трасс и программная конвейеризация стараются увеличить степень параллелизма уровня команд, который может использоваться машиной, выдающей для выполнения более одной команды в каждом такте. Эффективность каждого из этих методов и их удобство для различных архитектурных подходов являются наиболее горячими темами, которыми активно занимаются исследователи и разработчики высокоскоростных процессоров.
Методы, подобные разворачиванию циклов и планированию трасс, могут использоваться для увеличения степени доступного параллелизма, когда поведение условных переходов достаточно предсказуемо во время компиляции. Если же поведение переходов не известно, одной техники компиляторов может оказаться не достаточно для выявления большей степени параллелизма уровня команд. В этом разделе представлены два метода, которые могут помочь преодолеть подобные ограничения. Первый метод заключается в расширении набора команд условными или предикатными командами. Такие команды могут использоваться для ликвидации условных переходов и помогают компилятору перемещать команды через точки условных переходов. Условные команды увеличивают степень параллелизма уровня команд, но имеют существенные ограничения. Для использования большей степени параллелизма разработчики исследовали идею, которая называется "выполнением по предположению" (speculation), и позволяет выполнить команду еще до того, как процессор узнает, что она должна выполняться (т.е. этот метод позволяет избежать приостановок конвейера, связанных с зависимостями по управлению).
Условные команды
Концепция, лежащая в основе условных команд, достаточно проста: команда обращается к некоторому условию, оценка которого является частью выполнения команды. Если условие истинно, то команда выполняется нормально; если условие ложно, то выполнение команды осуществляется, как если бы это была пустая команда. Многие новейшие архитектуры включают в себя ту или иную форму условных команд. Наиболее общим примером такой команды является команда условной пересылки, которая выполняет пересылку значения одного регистра в другой, если условие истинно. Такая команда может использоваться для полного устранения условных переходов в простых последовательностях программного кода.
Например, рассмотрим следующий оператор:
if (A=0) {S=T;};
Предполагая, что регистры R1, R2 и R3 хранят значения A, S и T соответственно, представим код этого оператора с командой условного перехода и с командой условной пересылки.
Код с использованием команды условного перехода будет иметь следующий вид:
BEQZ R1,L
MOV R2,R3
L:
Используя команду условной пересылки, которая выполняет пересылку только если ее третий операнд равен нулю, мы можем реализовать этот оператор с помощью одной команды:
CMOVZ R2,R3,R1
Условная команда позволяет преобразовать зависимость по управлению, присутствующую в коде с командой условного перехода, в зависимость по данным. (Это преобразование используется также в векторных машинах, в которых оно называется if-преобразованием (if-convertion)). Для конвейерной машины такое преобразование позволяет перенести точку, в которой должна разрешаться зависимость, от начала конвейера, где она разрешается для условных переходов, в конец конвейера, где происходит запись в регистр.
Одним из примеров использования команд условной пересылки является реализация функции вычисления абсолютного значения: A = abs (B), которая реализуется оператором
if (B<0) {A=-B} else {A=B}.
Этот оператор if может быть реализован парой команд условных пересылок или командой безусловной пересылки (A=B), за которой следует команда условной пересылки (A=-B).
Условные команды могут использоваться также для улучшения планирования в суперскалярных или VLIW-процессорах. Ниже приведен пример кодовой последовательности для суперскалярной машины с одновременной выдачей для выполнения не более двух команд. При этом в каждом такте может выдаваться комбинация одной команды обращения к памяти и одной команды АЛУ или только одна команда условного перехода:
LW R1,40(R2) ADD R3,R4,R5
ADD R6,R3,R7
BEQZ R10,L
LW R8,20(R10)
LW R9,0(R8)
Эта последовательность теряет слот операции обращения к памяти во втором такте и приостанавливается из-за зависимости по данным, если переход невыполняемый, поскольку вторая команда LW после перехода зависит от предыдущей команды загрузки. Если доступна условная версия команды LW, то команда LW, немедленно следующая за переходом (LW R8,20(R10)), может быть перенесена во второй слот выдачи. Это улучшает время выполнения на несколько тактов, поскольку устраняет один слот выдачи команды и сокращает приостановку конвейера для последней команды последовательности.
Для успешного использования условных команд в примерах, подобных этому, семантика команды должна определять команду таким образом, чтобы не было никакого побочного эффекта, если условие не выполняется. Это означает, что если условие не выполняется, команда не должна записывать результат по месту назначения, а также не должна вызывать исключительную ситуацию. Как показывает вышеприведенный пример, способность не вызывать исключительную ситуацию достаточно важна: если регистр R10 содержит нуль, команда LW R8,20(R10), выполненная безусловно, возможно вызовет исключительную ситуацию по защите памяти, а эта исключительная ситуация не должна возникать. Именно эта вероятность возникновения исключительной ситуации не дает возможность компилятору просто перенести команду загрузки R8 через команду условного перехода. Конечно, если условие удовлетворено, команда LW все еще может вызвать исключительную ситуацию (например, ошибку страницы), и аппаратура должна воспринять эту исключительную ситуацию, поскольку она знает, что управляющее условие истинно.
Условные команды определенно полезны для реализации коротких альтернативных потоков управления. Тем не менее полезность условных команд существенно ограничивается несколькими факторами:
По этим причинам во многих современных архитектурах используется небольшое число условных команд (наиболее популярными являются команды условных пересылок), хотя некоторые из них включают условные версии большинства команд (рис. 6.18).
| Alpha | HP-PA | MIPS | PowerPC | SPARC | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Условная пересылка | Любая команда типа регистр-регистр может аннулировать следующую команду, делая ее условной | Условная пересылка |
Условная пересылка | Условная пересылка | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 6.18. Условные команды в современных архитектурах
Выполнение по предположению (speculation)
Поддерживаемое аппаратурой выполнение по предположению позволяет выполнить команду до момента определения направления условного перехода, от которого данная команда зависит. Это снижает потери, которые возникают при наличии в программе зависимостей по управлению. Чтобы понять, почему выполнение по предположению оказывается полезным, рассмотрим следующий простой пример программного кода, который реализует проход по связанному списку и инкрементирование каждого элемента этого списка:
for (p=head; p <> nil; *p=*p.next) {
*p.value = *p.value+1;
}
Подобно циклам for, с которыми мы встречались в более ранних разделах, разворачивание этого цикла не увеличит степени доступного параллелизма уровня команд. Действительно, каждая развернутая итерация будет содержать оператор if и выход из цикла. Ниже приведена последовательность команд в предположении, что значение head находится в регистре R4, который используется для хранения p, и что каждый элемент списка состоит из поля значения и следующего за ним поля указателя. Проверка размещается внизу так, что на каждой итерации цикла выполняется только один переход.
J looptest
start: LW R5,0(R4)
ADDI R5,R5,#1
SW 0(R4),R5
LW R4,4(R4)
looptest: BNEZ R4,start
Развернув цикл однажды можно видеть, что разворачивание в данном случае не помогает:
J looptest
start: LW R5,0(R4)
ADDI R5,R5,#1
SW 0(R4),R5
LW R4,4(R4)
BNEZ R4,end
LW R5,0(R4)
ADDI R5,R5,#1
SW 0(R4),R5
LW R4,4(R4)
looptest: BNEZ R4,start
end:
Даже прогнозируя направление перехода мы не можем выполнять с перекрытием команды из двух разных итераций цикла, и условные команды в любом случае здесь не помогут. Имеются несколько сложных моментов для выявления параллелизма из этого развернутого цикла:
В альтернативном варианте, при выполнении по предположению, что переход не будет выполняться, мы можем попытаться совместить выполнение последовательных итераций цикла. Действительно, это в точности то, что делает компилятор с планированием трасс. Когда направление переходов может прогнозироваться во время компиляции, и компилятор может найти команды, которые он может безопасно перенести на место перед точкой перехода, решение, базирующееся на технологии компилятора, идеально. Эти два условия являются ключевыми ограничениями для выявления параллелизма уровня команд статически с помощью компилятора. Рассмотрим развернутый выше цикл. Переход просто трудно прогнозируем, поскольку частота, с которой он является выполняемым, зависит от длины списка, по которому осуществляется проход. Кроме того, мы не можем безопасно перенести команду загрузки через переход, поскольку, если содержимое R4 равно nil, то команда загрузки слова, которая использует R4 как базовый регистр, гарантированно приведет к ошибке и обычно сгенерирует исключительную ситуацию по защите. Во многих системах значение nil реализуется с помощью указателя на неиспользуемую страницу виртуальной памяти, что обеспечивает ловушку (trap) при обращении по нему. Такое решение хорошо для универсальной схемы обнаружения указателей на nil, но в данном случае это не очень помогает, поскольку мы можем регулярно генерировать эту исключительную ситуацию, и стоимость обработки исключительной ситуации плюс уничтожения результатов выполнения по предположению будет огромной.
Чтобы преодолеть эти сложности, машина может иметь в своем составе специальные аппаратные средства поддержки выполнения по предположению. Эта методика позволяет машине выполнять команду, которая может быть зависимой по управлению, и избежать любых последствий выполнения этой команды (включая исключительные ситуации), если окажется, что в действительности команда не должна выполняться. Таким образом выполнение по предположению, подобно условным командам, позволяет преодолеть два сложных момента, которые могут возникнуть при более раннем выполнении команд: возможность появления исключительной ситуации и ненужное изменение состояния машины, вызванное выполнением команды. Кроме того, механизмы выполнения по предположению позволяют выполнять команду даже до момента оценки условия командой условного перехода, что невозможно при условных командах. Конечно, аппаратная поддержка выполнения по предположению достаточно сложна и требует значительных аппаратных ресурсов.
Один из подходов, который был хорошо исследован во множестве исследовательских проектов и используется в той или иной степени в машинах, которые разработаны или находятся на стадии разработки в настоящее время, заключается в объединении аппаратных средств динамического планирования и выполнения по предположению. В определенной степени подобную работу делала и IBM 360/91, поскольку она могла использовать средства прогнозирования направления переходов для выборки команд и назначения этих команд на станции резервирования. Механизмы, допускающие выполнение по предположению, идут дальше и позволяют действительно выполнять эти команды, а также другие команды, зависящие от команд, выполняющихся по предположению. Как и для алгоритма Томасуло, поясним аппаратное выполнение по предположению на примере устройства плавающей точки, но все идеи естественно применимы и для целочисленного устройства.
Аппаратура, реализующая алгоритм Томасуло, может быть расширена для обеспечения поддержки выполнения по предположению. С этой целью необходимо отделить средства пересылки результатов команд, которые требуются для выполнения по предположению некоторой команды, от механизма действительного завершения команды. Имея такое разделение функций, мы можем допустить выполнение команды и пересылать ее результаты другим командам, не позволяя ей однако делать никакие обновления состояния машины, которые не могут быть ликвидированы, до тех пор, пока мы не узнаем, что команда должна безусловно выполниться. Использование цепей ускоренной пересылки также подобно выполнению по предположению чтения регистра, поскольку мы не знаем, обеспечивает ли команда, формирующая значение регистра-источника, корректный результат до тех пор, пока ее выполнение не станет безусловным. Если команда, выполняемая по предположению, становится безусловной, ей разрешается обновить регистровый файл или память. Этот дополнительный этап выполнения команд обычно называется стадией фиксации результатов команды (instruction commit).
Главная идея, лежащая в основе реализации выполнения по предположению, заключается в разрешении неупорядоченного выполнения команд, но в строгом соблюдении порядка фиксации результатов и предотвращением любого безвозвратного действия (например, обновления состояния или приема исключительной ситуации) до тех пор, пока результат команды не фиксируется. В простом конвейере с выдачей одиночных команд мы могли бы гарантировать, что команда фиксируется в порядке, предписанном программой, и только после проверки отсутствия исключительной ситуации, вырабатываемой этой командой, просто посредством переноса этапа записи результата в конец конвейера. Когда мы добавляем механизм выполнения по предположению, мы должны отделить процесс фиксации команды, поскольку он может произойти намного позже, чем в простом конвейере. Добавление к последовательности выполнения команды этой фазы фиксации требует некоторых изменений в последовательности действий, а также в дополнительного набора аппаратных буферов, которые хранят результаты команд, которые завершили выполнение, но результаты которых еще не зафиксированы. Этот аппаратный буфер, который можно назвать буфером переупорядочивания, используется также для передачи результатов между командами, которые могут выполняться по предположению.
Буфер переупорядочивания предоставляет дополнительные виртуальные регистры точно так же, как станции резервирования в алгоритме Томасуло расширяют набор регистров. Буфер переупорядочивания хранит результат некоторой операции в промежутке времени от момента завершения операции, связанной с этой командой, до момента фиксации результатов команды. Поэтому буфер переупорядочивания является источником операндов для команд, точно также как станции резервирования обеспечивают промежуточное хранение и передачу операндов в алгоритме Томасуло. Основная разница заключается в том, что когда в алгоритме Томасуло команда записывает свой результат, любая последующая выдаваемая команда будет выбирать этот результат из регистрового файла. При выполнении по предположению регистровый файл не обновляется до тех пор, пока команда не фиксируется (и мы знаем определенно, что команда должна выполняться); таким образом, буфер переупорядочивания поставляет операнды в интервале между завершением выполнения и фиксацией результатов команды. Буфер переупорядочивания не похож на буфер записи в алгоритме Томасуло, и в нашем примере функции буфера записи интегрированы с буфером переупорядочивания только с целью упрощения. Поскольку буфер переупорядочивания отвечает за хранение результатов до момента их записи в регистры, он также выполняет функции буфера загрузки.
Каждая строка в буфере переупорядочивания содержит три поля: поле типа команды, поле места назначения (результата) и поле значения. Поле типа команды определяет, является ли команда условным переходом (для которого отсутствует место назначения результата), командой записи (которая в качестве места назначения результата использует адрес памяти) или регистровой операцией (команда АЛУ или команда загрузки, в которых местом назначения результата является регистр). Поле назначения обеспечивает хранение номера регистра (для команд загрузки и АЛУ) или адрес памяти (для команд записи), в который должен быть записан результат команды. Поле значения используется для хранения результата операции до момента фиксации результата команды. На рис. 6.19 показана аппаратная структура машины с буфером переупорядочивания. Буфер переупорядочивания полностью заменяет буфера загрузки и записи. Хотя функция переименования станций резервирования заменена буфером переупорядочивания, нам все еще необходимо некоторое место для буферизации операций (и операндов) между моментом их выдачи и началом выполнения. Эту функцию выполняют регистровые станции резервирования. Поскольку каждая команда имеет позицию в буфере переупорядочивания до тех пор, пока она не будет зафиксирована (и результаты не будут отправлены в регистровый файл), результат тегируется посредством номера строки буфера переупорядочивания, а не номером станции резервирования. Это требует, чтобы номер строки буфера переупорядочивания, присвоенный команде, отслеживался станцией резервирования.
Ниже перечислены четыре этапа выполнение команды:
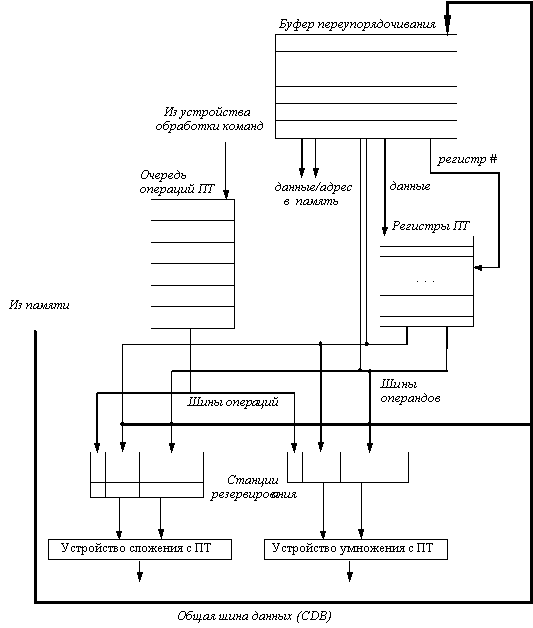
Рис. 6.19. Расширение устройства ПТ средствами выполнения по предположению
Когда команда фиксируется, соответствующая строка буфера переупорядочивания очищается, а место назначения результата (регистр или ячейка памяти) обновляется. Чтобы не менять номера строк буфера переупорядочивания после фиксации результата команды, буфер переупорядочивания реализуется в виде циклической очереди, так что позиции в буфере переупорядочивания меняются, только когда команда фиксируется. Если буфер переупорядочивания полностью заполнен, выдача команд останавливается до тех пор, пока не освободится очередная строка буфера.
Поскольку никакая запись в регистры или ячейки памяти не происходит до тех пор, пока команда не фиксируется, машина может просто ликвидировать все свои выполненные по предположению действия, если обнаруживается, что направление условного перехода было спрогнозировано не верно.
Рассмотрим следующий пример:
LD F6, 34(R2)
LD F2, 45(R3)
MULTD F0, F2, F4
SUBD F8, F6, F2
DIVD F10, F0, F6
ADDD F6, F8, F2
Представим, что в приведенном выше примере команда условного перехода BNEZ в первый раз не выполняется (рис. 6.20). Тогда команды, предшествующие команде условного перехода, будут просто фиксироваться по мере достижения каждой из них головы буфера переупорядочивания. Когда головы этого буфера достигает команда условного перехода, содержимое буфера просто гасится, и машина начинает выборку команд из другой ветви программы.
| Станции резервирования | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Имя | Занятость | Op | Vj | Vk | Qj | Qk | Назначение | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Add1 | Нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Add2 | Нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Add3 | Нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mult1 | Нет | MULT | Mem[45+Regs[R3]] | Regs[F4] | #3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mult2 | Да | DIV | Mem[34+Regs[R2]] | #3 | #5 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Буфер переупорядочивания | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Номер | Занятость | Команда | Состояние | Место наз- начения |
Значение | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | Нет | LD F6,34(R2) | Зафиксирована | F6 | Mem[34+Regs[R2]] | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2 | Нет | LD F2,45(R3) | Зафиксирована | F2 | Mem[45+Regs[R3]] | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3 | Нет | MULTD F0,F2,F4 | Запись результата |
F0 | #2 x Regs[R4]] | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4 | Да | SUBD F8,F6,F2 | Запись результата |
F8 | #1 - #2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 5 | Да | DIVD F10,F0,F6 | Выполнение | F10 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6 | Да | ADD F6,F8,F2 | Запись результата |
F6 | #4 + #2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Состояние регистров | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Поле | F0 | F2 | F4 | F6 | F8 | F10 | F12 | . . . | F30 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Порядковый # | 3 | 6 | 4 | 5 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Знятость | Да | Нет | Нет | Да | Да | Да | Нет | . . . | Нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 6.20. Состояние устройства ПТ для выполнения по предположению
Исключительные ситуации в подобной машине не воспринимаются до тех пор, пока соответствующая команда не готова к фиксации. Если выполняемая по предположению команда вызывает исключительную ситуацию, эта исключительная ситуация записывается в буфер упорядочивания. Если обнаруживается неправильный прогноз направления условного перехода и выясняется, что команда не должна была выполняться, исключительная ситуация гасится вместе с командой, когда обнуляется буфер переупорядочивания. Если же команда достигает вершины буфера переупорядочивания, то мы знаем, что она более не является выполняемой по предположению (она уже стала безусловной), и исключительная ситуация должна действительно восприниматься.
Эту методику выполнения по предположению легко распространить и на целочисленные регистры и функциональные устройства. Действительно, выполнение по предположению может быть более полезно в целочисленных программах, поскольку именно такие программы имеют менее предсказуемое поведение переходов. Кроме того, эти методы могут быть расширены так, чтобы обеспечить работу в машинах с выдачей на выполнение и фиксацией результатов нескольких команд в каждом такте. Выполнение по предположению возможно является наиболее интересным методом именно для таких машин, поскольку менее амбициозные машины могут довольствоваться параллелизмом уровня команд внутри базовых блоков при соответствующей поддержке со стороны компилятора, использующего технологию разворачивания циклов.
Очевидно, все рассмотренные ранее методы не могут достичь большей степени распараллеливания, чем заложено в конкретной прикладной программе. Вопрос увеличения степени параллелизма прикладных систем в настоящее время является предметом интенсивных исследований, проводимых во всем мире.
|
|
