Обычно, когда новая архитектура создается одним архитектором или группой архитекторов, ее отдельные части очень хорошо подогнаны друг к другу и вся архитектура может быть описана достаточно связано. Этого нельзя сказать об архитектуре 80x86, поскольку это продукт нескольких независимых групп разработчиков, которые развивали эту архитектуру более 15 лет, добавляя новые возможности к первоначальному набору команд.
В 1978 году была анонсирована
архитектура Intel 8086 как совместимое
вверх расширение в то время
успешного 8-бит микропроцессора 8080.
8086 представляет собой
16-битовую архитектуру со всеми внутренними регистрами, имеющими 16-битовую разрядность. Микропроцессор 8080 был просто построен на базе накапливающего сумматора (аккумулятора), но архитектура 8086 была расширена дополнительными регистрами. Поскольку почти каждый регистр в этой архитектуре имеет определенное назначение, 8086 по классификации частично можно отнести к машинам с накапливающим сумматором, а частично - к машинам с регистрами общего назначения, и его можно назвать расширенной машиной с накапливающим сумматором. Микропроцессор 8086 (точнее его версия 8088 с 8-битовой внешней шиной) стал основой завоевавшей в последствии весь мир серии компьютеров IBM PC, работающих под управлением операционной системы MS-DOS.
В 1980 году был анонсирован сопроцессор плавающей точки 8087. Эта архитектура расширила 8086 почти на 60 команд плавающей точки. Ее архитекторы отказались от расширенных накапливающих сумматоров для того, чтобы создать некий гибрид стеков и регистров, по сути расширенную стековую архитектуру. Полный набор стековых команд дополнен ограниченным набором команд типа регистр-память.
Анонсированный в 1982 году микропроцессор 80286, еще дальше расширил архитектуру 8086. Была создана сложная модель распределения и защиты памяти, расширено адресное пространство до 24 разрядов, а также добавлено небольшое число дополнительных команд. Поскольку очень важно было обеспечить выполнение без изменений программ, разработанных для 8086, в 80286 был предусмотрен режим реальных адресов, позволяющий машине выглядеть почти как 8086. В 1984 году компания IBM объявила об использовании этого процессора в своей новой серии персональных компьютеров IBM PC/AT.
В 1987 году появился микропроцессор
80386, который расширил архитектуру
80286 до
32 бит. В дополнение к 32-битовой архитектуре с 32-битовыми регистрами и 32-битовым адресным пространством, в микропроцессоре 80386 появились новые режимы адресации и дополнительные операции. Все эти расширения превратили 80386 в машину, по идеологии близкую к машинам с регистрами общего назначения. В дополнение к механизмам сегментации памяти, в микропроцессор 80386 была добавлена также поддержка страничной организации памяти. Также как и 80286, микропроцессор 80386 имеет режим выполнения программ, написанных для 8086. Хотя в то время базовой операционной системой для этих микропроцессоров оставалась MS-DOS, 32-разрядная архитектура и страничная организация памяти послужили основой для переноса на эту платформу операционной системы UNIX. Следует отметить, что для процессора 80286 была создана операционная система XENIX (сильно урезанный вариант системы UNIX).
Эта история иллюстрирует эффект, вызванный необходимостью обеспечения совместимости с 80x86, поскольку существовавшая база программного обеспечения на каждом шаге была слишком важной. К счастью, последующие процессоры (80486 в 1989 и Pentium в 1993 году) были нацелены на увеличение производительности и добавили к видимому пользователем набору команд только три новые команды, облегчающие организацию многопроцессорной работы.
Что бы ни говорилось о неудобствах архитектуры 80x86, следует иметь в виду, что она преобладает в мире персональных компьютеров. Почти 80% установленных малых систем базируются именно на этой архитектуре. Споры относительно преимуществ CISC и RISC архитектур постепенно стихают, поскольку современные микропроцессоры стараются вобрать в себя наилучшие свойства обоих подходов.
Современное семейство процессоров i486 (i486SX, i486DX, i486DX2 и i486DX4), в котором сохранились система команд и методы адресации процессора i386, уже имеет некоторые свойства RISC-микропроцессоров. Например, наиболее употребительные команды выполняются за один такт. Компания Intel для оценки производительности своих процессоров ввела в употребление специальную характеристику, которая называется рейтингом iCOMP. Компания надеется, что эта характеристика станет стандартной тестовой оценкой и будет применяться другими производителями микропроцессоров, однако последние с понятной осторожностью относятся к системе измерений производительности, введенной компанией Intel. Ниже в таблице приведены сравнительные характеристики некоторых процессоров компании Intel на базе рейтинга iCOMP.
| Процессор | Тактовая частота (МГц) | Рейтинг iCOMP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 386SX 386SL 386DX 386DX i486SX i486SX i486SX i486DX i486DX2 i486DX i486DX2 i486DX4 i486DX4 Pentium Pentium Pentium Pentium Pentium Pentium |
25 25 25 33 20 25 33 33 50 50 66 75 100 60 66 90 100 120 133 |
39 41 49 68 78 100 136 166 231 249 297 319 435 510 567 735 815 1000 1200 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Процессоры i486SX и i486DX - это 32-битовые процессоры с внутренней кэш-па-мятью емкостью 8 Кбайт и 32-битовой шиной данных. Основное отличие между ними заключается в том, что в процессоре i486SX отсутствует интегрированный сопроцессор плавающей точки. Поэтому он имеет меньшую цену и применяется в системах, для которых не очень важна производительность при обработке вещественных чисел. Для этих систем обычно возможно расширение с помощью внешнего сопроцессора i487SX.
Процессоры Intel OverDrive и i486DX2 практически идентичны. Однако кристалл OverDrive имеет корпус, который может устанавливаться в гнездо расширения сопроцессора i487SX, применяемое в ПК на базе i486SX. В процессорах OverDrive и i486DX2 применяется технология удвоения внутренней тактовой частоты, что позволяет увеличить производительность процессора почти на 70%. Процессор i486DX4/100 использует технологию утроения тактовой частоты. Он работает с внутренней тактовой частотой 99 МГц, в то время как внешняя тактовая частота (частота, на которой работает внешняя шина) составляет 33 МГц. Этот процессор практически обеспечивает равные возможности с машинами класса 60 МГц Pentium, являясь их полноценной и доступной по цене альтернативой.
Появившийся в 1993 году процессор Pentium ознаменовал собой новый этап в развитии архитектуры x86, связанный с адаптацией многих свойств процессоров с архитектурой RISC. Он изготовлен по 0.8 микронной БиКМОП технологии и содержит 3.1 миллиона транзисторов. Первоначальная реализация была рассчитана на работу с тактовой частотой 60 и 66 МГц. В настоящее время имеются также процессоры Pentium, работающие с тактовой частотой 75, 90, 100 и 120 МГц. Процессор Pentium по сравнению со своими предшественниками обладает целым рядом улучшенных характеристик. Главными его особенностями являются:
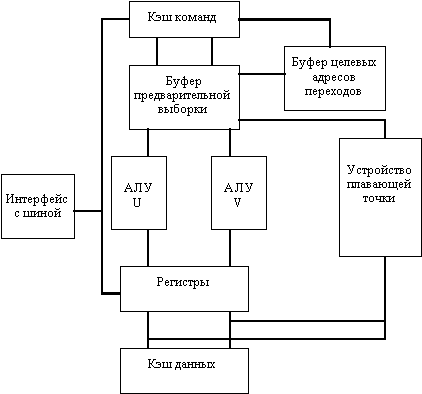
Блок-схема процессора Pentium представлена на рис. 8.1. Прежде всего новая микроархитектура этого процессора базируется на идее суперскалярной обработки (правда с некоторыми ограничениями). Основные команды распределяются по двум независимым исполнительным устройствам (конвейерам U и V). Конвейер U может выполнять любые команды семейства x86, включая целочисленные команды и команды с плавающей точкой. Конвейер V предназначен для выполнения простых целочисленных команд и некоторых команд с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, причем при выдаче устройством управления в одном такте пары команд более сложная команда поступает в конвейер U, а менее сложная - в конвейер V. Такая попарная выдача команд возможна правда только для ограниченного подмножества целочисленных команд. Команды арифметики с плавающей точкой не могут запускаться в паре с целочисленными командами. Одновременная выдача двух команд возможна только при отсутствии зависимостей по регистрам. При остановке команды по любой причине в одном конвейере, как правило останавливается и второй конвейер.
Остальные устройства процессора предназначены для снабжения конвейеров необходимыми командами и данными. В отличие от процессоров i486 в процессоре Pentium используется раздельная кэш-память команд и данных емкостью по 8 Кбайт, что обеспечивает независимость обращений. За один такт из каждой кэш-памяти могут считываться два слова. При этом кэш-память данных построена на принципах двухкратного расслоения, что обеспечивает одновременное считывание двух слов, принадлежащих одной строке кэш-памяти. Кэш-память команд хранит сразу три копии тегов, что позволяет в одном такте считывать два командных слова, принадлежащих либо одной строке, либо смежным строкам для обеспечения попарной выдачи команд, при этом третья копия тегов используется для организации протокола наблюдения за когерентностью состояния кэш-памяти. Для повышения эффективности перезагрузки кэш-памяти в процессоре применяется 64-битовая внешняя шина данных.
В процессоре предусмотрен механизм динамического прогнозирования направления переходов. С этой целью на кристалле размещена небольшая кэш-память, которая называется буфером целевых адресов переходов (BTB), и две независимые пары буферов предварительной выборки команд (по два 32-битовых буфера на каждый конвейер). Буфер целевых адресов переходов хранит адреса команд, которые находятся в буферах предварительной выборки. Работа буферов предварительной выборки организована таким образом, что в каждый момент времени осуществляется выборка команд только в один из буферов соответствующей пары. При обнаружении в потоке команд операции перехода вычисленный адрес перехода сравнивается с адресами, хранящимися в буфере BTB. В случае совпадения предсказывается, что переход будет выполнен, и разрешается работа другого буфера предварительной выборки, который начинает выдавать команды для выполнения в соответствующий конвейер. При несовпадении считается, что переход выполняться не будет и буфер предварительной выборки не переключается, продолжая обычный порядок выдачи команд. Это позволяет избежать простоев конвейеров при правильном прогнозе направления перехода. Окончательное решение о направлении перехода естественно принимается на основании анализа кода условия. При неправильно сделанном прогнозе содержимое конвейеров аннулируется и выдача команд начинается с необходимого адреса. Неправильный прогноз приводит к приостановке работы конвейеров на 3-4 такта.
Рис. 8.1. Упрощенная блок схема процессора Pentium
Следует отметить, что возросшая производительность процессора Pentium требует и соответствующей организации системы на его основе. Компания Intel разработала и поставляет все необходимые для этого наборы микросхем. Прежде всего для согласования скорости с динамической основной памятью необходима кэш-память второго уровня. Контроллер кэш-памяти 82496 и микросхемы статической памяти 82491 обеспечивают построение такой кэш-памяти объемом 256 Кбайт и работу процессора без тактов ожидания. Для эффективной организации систем Intel разработала стандарт на высокопроизводительную локальную шину PCI. Выпускаются наборы микросхем для построения мощных компьютеров на ее основе.
В настоящее время компания Intel ведет разработку нового процессора, продолжающего архитектурную линию x86. Этот процессор получил название P6. По оценкам экспертов число транзисторов в новом кристалле составит 4-5 миллионов, что может обеспечить повышение производительности до уровня 200 MIPS (66 МГц Pentium имеет производительность 112 MIPS). Для достижения такой производительности необходимо использование технических решений, широко применяющихся при построении RISC-процессоров:
Кроме того, в борьбу за новое поколение процессоров x86 включились компании, ранее занимавшиеся изготовлением Intel-совместимых процессоров. Это компании Advanced Micro Devices (AMD), Cyrix Corp и NexGen. С точки зрения микроархитектуры наиболее близок к Pentium процессор М1 компании Cyrix, который должен появиться на рынке в ближайшее время. Также как и Pentium он имеет два конвейера и может выполнять до двух команд в одном такте. Однако в процессоре М1 число случаев, когда операции могут выполняться попарно, значительно увеличено. Кроме того в нем применяется методика обходов и ускорения пересылки данных, позволяющая устранить приостановку конвейеров во многих ситуациях, с которыми не справляется Pentium. Процессор содержит 32 физических регистра (вместо 8 логических, предусмотренных архитектурой x86) и применяет методику переименования регистров для устранения зависимостей по данным. Как и Pentium, процессор M1 для прогнозирования направления перехода использует буфер целевых адресов перехода емкостью 256 элементов, но кроме того поддерживает специальный стек возвратов, отслеживающий вызовы процедур и последующие возвраты.
Процессоры К5 компании AMD и Nx586 компании NexGen используют в корне другой подход. Основа их процессоров - очень быстрое RISC-ядро, выполняющее высокорегулярные операции в суперскалярном режиме. Внутренние форматы команд (ROP у компании AMD и RISC86 у компании NexGen) соответствуют традиционным системам команд RISC-процессоров. Все команды имеют одинаковую длину и кодируются в регулярном формате. Обращения к памяти выполняются специальными командами загрузки и записи. Как известно, архитектура x86 имеет очень сложную для декодирования систему команд. В процессорах K5 и Nx586 осуществляется аппаратная трансляция команд x86 в команды внутреннего формата, что дает лучшие условия для распараллеливания вычислений. В процессоре К5 имеются 40, а в процессоре Nx586 22 физических регистра, которые реализуют методику переименования. В процессоре К5 информация, необходимая для прогнозирования направления перехода, записывается прямо в кэш команд и хранится вместе с каждой строкой кэш-памяти. В процессоре Nx586 для этих целей используется кэш-память адресов переходов на 96 элементов.
Таким образом, компания Intel больше не обладает монополией на методы конструирования высокопроизводительных процессоров x86, и можно ожидать появления новых процессоров, не только не уступающих, но и возможно превосходящих по производительности процессоры компании, стоявшей у истоков этой архитектуры. Следует отметить, что сама компания Intel заключила стратегическое соглашение с компанией Hewlett-Packard на разработку следующего поколения микропроцессоров, в которых архитектура x86 будет сочетаться с архитектурой очень длинного командного слова (VLIW -архитектурой). Появление этих микропроцессоров не ожидается до конца 1998 года.
Масштабируемая процессорная архитектура компании Sun Microsystems (SPARC - Scalable Processor Architecture) является наиболее широко распространенной RISC-архитектурой, отражающей доминирующее положение компании на рынке UNIX-рабочих станций и серверов. Процессоры с архитектурой SPARC лицензированы и изготавливаются по спецификациям Sun несколькими производителями, среди которых следует отметить компании Texas Instruments, Fujitsu, LSI Logic, Bipolar International Technology, Philips и Cypress Semiconductor. Эти компании осуществляют поставки процессоров SPARC не только самой Sun Microsystems, но и другим известным производителям вычислительных систем, например, Solbourne, Toshiba, Matsushita, Tatung и Cray Research.
В 1990 году Sun передала все права на архитектуру SPARC организации SPARC International, которая в настоящее время включает более 250 членов. Основными задачами этой организации являются лицензирование технологии SPARC для реализации, руководства и проверки совместимости со стандартами SPARC. Именно такая стратегия лицензирования позволила процессорам с архитектурой SPARC занять лидирующие позиции на рынке RISC-кристаллов (по данным независимой компании IDC за 1992 год архитектура SPARC занимала 56% рынка, далее следовали MIPS - 15% и PA-RISC - 12.2%).
Первоначально архитектура SPARC была разработана с целью упрощения реализации 32-битового процессора. В последствии по мере улучшения технологии изготовления интегральных схем она постепенно развивалось и в настоящее время имеется 64-битовая версия этой архитектуры.
В отличие от большинства RISC архитектур SPARC использует регистровые окна, которые обеспечивают удобный механизм передачи параметров между программами и возврата результатов. Архитектура SPARC была первой коммерческой разработкой, реализующей механизмы отложенных переходов и аннулирования команд. Это давало компилятору большую свободу заполнения времени выполнения команд перехода командой, которая выполняется в случае выполнения условий перехода и игнорируется в случае, если условие перехода не выполняется.
Первый процессор SPARC был изготовлен компанией Fujitsu на основе вентильной матрицы, работающей на частоте 16.67 МГц. На основе этого процессора была разработана первая рабочая станция Sun-4 с производительностью 10 MIPS, объявленная осенью 1987 года (до этого времени компания Sun использовала в своих изделиях микропроцессоры Motorola 680X0). В марте 1988 года Fujitsu увеличила тактовую частоту до 25 МГц создав процессор с производительностью 15 MIPS.
Позднее компания Sun умело использовала конкуренцию среди компаний-поставщиков интегральных схем (LSI Logic, Cypress и Texas Instruments), выбирая наиболее удачные разработки для реализации своих изделий SPARCstation 1, SPARCstation 1+, SPARCstation IPC, SPARCstation ELC, SPARCstation IPX, SPARCstation 2 и серверов серий 4ХХ и 6ХХ. Тактовая частота процессоров SPARC была повышена до 40 МГц, а производительность - до 28 MIPS.
SuperSPARC
Дальнейшее увеличение производительности процессоров с архитектурой SPARC было достигнуто за счет реализации в кристаллах принципов суперскалярной обработки компаниями Texas Instruments и Cypress. Процессор SuperSPARC компании Texas Instruments стал основой серии рабочих станций и серверов SPARCstation/SPARCserver 10 и SPARCstation/SPARCserver 20. Имеется несколько версий этого процессора, позволяющего в зависимости от смеси команд обрабатывать до трех команд за один машинный такт, отличающихся тактовой частотой. Процессор SuperSPARC (рис. 8.2) имеет сбалансированную производительность на операциях с фиксированной и плавающей точкой. Он имеет внутренний кэш емкостью 36 Кб (20 Кб - кэш команд и 16 Кб - кэш данных), раздельные конвейеры целочисленной и вещественной арифметики и при тактовой частоте 75 МГц обеспечивает производительность около 205 MIPS. Процессор SuperSPARC применяется также в серверах SPARCserver 1000 и SPARCcenter 2000 компании Sun.
Конструктивно кристалл монтируется на взаимозаменяемых процессорных модулях трех типов, отличающихся наличием и объемом кэш-памяти второго уровня и тактовой частотой. Модуль M-bus SuperSPARC, используемый в модели 50 содержит 50-МГц SuperSPARC процессор с внутренним кэшем емкостью 36 Кб (20 Кб кэш команд и 16 Кб кэш данных). Модули M-bus SuperSPARC в моделях 51, 61 и 71 содержат по одному SuperSPARC процессору, работающему на частоте 50, 60 и 75 МГц соответственно, одному кристаллу кэш-контроллера (так называемому SuperCache), а также внешний кэш емкостью 1 Мб. Модули M-bus в моделях 502, 612, 712 и 514 содержат два SuperSPARC процессора и два кэш-контроллера каждый, а последние три модели и по одному 1 Мб внешнему кэшу на каждый процессор. Использование кэш-памяти позволяет модулям CPU работать с тактовой частотой, отличной от тактовой частоты материнской платы; пользователи всех моделей поэтому могут улучшить производительность своих систем заменой существующих модулей CPU вместо того, чтобы производить upgrade всей материнской платы.
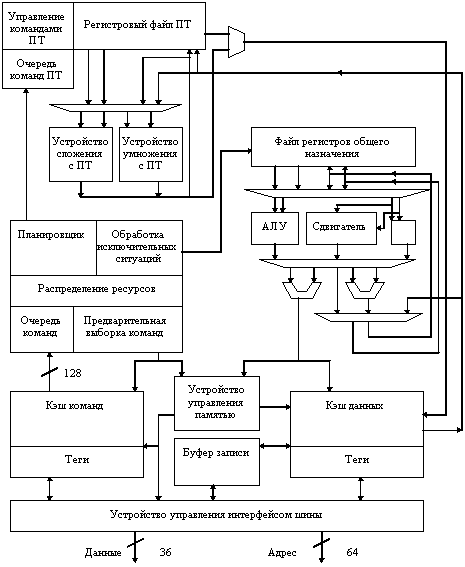
Рис. 8.2. Блок-схема процессора Super SPARC
Компания Texas Instruments разработала также 50 МГц процессор MicroSPARC с встроенным кэшем емкостью 6 Кб, который ранее широко использовался в дешевых моделях рабочих станций SPARCclassic и SPARCstation LX, а в настоящее время применяется лишь в X-терминалах. Sun совместно с Fujitsu создали также новую версию кристалла MicroSPARC II с встроенным кэшем емкостью 24 Кб. На его основе построены рабочие станции и серверы SPARCstation/SPARCserver 4 и SPARCstation/SPARCserver 5, работающие на частоте 70, 85 и 110 МГц.
Хотя архитектура SPARC остается доминирующей на рынке процессоров RISC, особенно в секторе рабочих станций, повышение тактовой частоты процессоров в 1992-1994 годах происходило более медленными темпами по сравнению с повышением тактовой частоты конкурирующих архитектур процессоров. Чтобы ликвидировать это отставание, а также в ответ на появление на рынке 64-битовых процессоров компания Sun разработала и проводит в жизнь пятилетнюю программу модернизации. В соответствии с этой программой Sun планировала довести тактовую частоту процессоров MicroSPARC до 100 МГц в 1994 году (процессор MicroSPARC II с тактовой частотой 70, 85 и 110 МГц уже используется в рабочих станциях и серверах SPARCstation 5) и до 125 МГц (процессор MicroSPARC III) к концу 1995 года. В конце 1994 - начале 1995 года на рынке появились микропроцессоры hyperSPARC и однопроцессорные и двухпроцессорные рабочие станции с тактовой частотой процессора 100 и 125 МГц. К середине 1995 года тактовая частота процессоров SuperSPARC должна быть доведена до 90 МГц (60 и 75 МГц версии этого процессора в настоящее время применяются в рабочих станциях и серверах SPARCstation 20, SPARCserver 1000 и SPARCcenter 2000 компании Sun и 64-процессорном сервере компании Cray Research). Во второй половине 1995 года должны появиться 64-битовые процессоры UltraSPARC I с тактовой частотой от 167 МГц, в конце 1995 - начале 1996 года - процессоры UltraSPARC II с тактовой частотой от 200 до 275 МГц, а в 1997/1998 годах - процессоры UltraSPARC III с частотой 500 МГц.
hyperSPARC
Одной из главных задач, стоявших перед разработчиками микропроцессора hyperSPARC, было повышение производительности, особенно при выполнении операций с плавающей точкой. Поэтому особое внимание разработчиков было уделено созданию простых и сбалансированных шестиступенчатых конвейеров целочисленной арифметики и плавающей точки. Логические схемы этих конвейеров тщательно разрабатывались, количество логических уровней вентилей между ступенями выравнивалось, чтобы упростить вопросы дальнейшего повышения тактовой частоты.
Производительность процессоров hyperSPARC может меняться независимо от скорости работы внешней шины (MBus). Набор кристаллов hyperSPARC обеспечивает как синхронные, так и асинхронные операции с помощью специальной логики кристалла RT625. Отделение внутренней шины процессора от внешней шины позволяет увеличивать тактовую частоту процессора независимо от частоты работы подсистем памяти и ввода/вывода. Это обеспечивает более длительный жизненный цикл, поскольку переход на более производительные модули hyperSPARC не требует переделки всей системы.
Процессорный набор hyperSPARC с тактовой частотой 100 МГц построен на основе технологического процесса КМОП с тремя уровнями металлизации и проектными нормами 0.5 микрон. Внутренняя логика работает с напряжением питания 3.3В.
Процессор hyperSPARC реализован в виде многокристальной микросборки (рис. 8.3), в состав которой входит суперскалярная конвейерная часть и тесно связанная с ней кэш-память второго уровня. В набор кристаллов входят RT620 (CPU) - центральный процессор, RT625 (CMTU) - контроллер кэш-памяти, устройство управления памятью и устройство тегов и четыре RT627 (CDU) кэш-память данных для реализации кэш-памяти второго уровня емкостью 256 Кбайт. RT625 обеспечивает также интерфейс с MBus.
Центральный процессор RT620 (рис. 8.4) состоит из целочисленного устройства, устройства с плавающей точкой, устройства загрузки/записи, устройства переходов и двухканальной множественно-ассоциативной памяти команд емкостью 8 Кбайт. Целочисленное устройство включает АЛУ и отдельный тракт данных для операций загрузки/записи, которые представляют собой два из четырех исполнительных устройств процессора. Устройство переходов обрабатывает команды передачи управления, а устройство плавающей точки, реально состоит из двух независимых конвейеров - сложения и умножения чисел с плавающей точкой. Для увеличения пропускной способности процессора команды плавающей точки, проходя через целочисленный конвейер, поступают в очередь, где они ожидают запуска в одном из конвейеров плавающей точки. В каждом такте выбираются две команды. В общем случае, до тех пор, пока эти две команды требуют для своего выполнения различных исполнительных устройств при отсутствии зависимостей по данным, они могут запускаться одновременно. RT620 содержит два регистровых файла: 136 целочисленных регистров, сконфигурированных в виде восьми регистровых окон, и 32 отдельных регистра плавающей точки, расположенных в устройстве плавающей точки.
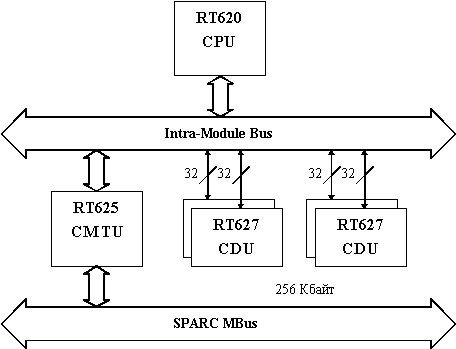
Рис. 8.3. Набор кристаллов процессора hyperSPARC
Кэш-память второго уровня в процессоре hyperSPARC строится на базе RT625 CMTU, который представляет собой комбинированный кристалл, включающий контроллер кэш-памяти и устройство управления памятью, которое поддерживает разделяемую внешнюю память и симметричную многопроцессорную обработку. Контроллер кэш-памяти поддерживает кэш емкостью 256 Кбайт, состоящий из четырех RT627 CDU. Кэш-память имеет прямое отображение и 4К тегов. Теги в кэш-памяти содержат физические адреса, поэтому логические схемы для соблюдения когерентности кэш-памяти в многопроцессорной системе, имеющиеся в RT625, могут быстро определить попадания или промахи при просмотре со стороны внешней шины без приостановки обращений к кэш-памяти со стороны центрального процессора. Поддерживается как режим сквозной записи, так и режим обратного копирования.
Устройство управления памятью содержит в своем составе полностью ассоциативную кэш-память преобразования виртуальных адресов в физические (TLB), состоящую из 64 строк, которая поддерживает 4096 контекстов. RT625 содержит буфер чтения емкостью 32 байта, используемый для загрузки, и буфер записи емкостью 64 байта, используемый для разгрузки кэш-памяти второго уровня. Размер строки кэш-памяти составляет 32 байта. Кроме того, в RT625 имеются логические схемы синхронизации, которые обеспечивают интерфейс между внутренней шиной процессора и SPARC MBus при выполнении асинхронных операций.
RT627 представляет собой статическую память 16К ( 32, специально разработанную для удовлетворения требований hyperSPARC. Она организована как четырехканальная статическая память в виде четырех массивов с логикой побайтной записи и входными и выходными регистрами-защелками. RT627 для ЦП является кэш-памятью с нулевым состоянием ожидания без потерь (т.е. приостановок) на конвейеризацию для всех операций загрузки и записи, которые попадают в кэш-память. RT627 был разработан специально для процессора hyperSPARC, таким образом для соединения с RT620 и RT625 не нужны никакие дополнительные схемы.
Набор кристаллов позволяет использовать преимущества тесной связи процессора с кэш-памятью. Конструкция RT620 допускает потерю одного такта в случае промаха в кэш-памяти первого уровня. Для доступа к кэш-памяти второго уровня в RT620 отведена специальная ступень конвейера. Если происходит промах в кэш-памяти первого уровня, а в кэш-памяти второго уровня имеет место попадание, то центральный процессор не останавливается.
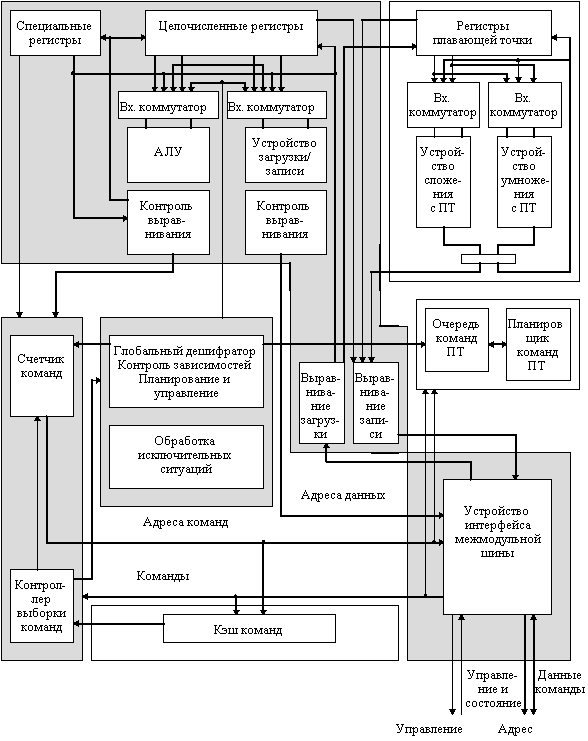
Рис. 8.4. Процессор RТ 620
Команды загрузки и записи одновременно генерируют два обращения: одно к кэш-памяти команд первого уровня емкостью 8 Кбайт и другое к кэш-памяти второго уровня. Если адрес команды найден в кэш-памяти первого уровня, то обращение к кэш-памяти второго уровня отменяется и команда становится доступной на стадии декодирования конвейера. Если же во внутренней кэш-памяти произошел промах, а в кэш-памяти второго уровня обнаружено попадание, то команда станет доступной с потерей одного такта, который встроен в конвейер. Такая возможность позволяет конвейеру продолжать непрерывную работу до тех пор, пока имеют место попадания в кэш-память либо первого, либо второго уровня, которые составляют 90% и 98% соответственно для типовых прикладных задач рабочей станции. С целью достижения архитектурного баланса и упрощения обработки исключительных ситуаций целочисленный конвейер и конвейер плавающей точки имеют по пять стадий выполнения операций. Такая конструкция позволяет RT620 обеспечить максимальную пропускную способность, не достижимую в противном случае.
MicroSPARC-II
Эффективная с точки зрения стоимости конструкция не может полагаться только на увеличение тактовой частоты. Экономические соображения заставляют принимать решения, основой которых является массовая технология. Системы microSPARC обеспечивают высокую производительность при умеренной тактовой частоте путем оптимизации среднего количества команд, выполняемых за один такт. Это ставит вопросы эффективного управления конвейером и иерархией памяти. Среднее время обращения к памяти должно сокращаться, либо должно возрастать среднее количество команд, выдаваемых для выполнения в каждом такте, увеличивая производительность на основе компромиссов в конструкции процессора.
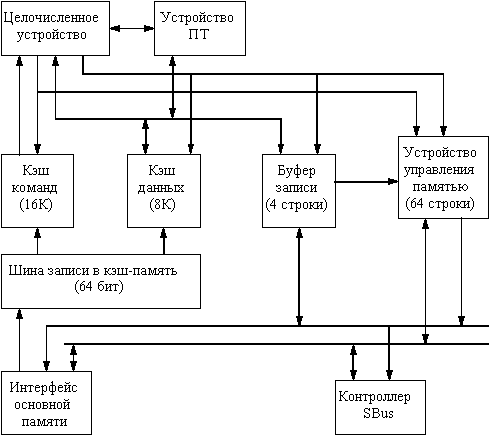
Рис. 8.5. Блок-схема процессора micro Sparc-II
MicroSPARC-II (рис. 8.5) является одним из сравнительно недавно появившихся процессоров семейства SPARC. Основное его назначение - однопроцессорные низкостоимостные системы. Он представляет собой высокоинтегрированную микросхему, содержащую целочисленное устройство, устройство управления памятью, устройство плавающей точки, раздельную кэш-память команд и данных, контроллер управления микросхемами динамической памяти и контроллер шины SBus.
Основными свойствами целочисленного устройства microSPARC-II являются:
Целочисленное устройство использует пятиступенчатый конвейер команд с одновременным запуском до двух команд. Устройство плавающей точки обеспечивает выполнение операций в соответствии со стандартом IEEE 754.
Устройство управления памятью выполняет четыре основных функции. Во-первых, оно обеспечивает формирование и преобразование виртуального адреса в физический. Эта функция реализуется с помощью ассоциативного буфера TLB. Кроме того, устройство управления памятью реализует механизмы защиты памяти. И, наконец, оно выполняет арбитраж обращений к памяти со стороны ввода/вывода, кэша данных, кэша команд и TLB.
Процессор microSPARC II имеет 64-битовую шину данных для связи с памятью и поддерживает оперативную память емкостью до 256 Мбайт. В процессоре интегрирован контроллер шины SBus, обеспечивающий эффективную с точки зрения стоимости реализацию ввода/вывода.
Основой разработки современных изделий Hewlett-Packard является архитектура PA-RISC. Она была разработана компанией в 1986 году и с тех пор прошла несколько стадий своего развития благодаря успехам интегральной технологии от многокристального до однокристального исполнения. В сентябре 1992 года компания Hewlett-Packard объявила о создании своего суперскалярного процессора PA-7100, который с тех пор стал основой построения семейства рабочих станций HP 9000 Series 700 и семейства бизнес-серверов HP 9000 Series 800. В настоящее время имеются 33-, 50- и 99 МГц реализации кристалла PA-7100. Кроме того выпущены модифицированные, улучшенные по многим параметрам кристаллы PA-7100LC с тактовой частотой 64, 80 и 100 МГц, и PA-7150 с тактовой частотой 125 МГц, а также PA-7200 с тактовой частотой 90 и 100 МГц. Компания активно разрабатывает процессор следующего поколения HP 8000, которые будет работать с тактовой частотой 200 МГц и обеспечивать уровень 360 единиц SPECint92 и 550 единиц SPECfp92. Появление этого кристалла ожидается в 1996 году. Кроме того, Hewlett-Packard в сотрудничестве с Intel планируют создать новый процессор с очень длинным командным словом (VLIW-архитектура), который будет совместим как с семейством Intel x86, так и семейством PA-RISC. Выпуск этого процессора планируется на 1998 год.
PA 7100
Особенностью архитектуры PA-RISC является внекристальная реализация кэша, что позволяет реализовать различные объемы кэш-памяти и оптимизировать конструкцию в зависимости от условий применения (рис. 8.6). Хранение команд и данных осуществляется в раздельных кэшах, причем процессор соединяется с ними с помощью высокоскоростных 64-битовых шин. Кэш-память реализуется на высокоскоростных кристаллах статической памяти (SRAM), синхронизация которых осуществляется непосредственно на тактовой частоте процессора. При тактовой частоте 100 МГц каждый кэш имеет полосу пропускания 800 Мбайт/с при выполнении операций считывания и 400 Мбайт/с при выполнении операций записи. Микропроцессор аппаратно поддерживает различный объем кэш-памяти: кэш команд может иметь объем от 4 Кбайт до 1 Мбайт, кэш данных - от 4 Кбайт до 2 Мбайт. Чтобы снизить коэффициент промахов применяется механизм хеширования адреса. В обоих кэшах для повышения надежности применяются дополнительные контрольные разряды, причем ошибки кэша команд корректируются аппаратными средствами.
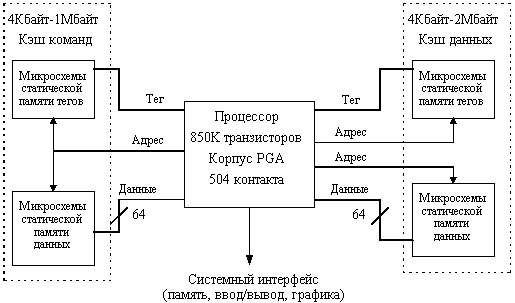
Рис. 8.6. Блок-схема процессора PA 7100
Процессор подсоединяется к памяти и подсистеме ввода/вывода посредством синхронной шины. Процессор может работать с тремя разными отношениями внутренней и внешней тактовой частоты в зависимости от частоты внешней шины: 1:1, 3:2 и 2:1. Это позволяет использовать в системах разные по скорости микросхемы памяти.
Конструктивно на кристалле PA-7100 размещены целочисленный процессор, процессор для обработки чисел с плавающей точкой, устройство управления кэшем, унифицированный буфер TLB, устройство управления, а также ряд интерфейсных схем. Целочисленный процессор включает АЛУ, устройство сдвига, сумматор команд перехода, схемы проверки кодов условий, схемы обхода, универсальный регистровый файл, регистры управления и регистры адресного конвейера. Устройство управления кэш-памятью содержит регистры, обеспечивающие перезагрузку кэш-памяти при возникновении промахов и контроль когерентного состояния памяти. Это устройство содержит также адресные регистры сегментов, буфер преобразования адреса TLB и аппаратуру хеширования, управляющую перезагрузкой TLB. В состав процессора плавающей точки входят устройство умножения, арифметико-логическое устройство, устройство деления и извлечения квадратного корня, регистровый файл и схемы "закоротки" результата. Интерфейсные устройства включают все необходимые схемы для связи с кэш-памятью команд и данных, а также с шиной данных. Обобщенный буфер TLB содержит 120 строк ассоциативной памяти фиксированного размера и 16 строк переменного размера.
Устройство плавающей точки (рис. 8.7) реализует арифметику с одинарной и двойной точностью в стандарте IEEE 754. Его устройство умножения используется также для выполнения операций целочисленного умножения. Устройства деления и вычисления квадратного корня работают с удвоенной частотой процессора. Арифметико-логическое устройство выполняет операции сложения, вычитания и преобразования форматов данных. Регистровый файл состоит из 28 64-битовых регистров, каждый из которых может использоваться как два 32-битовых регистра для выполнения операций с плавающей точкой одинарной точности. Регистровый файл имеет пять портов чтения и три порта записи, которые обеспечивают одновременное выполнение операций умножения, сложения и загрузки/записи.
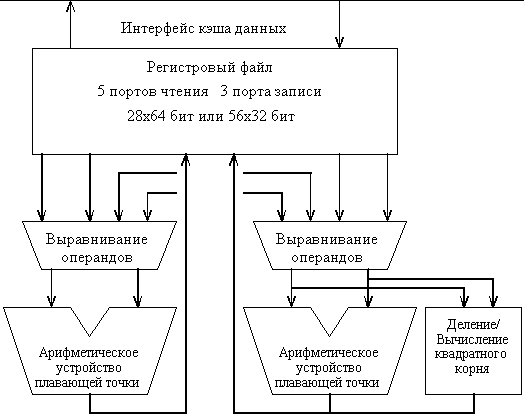
Рис. 8.7. Управление командами плавающей точки
Большинство улучшений производительности процессора связано с увеличением тактовой частоты до 100 МГц по сравнению с 66 МГц у его предшественника.
Конвейер целочисленного устройства включает шесть ступеней: Чтение из кэша команд (IR), Чтение операндов (OR), Выполнение/Чтение из кэша данных (DR), Завершение чтения кэша данных (DRC), Запись в регистры (RW) и Запись в кэш данных (DW). На ступени ID выполняется выборка команд. Реализация механизма выдачи двух команд требует небольшого буфера предварительной выборки, который обеспечивает предварительную выборку команд за два такта до начала работы ступени IR. Во время выполнения на ступени OR все исполнительные устройства декодируют поля операндов в команде и начинают вычислять результат операции. На ступени DR целочисленное устройство завершает свою работу. Кроме того, кэш-память данных выполняет чтение, но данные не поступают до момента завершения работы ступени DRC. Результаты операций сложения (ADD) и умножения (MULTIPLY) также становятся достоверными в конце ступени DRC. Запись в универсальные регистры и регистры плавающей точки производится на ступени RW. Запись в кэш данных командами записи (STORE) требует двух тактов. Наиболее раннее двухтактное окно команды STORE возникает на ступенях RW и DW. Однако это окно может сдвигаться, поскольку записи в кэш данных происходят только когда появляется следующая команда записи. Операции деления и вычисления квадратного корня для чисел с плавающей точкой заканчиваются на много тактов позже ступени DW.
Конвейер проектировался с целью максимального увеличения времени, необходимого для выполнения чтения внешних кристаллов SRAM кэш-памяти данных. Это позволяет максимизировать частоту процессора при заданной скорости SRAM. Все команды загрузки (LOAD) выполняются за один такт и требуют только одного такта полосы пропускания кэш-памяти данных. Поскольку кэши команд и данных размещены на разных шинах, в конвейере отсутствуют какие-либо потери, связанные с конфликтами по обращениям в кэш данных и кэш команд.
Процессор может в каждом такте выдавать на выполнение одну целочисленную команду и одну команду плавающей точки. Полоса пропускания кэша команд достаточна для поддержания непрерывной выдачи двух команд в каждом такте. Отсутствуют какие-либо ограничения по выравниванию или порядку следования пары команд, которые выполняются вместе. Кроме того, отсутствуют потери тактов, связанных с переключением с выполнения двух команд на выполнение одной команды. Специальное внимание было уделено тому, чтобы выдача двух команд в одном такте не приводила к ограничению тактовой частоты. Чтобы добиться этого, в кэше команд был реализован специально предназначенный для этого заранее декодируемый бит, чтобы отделить команды целочисленного устройства от команд устройства плавающей точки. Этот бит предварительного декодирования команд минимизирует время, необходимое для правильного разделения команд.
Потери, связанные с зависимостями по данным и управлению, в этом конвейере минимальны. Команды загрузки выполняются за один такт, за исключением случая, когда последующая команда пользуется регистром-приемником команды LOAD. Как правило компилятор позволяет обойти подобные потери одного такта. Для уменьшения потерь, связанных с командами условного перехода, в процессоре используется алгоритм прогнозирования направления передачи управления. Для оптимизации производительности циклов передачи управления вперед по программе прогнозируются как невыполняемые переходы, а передачи управления назад по программе - как выполняемые переходы. Правильно спрогнозированные условные переходы выполняются за один такт.
Количество тактов, необходимое для записи слова или двойного слова командой STORE уменьшено с трех до двух тактов. В более ранних реализациях архитектуры PA-RISC был необходим один дополнительный такт для чтения тега кэша, чтобы гарантировать попадание, а также для того, чтобы объединить старые данные строки кэш-памяти данных с записываемыми данными. PA 7100 использует отдельную шину адресного тега, чтобы совместить по времени чтение тега с записью данных предыдущей команды STORE. Кроме того, наличие отдельных сигналов разрешения записи для каждого слова строки кэш-памяти устраняет необходимость объединения старых данных с новыми, поступающими при выполнении команд записи слова или двойного слова. Этот алгоритм требует, чтобы запись в микросхемы SRAM происходила только после того, когда будет определено, что данная запись сопровождается попаданием в кэш и не вызывает прерывания. Это требует дополнительной ступени конвейера между чтением тега и записью данных. Такая конвейеризация не приводит к дополнительным потерям тактов, поскольку в процессоре реализованы специальные цепи обхода, позволяющие направить отложенные данные команды записи последующим командам загрузки или командам STORE, записывающим только часть слова. Для данного процессора потери конвейера для команд записи слова или двойного слова сведены к нулю, если непосредственно последующая команда не является командой загрузки или записи. В противном случае потери равны одному такту. Потери на запись части слова могут составлять от нуля до двух тактов. Моделирование показывает, что подавляющее большинство команд записи в действительности работают с однословным или двухсловным форматом.
Все операции с плавающей точкой, за исключением команд деления и вычисления квадратного корня, полностью конвейеризованы и имеют двухтактную задержку выполнения как в режиме с одинарной, так и с двойной точностью. Процессор может выдавать на выполнение независимые команды с плавающей точкой в каждом такте при отсутствии каких-либо потерь. Последовательные операции с зависимостями по регистрам приводят к потере одного такта. Команды деления и вычисления квадратного корня выполняются за 8 тактов при одиночной и за 15 тактов при двойной точности. Выполнение команд не останавливается из-за команд деления/вычисления квадратного корня до тех пор, пока не потребуется регистр результата или не будет выдаваться следующая команда деления/вычисления квадратного корня.
Процессор может выполнять параллельно одну целочисленную команду и одну команду с плавающей точкой. При этом "целочисленными командами" считаются и команды загрузки и записи регистров плавающей точки, а "команды плавающей точки" включают команды FMPYADD и FMPYSUB. Эти последние команды объединяют операцию умножения с операциями сложения или вычитания соответственно, которые выполняются параллельно. Пиковая производительность составляет 200 MFLOPS для последовательности команд FMPYADD, в которых смежные команды независимы по регистрам.
Потери для операций плавающей точки, использующих предварительную загрузку операнда командой LOAD, составляют один такт, если команды загрузки и плавающей арифметики являются смежными, и два такта, если они выдаются для выполнения одновременно. Для команды записи, использующей результат операции с плавающей точкой, потери отсутствуют, даже если они выполняются параллельно.
Потери, возникающие при промахах в кэше данных, минимизируются посредством применения четырех разных методов: "попадание при промахе" для команд LOAD и STORE, потоковый режим работы с кэшем данных, специальная кодировка команд записи, позволяющая избежать копирования строки, в которой произошел промах, и семафорные операции в кэш-памяти. Первое свойство позволяет во время обработки промаха в кэше данных выполнять любые типы других команд. Для промахов, возникающих при выполнении команды LOAD, обработка последующих команд может продолжаться до тех пор, пока регистр результата команды LOAD не потребуется в качестве регистра операнда для другой команды. Компилятор может использовать это свойство для предварительной выборки в кэш необходимых данных задолго до того момента, когда они действительно потребуются. Для промахов, возникающих при выполнении команды STORE, обработка последующих команд загрузки или операций записи в части одного слова продолжается до тех пор, пока не возникает обращений к строке, в которой произошел промах. Компилятор может использовать это свойство для выполнения команд на фоне записи результатов предыдущих вычислений. Во время задержки, связанной с обработкой промаха, другие команды LOAD и STORE, для которых происходит попадание в кэш данных, могут выполняться как и другие команды целочисленной арифметики и плавающей точки. В течение всего времени обработки промаха команды STORE, другие команды записи в ту же строку кэш-памяти могут происходить без дополнительных потерь времени. Для каждого слова в строке кэш-памяти процессор имеет специальный индикационный бит, предотвращающий копирование из памяти тех слов строки, которые были записаны командами STORE. Эта возможность применяется к целочисленным и плавающим операциям LOAD и STORE.
Выполнение команд останавливается, когда регистр-приемник команды LOAD, выполняющейся с промахом, требуется в качестве операнда другой команды. Свойство "потоковости" позволяет продолжить выполнение как только нужное слово или двойное слово возвращается из памяти. Таким образом, выполнение команд может продолжаться как во время задержки, связанной с обработкой промаха, так и во время заполнения соответствующей строки при промахе.
При выполнении блочного копирования данных в ряде случаев компилятор заранее знает, что запись должна осуществляться в полную строку кэш-памяти. Для оптимизации обработки таких ситуаций архитектура PA-RISC 1.1 определяет специальную кодировку команд записи ("блочное копирование"), которая показывает, что аппаратуре не нужно осуществлять выборку из памяти строки, при обращении к которой может произойти промах кэш-памяти. В этом случае время обращения к кэшу данных складывается из времени, которое требуется для копирования в память старой строки кэш-памяти по тому же адресу в кэше (если он "грязный") и времени, необходимого для записи нового тега кэша. В процессоре PA 7100 такая возможность реализована как для привилегированных, так и для непривилегированных команд.
Последнее улучшение управления кэшем данных связано с реализацией семафорных операций "загрузки с обнулением" непосредственно в кэш-памяти. Если семафорная операция выполняется в кэше, то потери времени при ее выполнении не превышают потерь обычных операций записи. Это не только сокращает конвейерные потери, но и снижает трафик шины памяти. В архитектуре PA-RISC 1.1 предусмотрен также другой тип специального кодирования команд, который устраняет требование синхронизации семафорных операций с устройствами ввода/вывода.
Управление кэш-памятью команд позволяет при промахе продолжить выполнение команд сразу же после поступления отсутствующей в кэше команды из памяти. 64-битовая магистраль данных, используемая для заполнения блоков кэша команд, соответствует максимальной полосе пропускания внешней шины памяти 400 Мбайт/с при тактовой частоте 100 МГц.
В процессоре предусмотрен также ряд мер по минимизации потерь, связанных с преобразованиями виртуальных адресов в физические.
Конструкция процессора обеспечивает реализацию двух способов построения многопроцессорных систем. При первом способе каждый процессор подсоединяется к интерфейсному кристаллу, который наблюдает за всеми транзакциями на шине основной памяти. В такой системе все функции по поддержанию когерентного состояния кэш-памяти возложены на интерфейсный кристалл, который посылает процессору соответствующие транзакции. Кэш данных построен на принципах отложенного обратного копирования и для каждого блока кэш-памяти поддерживаются биты состояния "частный" (private), "грязный" (dirty) и "достоверный" (valid), значения которых меняются в соответствии с транзакциями, которые выдает или принимает процессор.
Второй способ организации многопроцессорной системы позволяет объединить два процессора и контроллер памяти и ввода-вывода на одной и той же локальной шине памяти. В такой конфигурации не требуется дополнительных интерфейсных кристаллов и она совместима с существующей системой памяти. Когерентность кэш-памяти обеспечивается наблюдением за локальной шиной памяти. Пересылки строк между кэшами выполняются без участия контроллера памяти и ввода-вывода. Такая конфигурация обеспечивает возможность построения очень дешевых высокопроизводительных многопроцессорных систем.
Процессор поддерживает ряд операций, необходимых для улучшения графической производительности рабочих станций серии 700: блочные пересылки, Z-буфери-зацию, интерполяцию цветов и команды пересылки данных с плавающей точкой для обмена с пространством ввода/вывода.
Процессор построен на базе технологического процесса КМОП с проектными нормами 0.8 микрон, что обеспечивает тактовую частоту 100 МГц.
PA 7200
Процессор PA 7200 имеет ряд архитектурных усовершенствований по сравнению с PA 7100, главными из которых являются добавление второго целочисленного конвейера, построение внутрикристального вспомогательного кэша данных и реализация нового 64-битового интерфейса с шиной памяти.
Процессор PA 7200, как и его предшественник, обеспечивает суперскалярный режим работы с одновременной выдачей до двух команд в одном такте. Все команды процессора можно разделить на три группы: целочисленные операции, операции загрузки/записи и операции с плавающей точкой. PA 7200 осуществляет одновременную выдачу двух команд, принадлежащим разным группам, или двух целочисленных команд (благодаря наличию второго целочисленного конвейера с АЛУ и дополнительных портов чтения и записи в регистровом файле). Команды перехода выполняются в целочисленном конвейере, причем эти переходы могут составлять пару для одновременной выдачи на выполнение только с предшествующей командой.
Повышение тактовой частоты процессора требует упрощения декодирования команд на этапе выдачи. С этой целью предварительная дешифрация потока команд осуществляется еще на этапе загрузки кэш-памяти. Для каждого двойного слова кэш-память команд включает 6 дополнительных бит, которые содержат информацию о наличии зависимостей по данным и конфликтов ресурсов, что существенно упрощает выдачу команд в суперскалярном режиме.
В процессоре PA 7200 реализован эффективный алгоритм предварительной выборки команд, хорошо работающий и на линейных участках программ.
Как и в PA 7100 в процессоре реализован интерфейс с внешней кэш-памятью данных, работающей на тактовой частоте процессора с однотактным временем ожидания. Внешняя кэш-память данных построена по принципу прямого отображения. Кроме того, для повышения эффективности на кристалле процессора реализован небольшой вспомогательный кэш емкостью в 64 строки. Формирование, преобразование адреса и обращение к основной и вспомогательной кэш-памяти данных выполняется на двух ступенях конвейера. Максимальная задержка при обнаружении попадания равна одному такту.
Вспомогательный внутренний кэш содержит 64 32-байтовые строки. При обращении к кэш-памяти осуществляется проверка 65 тегов: 64-х тегов вспомогательного кэша и одного тега внешнего кэша данных. При обнаружении совпадения данные направляются в требуемое функциональное устройство.
При отсутствии необходимой строки в кэш-памяти производится ее загрузка из основной памяти. При этом строка поступает во вспомогательный кэш, что в ряде случаев позволяет сократить количество перезагрузок внешней кэш-памяти, организованной по принципу прямого отображения. Архитектурой нового процессора для команд загрузки/записи предусмотрено кодирование специального признака локального размещения данных ("spatial locality only"). При выполнении команд загрузки, помеченных этим признаком, происходит обычное заполнение строки вспомогательного кэша. Однако последующая запись строки осуществляется непосредственно в основную память минуя внешний кэш данных, что значительно повышает эффективность работы с большими массивами данных, для которых размера строки кэш-памяти с прямым отображением оказывается недостаточно.
Расширенный набор команд процессора позволяет реализовать средства автоиндексации для повышения эффективности работы с массивами, а также осуществлять предварительную выборку команд, которые помещаются во вспомогательный внутренний кэш. Этот вспомогательный кэш обеспечивает динамическое расширение степени ассоциативности основной кэш-памяти, построенной на принципе прямого отображения, и является более простым альтернативным решением по сравнению с множественно-ассоциативной организацией.
Процессор PA 7200 включает интерфейс новой 64-битовой мультиплексной системной шины Runway, реализующей расщепление транзакций и поддержку протокола когерентности памяти. Этот интерфейс включает буфера транзакций, схемы арбитража и схемы управления соотношениями внешних и внутренних тактовых частот.
Процессор 88110 относится к разряду суперскалярных RISC-процессоров. Основные особенности этого процессора связаны с использованием принципов суперскалярной обработки, двух восьмипортовых регистровых файлов, десяти независимых исполнительных устройств, больших по объему внутренних кэшей и широких магистралей данных.
На рис. 8.8 представлена блок-схема процессора, содержащего 1.3 миллиона вентилей. Центральной частью этой архитектуры является шина операндов (в реализации это шесть 80-битовых шин), соединяющая регистровые файлы и исполнительные устройства.
Процессор имеет 10 исполнительных устройств, которые работают одновременно и независимо, и два регистровых файла. Файл регистров общего назначения имеет 32-битовую организацию. Расширенные регистры плавающей точки имеют 80-битовую организацию. Эти регистровые файлы снабжены шестью портами чтения и двумя портами записи каждый.
Внешняя шина процессора имеет отдельные линии данных (64 бит) и адреса (32 бит), что позволяет реализовать быстрые групповые операции перезагрузки внутренней кэш-памяти. Внешняя шина имеет также специальные сигналы управления, обеспечивающие аппаратную поддержку когерентности кэш-памяти в мультипроцессорных конфигурациях.
В процессоре имеются две двухканальные множественно-ассоциативные кэш-памяти емкостью по 8 Кбайт (для команд и для данных). Они имеют физическую адресацию. Все операции по перезагрузке кэш-памяти выполняются в режиме групповой пересылки данных, при этом первым пересылается требуемое слово. Когерентность кэша данных обеспечивается аппаратным протоколом наблюдения за шиной с четырьмя состояниями (MESI). Для увеличения производительности в кэш-памяти данных применяется стратегия задержанного обратного копирования.
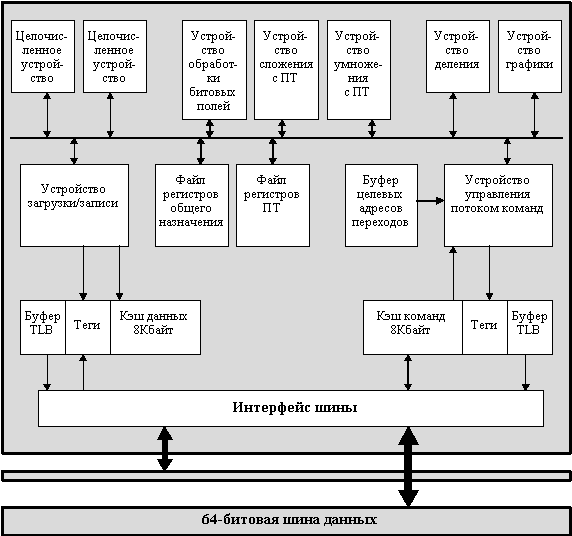
Рис. 8.8. Блок-схема процессора MC 88110
Суперскалярная архитектура процессора базируются на реализации возможности завершения команд не в порядке их поступления для выполнения, что позволяет существенно увеличить производительность, однако приводит к проблемам организации точного прерывания. Эта проблема решается в процессоре 88110 с помощью так называемого буфера истории, который хранит старые значения регистров при выполнении и завершении операций не в предписанном программой порядке, и позволяет аппаратно восстановить необходимое состояние в случае прерывания.
В процессоре предусмотрено несколько способов ускорения обработки условных переходов. Один из них, предсказание направления перехода, позволяет компилятору сообщить процессору предпочтительное направление перехода. Для выполняемых переходов используется буфер целевых адресов перехода емкостью 32 строки, позволяющий быстро выбрать две команды по целевому адресу перехода. Механизм предсказания направления переходов позволяет одновременно выполнять эти команды и оценивать условие перехода. Для предсказанного направления перехода разрешено спекулятивное (условное) выполнение команд. Если направление перехода предсказано неверно, исходное состояние процессора восстанавливается с помощью буфера истории. Выполнение программы в этом случае будет продолжено с "правильной" команды.
В каждом такте процессор может выдавать на выполнение две команды. В большинстве случаев выдача команд осуществляется в порядке, предписанном программой. Команды записи и условных переходов могут посылаться на буферные станции резервирования, из которых они в дальнейшем будут выданы на выполнение. Команды загрузки могут накапливаться в очереди. Таким образом эти команды не блокируют выдачу второй команды из пары. Большое количество исполнительных устройств позволяет осуществлять одновременную выдачу двух команд во многих ситуациях: 2 целочисленные команды, 2 команды с плавающей точкой, 2 графические команды или любая комбинация перечисленных команд.
В устройстве загрузки/записи реализован буфер загрузки FIFO на четыре строки и три станции резервирования операций записи, что позволяет иметь в каждый момент времени до 4 отложенных команд загрузки и до трех команд записи. Выполнение этих команд внутри устройства может переупорядочиваться для обеспечения большей эффективности.
При построении многопроцессорной системы все процессоры и основная память размещаются на одной плате. Для обеспечения хорошей производительности системы каждый процессор в такой конфигурации снабжается кэш-памятью второго уровня емкостью 256 Кбайт. Протокол поддержания когерентного состояния кэш-памяти (протокол наблюдения) базируется на методике записи с аннулированием, гарантирующей размещение модифицированной копии строки кэш-памяти только в одном из кэшей системы. Протокол позволяет нескольким процессорам иметь одну и ту же копию строки кэш-памяти. При этом, если один из процессоров выполняет запись в память (общую строку кэш-памяти), другие процессоры уведомляются о том, что их копии являются недействительными и должны быть аннулированы.
Архитектура MIPS была одной из первых RISC-архитектур, получившей признание со стороны промышленности. Она была анонсирована в 1986 году. Первоначально это была полностью 32-битовая архитектура, которая включала 32 регистра общего назначения длиною в 32 бит, 16 регистров плавающей точки и специальную пару регистров для хранения результатов выполнения операций целочисленного умножения и деления. Размер команд составлял 32 бит, в ней поддерживался всего один метод адресации, а адресное пространство также определялось 32 битами. Выполнение арифметических операций определялось стандартом IEEE 754. В компьютерной промышленности широкую популярность приобрели 32-битовые процессоры R2000 и R3000, которые в течение достаточно длительного времени служили основой для построения рабочих станций и серверов компаний Silicon Graphics, Digital, Siemens Nixdorf и др. Процессоры R3000/R3010 работали на тактовой частоте 33 или 40 МГц и обеспечивали производительность на уровне 20 SPECint92 и 23 SPECfp92.
На смену микропроцессорам семейства R3000 пришли новые 64-битовые микропроцессоры R4000 и R4400. (MIPS была первой в компьютерной промышленности компанией выпустившей процессоры с 64-битовой архитектурой). Набор команд этих процессоров (спецификация MIPS II) был расширен командами загрузки и записи 64-разрядных чисел с плавающей точкой, командами вычисления квадратного корня с одинарной и двойной точностью, командами условных прерываний, а также атомарными операциями, необходимыми для поддержки мультипроцессорных конфигураций. В процессорах R4000 и R4400 реализованы 64-битовые шины данных и 64-битовые регистры. В процессорах реализован метод удвоения внутренней тактовой частоты.
Процессоры R2000 и R3000 имели стандартные пятиступенчатые конвейеры команд. В процессорах R4000 и R4400 применяются более длинные конвейеры (иногда их называют суперконвейерами). Количество ступеней в процессорах R4000 и R4400 увеличилось до восьми, что объясняется прежде всего увеличением тактовой частоты и необходимостью распределения логики для обеспечения заданной пропускной способности конвейера. Процессор R4000 может работать с тактовой частотой 50/100 МГц и обеспечивает уровень производительности в 58 SPECint92 и 61 SPECfp92. Процессор R4400 может работать на частоте 50/100 МГц, или 75/150 МГц, показывая уровень производительности 94 SPECint92 и 105 SPECfp92.
Процессоры R4000 имели внутреннюю кэш-память емкостью 16 Кбайт, разделенную на 8-Кб кэш команд и 8-Кб кэш данных. С точки зрения реализации кэш-памяти процессор R4400 имеет более развитые возможности. Он выпускается в трех модификациях: PC (Primary Cash) - имеет внутренние кэши команд и данных емкостью по 16 Кбайт. Процессор в такой конфигурации предназначен главным образом для дешевых моделей рабочих станций. SC (Secondary Cash) содержит логику управления кэш-памятью второго уровня. MC (Multiprocessor Cash) - использует специальные алгоритмы обеспечения когерентности и согласованного состояния памяти для многопроцессорных конфигураций.
Компания MIPS объявила о создании своего нового суперскалярного процессора R10000, который в ближайшем будущем должен появиться на рынке. По заявлениям представителей MIPS Technology R10000 обеспечивает пиковую производительность в 800 MIPS при работе с внутренней тактовой частотой 200 МГц за счет обеспечения выдачи для выполнения четырех команд в одном такте синхронизации. При этом он обеспечивает обмен данными с кэш-памятью второго уровня со скоростью 3.2 Гбайт/с.
Чтобы обеспечить столь высокий уровень производительности в процессоре R10000 реализованы многие последние достижения в области технологии и архитектуры процессоров. На рис. 8.9 показана блок-схема этого микропроцессора.
Кэш-память данных первого уровня процессора R10000 имеет емкость 32 Кбайт и организована в виде двух одинаковых банков размером по 16 Кбайт, что обеспечивает двухкратное расслоение при выполнении обращений к этой кэш-памяти. Каждый банк представляет собой двухканальную множественно-ассоциативную кэш-память с размером строки (блока) в 32 байта. Кэш данных индексируется с помощью виртуального адреса и хранит теги физических адресов памяти. Такой метод индексации позволяет выбрать подмножество кэш-памяти в том же такте, в котором формируется виртуальный адрес. Однако для того, чтобы поддерживать когерентность с кэш-памятью второго уровня, в кэше первого уровня хранятся теги физических адресов памяти.
Интерфейс кэш-памяти второго уровня процессора R10000 поддерживает 128-битовую магистраль данных, которая может работать с тактовой частотой 200 МГц, обеспечивая скорость обмена 3.2 Гбайт/с. Все стандартные синхронные сигналы управления статической памятью вырабатываются внутри процессора. Минимальный объем кэш-памяти второго уровня составляет 512 Кбайт, максимальный размер - 16 Мбайт. Размер строки этой кэш-памяти программируется и может составлять 64 или 128 байт.
Объем внутренней двухканальной множественно-ассоциативной кэш-памяти команд составляет 32 Кбайт. Команды частично декодируются до их размещения в кэше команд. При этом к каждой команде добавляются 4 дополнительных бит, которые указывают исполнительное устройство, в котором она будет выполняться. Размер строки кэш-памяти команд составляет 64 байта.
Устройство переходов процессора может декодировать и выполнять одну команду перехода в каждом такте. Поскольку за каждой командой перехода следует слот задержки, максимально могут быть выбраны одновременно две команды перехода, но только одна более ранняя команда перехода может декодироваться в данный момент времени. Бит признака перехода добавляется к каждой команде во время декодирования команд. Эти биты используются для пометки команд перехода в конвейере выборки команд. Направление условного перехода прогнозируется с помощью специальной памяти, которая хранит историю выполнения переходов в прошлом. Двухбитовый код в этой памяти обновляется каждый раз, когда принято окончательное решение о направлении перехода. Все команды, выбранные вслед за командой условного перехода, считаются условными (спекулятивными). Это означает, что в момент их выборки заранее не известно, будет ли завершено их выполнение. Процессор допускает предварительное прогнозирование направления четырех команд условного перехода, которые могут разрешаться в произвольном порядке. Специальный стек переходов содержит строку на каждую выполняемую спекулятивно команду условного перехода. Каждая строка этого стека содержит информацию, необходимую для восстановления состояния процессора, если спекулятивные команды перехода были предсказаны неверно. Стек переходов позволяет быстро и эффективно восстановить конвейер, если прогноз направления перехода оказался неверным.
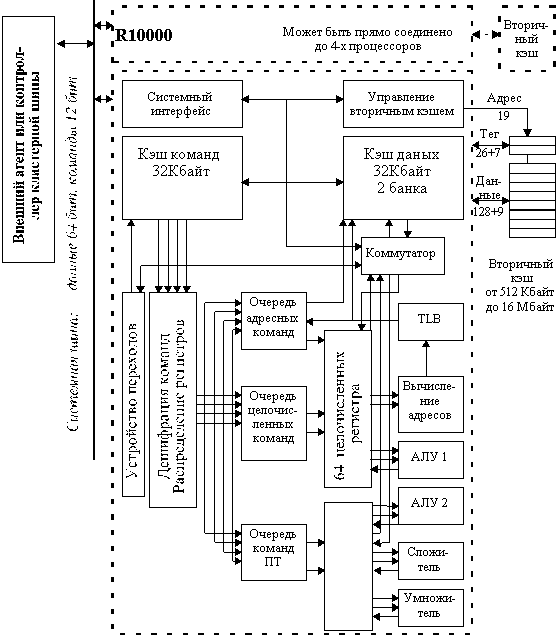
Рис. 8.9. Блок схема процессора R 10000
Процессор R10000 содержит три очереди (буфера) команд (очередь целочисленных команд, очередь команд плавающей точки и очередь адресных команд). Эти три очереди осуществляют выдачу команд в динамике в соответствующие исполнительные устройства. С каждой командой в очереди хранится тег команды, который перемещается вместе с командой по ступеням конвейера. Каждая очередь осуществляет динамическое планирование потока команд и может определить моменты времени, когда становятся доступными операнды, необходимые для каждой команды. Кроме того, очередь определяет порядок выполнения команд на основе анализа состояния соответствующих исполнительных устройств. Как только ресурс оказывается свободным очередь выдает команду в соответствующее исполнительное устройство.
Зависимости между командами могут привести к деградации производительности процессора. Чтобы этого избежать применяется специальная методика, которая называется методикой переименования регистров. Ее основная задача - определение зависимостей между командами и обеспечение точного адреса прерывания программы. В процессе переименования регистров каждый логический регистр, указанный в команде, заменяется физическим регистром на основе таблицы распределения регистров. Такое переименование происходит для каждого регистра результата команды. Поэтому, когда команда записывает в логический регистр новое значение, этот логический регистр переименовывается и будет использовать имя нового физического регистра. Однако, его предыдущее значение оказывается сохраненным в старом физическом регистре. Сохранение значений старого регистра позволяет обрабатывать точные прерывания. В то время как все команды переименовываются, логические номера их регистров сравниваются для определения зависимостей между четырьмя командами, декодированными в одном и том же такте.
В процессоре R10000 имеются пять полностью независимых исполнительных устройств: два целочисленных АЛУ, два основных устройства плавающей точки и два вторичных устройства плавающей точки, которые работают с длинными операциями, такими как деление и вычисление квадратного корня.
Устройство загрузки/записи содержит очередь адресов, устройство вычисления адреса, устройство преобразования виртуальных адресов в физические (TLB), стек адресов, буфер записи и кэш-память данных первого уровня. Устройство загрузки/записи выполняет команды загрузки, записи, предварительной выборки, а также команды работы с кэш-памятью.
Выполнение всех команд загрузки и записи начинается с трехтактной последовательности, во время которой осуществляется выдача команды, вычисление виртуального адреса и преобразование виртуального адреса в физический. Преобразование адреса осуществляется только однажды во время выполнения команды. Производится обращение к кэш-памяти данных и пересылка требуемых данных завершается при наличии данных в кэш-памяти первого уровня. В случае промаха, или в случае занятости требуемого разделяемого порта регистрового файла, обращение к кэшу данных и к тегу должно быть повторено после получения данных либо из кэш-памяти второго уровня, либо из основной памяти.
TLB содержит 64 строки и выполняет преобразование виртуального адреса в физический. Виртуальный адрес для преобразования поступает либо из устройства вычисления адреса, либо из счетчика команд.
Внешняя кэш-память второго уровня управляется с помощью внутреннего контроллера, который имеет специальный порт для подсоединения кэш-памяти. Специальная магистраль данных шириной в 128 бит осуществляет пересылки данных на тактовой частоте процессора 200 МГц. В процессоре имеется также 64-битовая шина данных системного интерфейса. Кэш-память второго уровня имеет двухканальную множественно-ассоциативную организацию. Максимальный размер - 16 Мбайт. Минимальный размер 512 Кбайт. Пересылки осуществляются 128-битовыми порциями (4 32-битовых слова). Для пересылки больших блоков данных используются последовательные циклы шины:
Системный интерфейс процессора R10000 работает в качестве шлюза между самим процессором и связанным с ним кэшем второго уровня и остальной системой. Системный интерфейс работает с тактовой частотой внешней синхронизации. Возможно программирование работы системного интерфейса на тактовой частоте 200, 133, 100, 80, 67, 57 и 50 МГц.
Процессор поддерживает протокол расщепления транзакций, позволяющий осуществлять выдачу очередных запросов процессором или внешним абонентом шины, не дожидаясь ответа на предыдущий запрос. Максимально поддерживается до четырех одновременных транзакций на шине.
Процессор R10000 допускает два способа организации многопроцессорной системы. Один из способов связан с созданием специального внешнего интерфейса для каждого процессора системы. Этот интерфейс обычно реализуется с помощью заказной интегральной схемы, которая организует шлюз к основной памяти и подсистеме ввода/вывода. При таком типе соединений процессоры не связаны друг с другом непосредственно, а взаимодействуют через этот специальный интерфейс. Хотя такая реализация общепринята, ее стоимость достаточно высока.
Второй способ предназначен для достижения максимальной производительности при минимальных затратах. Он подразумевает использование от двух до четырех процессоров, объединенных шиной Claster Bus. В этом случае необходим только один внешний интерфейс для взаимодействия с другими ресурсами системы.
В настоящее время семейство микропроцессоров с архитектурой Alpha представлено несколькими кристаллами, имеющими различные диапазоны производительности, работающие с разной тактовой частотой и рассеивающие разную мощность.
Первым на рынке появился 64-разрядный микропроцессор Alpha (DECchip 21064) . Он представляет собой RISC-процессор в однокристальном исполнении, в состав которого входят устройства целочисленной и плавающей арифметики, а также кэш-память емкостью 16 Кб. Кристалл проектировался с учетом реализации передовых методов увеличения производительности, включая конвейерную организацию всех функциональных устройств, одновременную выдачу нескольких команд для выполнения, а также средства организации симметричной многопроцессорной обработки.
В кристалле имеются два регистровых файла по 32 64-битовых регистра: один для целых чисел, второй - для чисел с плавающей точкой. Для обеспечения совместимости с архитектурами MIPS и VAX архитектура Alpha поддерживает арифметику с одинарной и двойной точностью как в соответствии со стандартом IEEE 754, так и в соответствии с внутренним для компании стандартом арифметики VAX.
Самая мощная модель процессора 21064 работает на частоте 200 МГц. В конце 1993 года появилась модернизированная версия кристалла - модель 21064А, имеющая на кристалле кэш-память удвоенного объема и работающая с тактовой частотой 275 МГц.
Затем были выпущены модели 21066 и 21068, оперирующие на частоте 166 и 66 МГц. Отличительной особенностью этой ветви процессоров Alpha является реализация на кристалле шины PCI. Это существенно упрощает и удешевляет как проектирование, так и производство компьютеров. Отличительная особенность модели 21068 - низкая потребляемая мощность (около 8 ватт). Основное предназначение этих двух новых моделей - персональные компьютеры и одноплатные ЭВМ.
На рис. 8.10 представлена блок-схема микропроцессора 21066. Основными компонентами этого процессора являются: кэш-память команд, целочисленное устройство, устройство плавающей точки, устройство выполнения команд загрузки/записи, кэш-память данных, а также контроллер памяти и контроллер ввода/вывода.
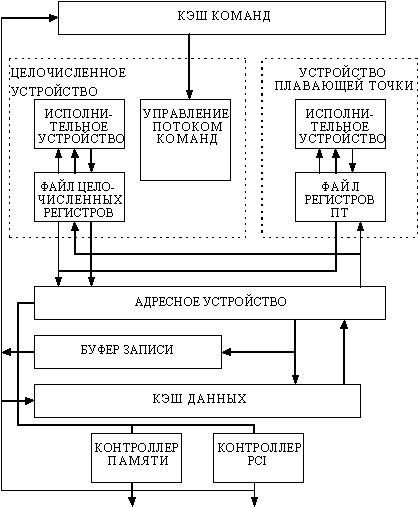
Рис. 8.10. Основные компоненты процессора Alpha 21066
Кэш-память команд представляет собой кэш прямого отображения емкостью 8 Кбайт. Команды, выбираемые из этой кэш-памяти, могут выдаваться попарно для выполнения в одно из исполнительных устройств. Кэш-память данных емкостью 8 Кбайт также реализует кэш с прямым отображением. При выполнении операций записи в память данные одновременно записываются в этот кэш и в буфер записи. Контроллер памяти или контроллер ввода/вывода шины PCI обрабатывают все обращения, которые проходят через расположенные на кристалле кэш-памяти первого уровня.
Контроллер памяти прежде всего проверяет содержимое внешней кэш-памяти второго уровня, которая построена на принципе прямого отображения и реализует алгоритм отложенного обратного копирования при выполнении операций записи. При обнаружении промаха контроллер обращается к основной памяти для перезагрузки соответствующих строк кэш-памяти. Контроллер ввода/вывода шины PCI обрабатывает весь трафик, связанный с вводом/выводом. Под управлением центрального процессора он выполняет операции программируемого ввода/вывода. Трафик прямого доступа к памяти шины PCI обрабатывается контроллером PCI совместно с контроллером памяти. При выполнении операций прямого доступа к памяти в режиме чтения и записи данные не размещаются в кэш-памяти второго уровня. Интерфейсы памяти и PCI были разработаны специально в расчете на однопроцессорные конфигурации и не поддерживают реализацию мультипроцессорной архитектуры.
На рис. 8.11 показан пример системы, построенной на базе микропроцессора 21066. В представленной конфигурации контроллер памяти выполняет обращения как к статической памяти, с помощью которой реализована кэш-память второго уровня, так и к динамической памяти, на которой построена основная память. Для хранения тегов и данных в кэш-памяти второго уровня используются кристаллы статическая памяти с одинаковым временем доступа по чтению и записи.

Рис. 8.11. Пример построения системы на базе микропроцессора Alpha 21066
Конструкция поддерживает до четырех банков динамической памяти, каждый из которых может управляться независимо, что дает определенную гибкость при организации памяти и ее модернизации. Один из банков может заполняться микросхемами видеопамяти (VRAM) для реализации дешевой графики. Контроллер памяти прямо работает с видеопамятью и поддерживает несколько простых графических операций.
Высокоскоростная шина PCI имеет ряд привлекательных свойств. Помимо возможности работы с прямым доступом к памяти и программируемым вводом/выводом она допускает специальные конфигурационные циклы, расширяемость до 64 бит, компоненты, работающие с питающими напряжениями 3.3 и 5 В, а также более быстрое тактирование. Базовая реализация шины PCI поддерживает мультиплексирование адреса и данных и работает на частоте 33 МГц, обеспечивая максимальную скорость передачи данных 132 Мбайт/с. Шина PCI непосредственно управляется микропроцессором. На рис. 8.11 показаны некоторые высокоскоростные периферийные устройства: графические адаптеры, контроллеры SCSI и сетевые адаптеры, подключенные непосредственно к шине PCI. Мостовая микросхема интерфейса ISA позволяет подключить к системе низкоскоростные устройства типа модема, флоппи-дисковода и т.д.
В настоящее время выпущена модернизированная версия этого микропроцессора. Как и его предшественник, новый кристалл Alpha 21066A помимо интерфейса PCI содержит на кристалле интегрированный контроллер памяти и графический акселератор. Эти характеристики позволяют значительно снизить стоимость реализации систем, базирующихся на Alpha 21066A, и обеспечивают простой и дешевый доступ к внешней памяти и периферийным устройствам. Alpha 21066A имеет две модификации в соответствии с частотой: 100 МГц и 233 МГц. Модель с 233 МГц обеспечивает производительность 94 и 100 единиц, соответственно, по тестам SPECint92 и SPECfp92.
Новейший микропроцессор Alpha 21164 представляет собой вторую полностью новую реализацию архитектуры Alpha. Микропроцессор 21164, представленный в сентябре 1994 года, обеспечивает производительность 330 и 500 единиц, соответственно, по шкалам SPECint92 и SPECfp92 или около 1200 MIPS и выполняет до четырех инструкций за такт. На кристалле микропроцессора 21164 размещено около 9,3 миллиона транзисторов, большинство из которых образуют кэш. Кристалл построен на базе 0.5 микронной КМОП технологии компании DEC. Он собирается в 499-контактные корпуса PGA (при этом 205 контактов отводятся под разводку питания и земли) и рассеивает 50 Вт при питающем напряжении 3.3 В на частоте 300 МГц.
Ключевыми моментами для реализации высокой производительности является суперскалярный режим работы процессора, обеспечивающий выдачу для выполнения до четырех команд в каждом такте, высокопроизводительная неблокируемая подсистема памяти с быстродействующей кэш-памятью первого уровня, большая, размещенная на кристалле, кэш-память второго уровня и уменьшенная задержка выполнения операций во всех функциональных устройствах.
На рис. 8.12 представлена блок-схема процессора, который включает пять функциональных устройств: устройство управления потоком команд (IBOX), целочисленное устройство (EBOX), устройство плавающей точки (FBOX), устройство управления памятью (MBOX) и устройство управления кэш-памятью и интерфейсом шины (CBOX). На рисунке также показаны три расположенных на кристалле кэш-памяти. Кэш-память команд и кэш-память данных представляют собой первичные кэши, реализующие прямое отображение. Множественно-ассоциативная кэш-память второго уровня предназначена для хранения команд и данных. Длина конвейеров процессора 21164 варьируется от 7 ступеней для выполнения целочисленных команд и 9 ступеней для реализации команд с плавающей точкой до 12 ступеней при выполнении команд обращения к памяти в пределах кристалла и переменного числа ступеней при выполнении команд обращения к памяти за пределами кристалла.
Устройство управления потоком команд осуществляет выборку и декодирование команд из кэша команд и направляет их для выполнения в соответствующие исполнительные устройства после разрешения всех конфликтов по регистрам и функциональным устройствам. Оно управляет выполнением программы и всеми аспектами обработки исключительных ситуаций, ловушек и прерываний. Кроме того, оно обеспечивает управление всеми исполнительными устройствами, контролируя все цепи обхода данных и записи в регистровый файл. Устройство управления содержит 8 Кбайт кэш команд, схемы предварительной выборки команд и связанный с ними буфер перезагрузки, схемы прогнозирования направления условных переходов и буфер преобразования адресов команд (ITB).
Целочисленное исполнительное устройство выполняет целочисленные команды, вычисляет виртуальные адреса для всех команд загрузки и записи, выполняет целочисленные команды условного перехода и все другие команды управления. Оно включает в себя регистровый файл и несколько функциональных устройств, расположенных на четырех ступенях двух параллельных конвейеров. Первый конвейер содержит сумматор, устройство логических операций, сдвигатель и умножитель. Второй конвейер содержит сумматор, устройство логических операций и устройство выполнения команд управления.
Устройство плавающей точки состоит из двух конвейерных исполнительных устройств: конвейера сложения, который выполняет все команды плавающей точки, за исключением команд умножения, и конвейер умножения, который выполняет команды умножения с плавающей точкой. Два специальных конвейера загрузки и один конвейер записи данных позволяют командам загрузки/записи выполняться параллельно с выполнением операций с плавающей точкой. Аппаратно поддерживаются все режимы округления, предусмотренные стандартами IEEE и VAX.
Устройство управления памятью выполняет все команды загрузки, записи и барьерные операции синхронизации. Оно содержит полностью ассоциативный 64-строчный буфер преобразования адресов (DTB), 8 Кбайт кэш-память данных с прямым отображением, файл адресов промахов и буфер записи. Длина строки в кэше данных равна 32 байтам, он имеет два порта по чтению и реализован по принципу сквозной записи. Он индексируется разрядами физического адреса и в тегах хранятся физические адреса. В устройство управления памятью в каждом такте может поступать до двух виртуальных адресов из целочисленного устройства. DTB также имеет два порта, поэтому он может одновременно выполнять преобразование двух виртуальных адресов в физические. Команды загрузки обращаются к кэшу данных и возвращают результат в регистровый файл в случае попадания. При этом задержка составляет два такта. В случае промаха физические адреса направляются в файл адресов промахов, где они буферизуются и ожидают завершения обращения к кэш-памяти второго уровня. Команды записи записывают данные в кэш данных в случае попадания и всегда помещают данные в буфер записи, где они ожидают обращения к кэш-памяти второго уровня.

Рис. 8.12. Блок-схема процессора Alpha 21164
Отличительной особенностью микропроцессора 21164 является размещение на кристалле вторичного трехканального множественно-ассоциативного кэша, емкостью 96 Кбайт. Вторичный кэш резко снижает количество обращений к внешней шине микропроцессора. Кроме вторичного кэша на кристалле поддерживается работа с внешним кэшем третьего уровня.
Сочетание большого количества вычислительных устройств, более быстрого выполнения операций с плавающей точкой (четыре такта вместо шести), более быстрого доступа к первичному кэшу (два такта вместо трех) обеспечивают новому микропроцессору рекордные параметры производительности.
Как уже было отмечено, одним из разработчиков фундаментальной концепции RISC-архитектуры был Джон Кук из Исследовательского центра IBM им. Уотсона, который в середине 70-х проводил исследования в этом направлении и построил миникомпьютер IBM 801, который так никогда и не появился на рынке. Дальнейшее развитие этих идей в компании IBM нашло отражение при разработке архитектуру POWER в конце 80-х. Архитектура POWER (и ее поднаправления POWER2 и PowerPC) в настоящее время являются основой семейства рабочих станций и серверов RISC System /6000 компании IBM.
Развитие архитектуры IBM 801 в направлении POWER шло в следующих направлениях: воплощение концепции суперскалярной обработки, улучшение архитектуры как целевого объекта компиляторов, сокращение длины конвейера и времени выполнения команд и, наконец, приоритетная ориентация на эффективное выполнение операций с плавающей точкой.
Архитектура POWER во многих отношениях представляет собой традиционную RISC-архитектуру. Она придерживается наиболее важных отличительных особенностей RISC: фиксированной длины команд, архитектуры регистр-регистр, простых способов адресации, простых (не требующих интерпретации) команд, большого регистрового файла и трехоперандного (неразрушительного) формата команд. Однако архитектура POWER имеет также несколько дополнительных свойств, которые отличают ее от других RISC-архитектур.
Во-первых, набор команд был основан на идее суперскалярной обработки. В базовой архитектуре команды распределяются по трем независимым исполнительным устройствам: устройству переходов, устройству с фиксированной точкой и устройству с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, где они могут выполняться одновременно и заканчиваться не в порядке поступления. Для увеличения уровня параллелизма, который может быть достигнут на практике, архитектура набора команд определяет для каждого из устройств независимый набор регистров. Это минимизирует связи и синхронизацию, требуемые между устройствами, позволяя тем самым исполнительным устройствам настраиваться на динамическую смесь команд. Любая связь по данным, требующаяся между устройствами, должна анализироваться компилятором, который может ее эффективно спланировать. Следует отметить, что это только концептуальная модель. Любой конкретный процессор с архитектурой POWER может рассматривать любое из концептуальных устройств как множество исполнительных устройств для поддержки дополнительного параллелизма команд. Но существование модели приводит к согласованной разработке набора команд, который естественно поддерживает степень параллелизма по крайней мере равную трем.
Во-вторых, архитектура POWER расширена несколькими "смешанными" командами для сокращения времен выполнения. Возможно единственным недостатком технологии RISC по сравнению с CISC, является то, что иногда она использует большее количество команд для выполнения одного и того же задания. Было обнаружено, что во многих случаях увеличения размера кода можно избежать путем небольшого расширения набора команд, которое вовсе не означает возврат к сложным командам, подобным командам CISC. Например, значительная часть увеличения программного кода была обнаружена в кодах пролога и эпилога, связанных с сохранением и восстановлением регистров во время вызова процедуры. Чтобы устранить этот фактор IBM ввела команды "групповой загрузки и записи", которые обеспечивают пересылку нескольких регистров в/из памяти с помощью единственной команды. Соглашения о связях, используемые компиляторами POWER, рассматривают задачи планирования, разделяемые библиотеки и динамическое связывание как простой, единый механизм. Это было сделано с помощью косвенной адресации посредством таблицы содержания (TOC - Table Of Contents), которая модифицируется во время загрузки. Команды групповой загрузки и записи были важным элементом этих соглашений о связях.
Другим примером смешанных команд является возможность модификации базового регистра вновь вычисленным эффективным адресом при выполнении операций загрузки или записи (аналог автоинкрементной адресации). Эти команды устраняют необходимость выполнения дополнительных команд сложения, которые в противном случае потребовались бы для инкрементирования индекса при обращениях к массивам. Хотя это смешанная операция, она не мешает работе традиционного RISC-конвейера, поскольку модифицированный адрес уже вычислен и порт записи регистрового файла во время ожидания операции с памятью свободен.
Архитектура POWER обеспечивает также несколько других способов сокращения времени выполнения команд такие как: обширный набор команд для манипуляции битовыми полями, смешанные команды умножения-сложения с плавающей точкой, установку регистра условий в качестве побочного эффекта нормального выполнения команды и команды загрузки и записи строк (которые работают с произвольно выровненными строками байтов).
Третьим фактором, который отличает архитектуру POWER от многих других RISC-архитектур, является отсутствие механизма "задержанных переходов". Обычно этот механизм обеспечивает выполнение команды, следующей за командой условного перехода, перед выполнением самого перехода. Этот механизм эффективно работал в ранних RISC-машинах для заполнения "пузыря", появляющегося при оценке условий для выбора направления перехода и выборки нового потока команд. Однако в более продвинутых, суперскалярных машинах, этот механизм может оказаться неэффективным, поскольку один такт задержки команды перехода может привести к появлению нескольких "пузырей", которые не могут быть покрыты с помощью одного архитектурного слота задержки. Почти все такие машины, чтобы устранить влияние этих "пузырей", вынуждены вводить дополнительное оборудование (например, кэш-память адресов переходов). В таких машинах механизм задержанных переходов становится не только мало эффективным, но и привносит значительную сложность в логику обработки последовательности команд. Вместо этого архитектура переходов POWER была организована для поддержки методики "предварительного просмотра условных переходов" (branch-lockahead) и методики "свертывания переходов" (branch-folding).
Методика реализации условных переходов, используемая в архитектуре POWER, является четвертым уникальным свойством по сравнению с другими RISC-процессорами. Архитектура POWER определяет расширенные свойства регистра условий. Проблема архитектур с традиционным регистром условий заключается в том, что установка битов условий как побочного эффекта выполнения команды, ставит серьезные ограничения на возможность компилятора изменить порядок следования команд. Кроме того, регистр условий представляет собой единственный архитектурный ресурс, создающий серьезное узкое горло в машине, которая параллельно выполняет несколько команд или выполняет команды не в порядке их появления в программе. Некоторые RISC-архитектуры обходят эту проблему путем полного исключения из своего состава регистра условий и требуют установки кода условий с помощью команд сравнения в универсальный регистр, либо путем включения операции сравнения в саму команду перехода. Последний подход потенциально перегружает конвейер команд при выполнении перехода. Поэтому архитектура POWER вместо того, чтобы исправлять проблемы, связанные с традиционным подходом к регистру условий, предлагает: a) наличие специального бита в коде операции каждой команды, что делает модификацию регистра условий дополнительной возможностью, и тем самым восстанавливает способность компилятора реорганизовать код, и b) несколько (восемь) регистров условий для того, чтобы обойти проблему единственного ресурса и обеспечить большее число имен регистра условий так, что компилятор может разместить и распределить ресурсы регистра условий, как он это делает для универсальных регистров.
Другой причиной выбора модели расширенного регистра условий является то, что она согласуется с организацией машины в виде независимых исполнительных устройств. Концептуально регистр условий является локальным по отношению к устройству переходов. Следовательно, для оценки направления выполнения условного перехода не обязательно обращаться к универсальному регистровому файлу (который является локальным для устройства с фиксированной точкой). Для той степени, с которой компилятор может заранее спланировать модификацию кода условия (и/или загрузить заранее регистры адреса перехода), аппаратура может заранее просмотреть и свернуть условные переходы, выделяя их из потока команд. Это позволяет освободить в конвейере временной слот (такт) выдачи команды, обычно занятый командой перехода, и дает возможность диспетчеру команд создавать непрерывный линейный поток команд для вычислительных исполнительных устройств.
Первая реализация архитектуры POWER появилась на рынке в 1990 году. С тех пор компания IBM представила на рынок еще две версии процессоров POWER2 и POWER2+, обеспечивающих поддержку кэш-памяти второго уровня и имеющих расширенный набор команд.
По данным IBM процессор POWER требует менее одного такта для выполнении одной команды по сравнению с примерно 1.25 такта у процессора Motorola 68040, 1.45 такта у процессора SPARC, 1.8 такта у Intel i486DX и 1.8 такта Hewlett-Packard PA-RISC. Тактовая частота архитектурного ряда в зависимости от модели меняется от 25 МГц до 62 МГц.
Процессоры POWER работают на частоте 33, 41.6, 45, 50 и 62.5 МГЦ. Архитектура POWER включает раздельную кэш-память команд и данных (за исключением рабочих станций и серверов рабочих групп начального уровня, которые имеют однокристальную реализацию процессора POWER и общую кэш-память команд и данных), 64- или 128-битовую шину памяти и 52-битовый виртуальный адрес. Она также имеет интегрированный процессор плавающей точки и таким образом хорошо подходит для приложений с интенсивными вычислениями, типичными для технической среды, хотя текущая стратегия RS/6000 нацелена как на коммерческие, так и на технические приложения. RS/6000 показывает хорошую производительность на плавающей точке: 134.6 SPECp92 для POWERstation/Powerserver 580. Это меньше, чем уровень моделей Hewlett-Packard 9000 Series 800 G/H/I-50, которые достигают уровня 150 SPECfp92.
Для реализации быстрой обработки ввода/вывода в архитектуре POWER используется шина Micro Channel, имеющая пропускную способность 40 или 80 Мбайт/сек. Шина Micro Channel включает 64-битовую шину данных и обеспечивает поддержку работы нескольких главных адаптеров шины. Такая поддержка позволяет сетевым контроллерам, видеоадаптерам и другим интеллектуальным устройствам передавать информацию по шине независимо от основного процессора, что снижает нагрузку на процессор и соответственно увеличивает системную производительность.
Многокристальный набор POWER2 состоит из восьми полузаказных микросхем (устройств):
Набор кристаллов POWER2 содержит порядка 23 миллионов транзисторов на площади 1217 квадратных мм и изготовлен по технологии КМОП с проектными нормами 0.45 микрон. Рассеиваемая мощность на частоте 66.5 МГц составляет 65 Вт.
Производительность процессора POWER2 по сравнению с POWER значительно повышена: при тактовой частоте 71.5 МГц она достигает 131 SPECint92 и 274 SPECfp92.
Компания IBM распространяет влияние архитектуры POWER в направлении малых систем с помощью платформы PowerPC. Архитектура POWER в этой форме может обеспечивать уровень производительности и масштабируемость, превышающие возможности современных персональных компьютеров. PowerPC базируется на платформе RS/6000 в дешевой конфигурации. В архитектурном плане основные отличия этих двух разработок заключаются лишь в том, что системы PowerPC используют однокристальную реализацию архитектуры POWER, изготавливаемую компанией Motorola, в то время как большинство систем RS/6000 используют многокристальную реализацию. Имеется несколько вариаций процессора PowerPC, обеспечивающих потребности портативных изделий и настольных рабочих станций, но это не исключает возможность применения этих процессоров в больших системах. Первым на рынке был объявлен процессор 601, предназначенный для использования в настольных рабочих станциях компаний IBM и Apple. За ним последовали кристаллы 603 для портативных и настольных систем начального уровня и 604 для высокопроизводительных настольных систем. Наконец, процессор 620 разработан специально для серверных конфигураций и ожидается, что со своей 64-битовой организацией он обеспечит исключительно высокий уровень производительности.
При разработке архитектуры PowerPC для удовлетворения потребностей трех различных компаний (Apple, IBM и Motorola) при сохранении совместимости с RS/6000, в архитектуре POWER было сделано несколько изменений в следующих направлениях:
Архитектура PowerPC поддерживает ту же самую базовую модель программирования и назначение кодов операций команд, что и архитектура POWER. В тех местах, где были сделаны изменения, которые могли потенциально препятствовать процессорам PowerPC выполнять существующие двоичные коды RS/6000, были расставлены "ловушки", обеспечивающие прерывание и эмуляцию с помощью программного обеспечения. Такие изменения вводились, естественно, только в тех случаях, если соответствующая возможность либо использовалась не очень часто в кодах прикладных программ, либо была изолирована в библиотечных программах, которые можно просто заменить.
PowerPC 601
Первый микропроцессор PowerPC, PowerPC 601, в настоящее время выпускается как компанией IBM, так и компанией Motorola. Он представляет собой процессор среднего класса и предназначен для использования в настольных вычислительных системах малой и средней стоимости. Он был разработан в качестве переходной модели от архитектуры POWER к архитектуре PowerPC и реализует возможности обеих архитектур. При этом двоичные коды RS/6000 выполняются на нем без изменений, что дало дополнительное время разработчикам компиляторов для освоения архитектуры PowerPC, а также разработчикам прикладных систем, которые должны перекомпилировать свои программы, чтобы полностью использовать возможности архитектуры PowerPC.
Процессор 601 базировался на однокристальном процессоре IBM, который был разработан к моменту создания альянса трех ведущих фирм. Но по сравнению со своим предшественником, PowerPC 601 претерпел серьезные изменения в сторону повышения производительности и снижения стоимости. Например, в его состав было включено более сложное устройство переходов, расширенные возможностями мультипроцессорной работы, включая интерфейс шины высокопроизводительного процессора 88110 компании Motorola. В Power 601 реализована суперскалярная обработка, позволяющая выдавать на выполнение в каждом такте 3 команды, возможно не в порядке их расположения в программном коде.
Процессор PowerPC 603
PowerPC 603 является первым микропроцессором в семействе PowerPC, который полностью поддерживает архитектуру PowerPC (рис. 8.13). Он включает пять функциональных устройств: устройство переходов, целочисленное устройство, устройство плавающей точки, устройство загрузки/записи и устройство системных регистров, а также две, расположенных на кристалле кэш-памяти для команд и данных, емкостью по 8 Кбайт. Поскольку PowerPC 603 - суперскалярный микропроцессор, он может выдавать в эти исполнительные устройства и завершать выполнение до трех команд в каждом такте. Для увеличения производительности PowerPC 603 допускает внеочередное выполнение команд. Кроме того он обеспечивает программируемые режимы снижения потребляемой мощности, которые дают разработчикам систем гибкость реализации различных технологий управления питанием.
При обработке в процессоре команды распределяются по пяти исполнительным устройствам в заданном программой порядке. Если отсутствуют зависимости по операндам, выполнение происходит немедленно. Целочисленное устройство выполняет большинство команд за один такт. Устройство плавающей точки имеет конвейерную организацию и выполняет операции с плавающей точкой как с одинарной, так и с двойной точностью. Команды условных переходов обрабатывается в устройстве переходов. Если условия перехода доступны, то решение о направлении перехода принимается немедленно, в противном случае выполнение последующих команд продолжается по предположению (спекулятивно). Команды, модифицирующие состояние регистров управления процессором, выполняются устройством системных регистров. Наконец, пересылки данных между кэш-памятью данных, с одной стороны, и регистрами общего назначения и регистрами плавающей точки, с другой стороны, обрабатываются устройством загрузки/записи.
В случае промаха при обращении к кэш-памяти, обращение к основной памяти осуществляется с помощью 64-битовой высокопроизводительной шины, подобной шине микропроцессора MC88110. Для максимизации пропускной способности и, как следствие, увеличения общей производительности кэш-память взаимодействует с основной памятью главным образом посредством групповых операций, которые позволяют заполнить строку кэш-памяти за одну транзакцию.
После окончания выполнения команды в исполнительном устройстве ее результаты направляются в буфер завершения команд (completion buffer) и затем последовательно записываются в соответствующий регистровый файл по мере изъятия команд из буфера завершения. Для минимизации конфликтов по регистрам, в процессоре PowerPC 603 предусмотрены отдельные наборы из 32 целочисленных регистров общего назначения и 32 регистров плавающей точки.
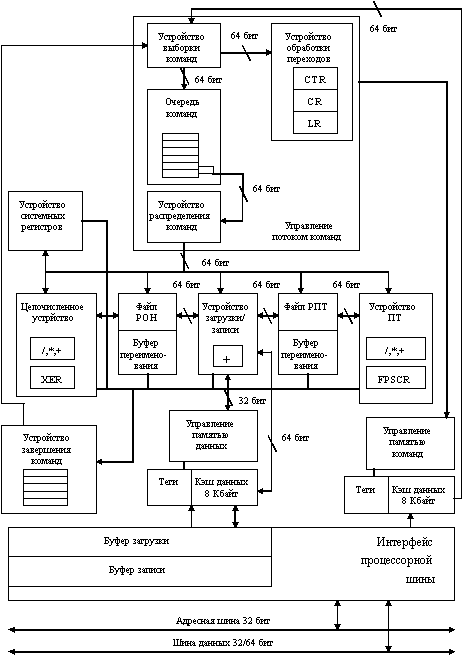
Рис. 8.13. Блок-схема процессора Power PC 603
PowerPC 604
Суперскалярный процессор PowerPC 604 обеспечивает одновременную выдачу до четырех команд. При этом параллельно в каждом такте может завершаться выполнение до шести команд. На рис. 8.14 представлена блок-схема процессора 604. Процессор включает шесть исполнительных устройств, которые могут работать параллельно:
Рис. 8.14. Блок-схема процессора Power PC 604
Такая параллельная конструкция в сочетании со спецификацией команд PowerPC, допускающей реализацию ускоренного выполнения команд, обеспечивает высокую эффективность и большую пропускную способность процессора. Применяемые в процессоре 604 буфера переименования регистров, буферные станции резервирования, динамическое прогнозирование направления условных переходов и устройство завершения выполнения команд существенно увеличивают пропускную способность системы, гарантируют завершение выполнения команд в порядке, предписанном программой, и обеспечивают реализацию модели точного прерывания.
В процессоре 604 имеются отдельные устройства управления памятью и отдельные по 16 Кбайт внутренние кэши для команд и данных. В нем реализованы два буфера преобразования виртуальных адресов в физические TLB (отдельно для команд и для данных), содержащие по 128 строк. Оба буфера являются двухканальными множественно-ассоциативными и обеспечивают переменный размер страниц виртуальной памяти. Кэш-памяти и буфера TLB используют для замещения блоков алгоритм LRU.
Процессор 604 имеет 64-битовую внешнюю шину данных и 32-битовую шину адреса. Интерфейсный протокол процессора 604 позволяет нескольким главным устройствам шины конкурировать за системные ресурсы при наличии централизованного внешнего арбитра. Кроме того, внутренние логические схемы наблюдения за шиной поддерживают когерентность кэш-памяти в мультипроцессорных конфигурациях. Процессор 604 обеспечивает как одиночные, так и групповые пересылки данных при обращении к основной памяти.
PowerPC 620
К концу 1995 года ожидается появление нового процессора PowerPC 620. В отличие от своих предшественников это будет полностью 64-битовый процессор. При работе на тактовой частоте 133 МГц его производительность оценивается в 225 единиц SPECint92 и 300 единиц SPECfp92, что соответственно на 40 и 100% больше показателей процессора PowerPC 604.
Подобно другим 64-битовым процессорам, PowerPC 620 содержит 64-битовые регистры общего назначения и плавающей точки и обеспечивает формирование 64-битовых виртуальных адресов. При этом сохраняется совместимость с 32-битовым режимом работы, реализованным в других моделях семейства PowerPC.
В процессоре имеется кэш-память данных и команд общей емкостью 64 Кбайт, интерфейсные схемы управления кэш-памятью второго уровня, 128-битовая шина данных между процессором и основной памятью, а также логические схемы поддержания когерентного состояния памяти при организации многопроцессорной системы.
Процессор PowerPC 620 нацелен на рынок высокопроизводительных рабочих станций и серверов.
|
|
