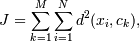
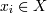 -
объект кластеризации (точка)
-
объект кластеризации (точка) 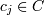 - центр кластера
(центроид). | X | = N, | C | =
M
- центр кластера
(центроид). | X | = N, | C | =
M Что делать, если нет обучающего материала для построения классификатора? То есть нет учителя, который покажет, как следует классифицировать тот или иной объект?
В этом случае следует прибегнуть к кластеризации (или кластерному анализу). Кластеризация - это обучение без учителя. При этом она выполняет схожие с классификацией задачи: позволяет создать определенные правила, с помощью которых в дальнейшем можно относить объекты к различным классам (группам). Однако, в отличие от классификации, кластеризация эти группы еще и выявляет в наборе объектов различными способами. Объект группируются, исходя из их сходства, или близости.
Общий алгоритм кластеризации выглядит так:
Рассмотрим каждый из этапов более подробно.
На первом этапе происходит подготовка данных к кластеризации. Данные для кластеризации чаще всего представляют в виде таблиц, где каждый столбец - это один из атрибутов, строка - объект данных.
На втором этапе выбирают, как охарактеризовать сходство объектов. Для этого используются различные меры близости, то есть, фактически, оценки близости двух объектов друг к другу. Меры близости выбирают, исходя из свойств объектов. Так, популярной мерой близости является декартово расстояние (в двумерном случае): d2( < x1,y1 > , < x2,y2 > ) = sqrt((x1 − x2)2 + (y1 − y2)2) или метрика Минковского в многомерном случае: dn(x,y) = | | X,Y | | Это достаточно хорошие меры близости для представимых на координатной плоскости значений. Для нечисленных атрибутов подбирают такие меры близости, которые позволяют свести их к численным и сравнить. Так, основным расстоянием для строк является метрика Левенштейна, которая устанавливает расстояние между двумя строками равным количеству перестановок, которые необходимо совершить, чтобы превратить одну строку в другую. Мера близости подбирается индивидуально для конкретных типов данных. Иногда адекватной меры близости подобрать не удается, и приходится ее придумывать самим.
На третьем этапе выбирают алгоритм, по которому мы будем строить модель данных, то есть группировать объекты. Выбор алгоритма сложен, и зачастую приходится использовать несколько алгоритмов прежде, чем будет получен нужный (интерпретируемый) результат. Иногда алгоритмы кластеризации комбинируют, чтобы получить метаалгоритм, результат выполнения одного когда служит промежуточным результатом выполнения другого.
На четвертом этапе алгоритм реализуется, и его результатом является построенная модель данных, то есть группировка объектов по кластерам.
На пятом этапе полученную группировку пытаются представить в наиболее удобном для интерпретации виде. Алгоритмы кластеризации на выходе выдают только группы и объекты, к ним принадлежащие. Но для человека наиболее интересным является не это чаще всего, а то, исходя из чего - каких свойств объекта - эти объекты были отнесены к определенной группе. Представление результатов кластеризации призвано помочь наиболее точно интерпретировать результаты выполнения алгоритма.
И, наконец, на последнем этапе кластеризации результаты выполнения алгоритма интерпретируются, из них получается знание, то есть полезные правила, которые можно использовать в дальнейшем для отнесения новых объектов к той или иной группе - кластеру.
Принято делить все алгоритмы кластеризации на иерархические и неиерархические. Деление это происходит по выдаваемым на выходе данным. Иерархические алгоритмы на выходе выают некую иерархию кластеров, и мы вольны выбрать любой уровень этой иерархии для того, чтобы интерпретировать результаты алгоритма. Неиерархические - это, фактически, все алгоритмы, которые на выходе иерархию не выдают (или выбор интерпретации происходит не по уровню иерархии).
Иерархические алгоритмы делятся на агломеративные и дивизимные. Агломеративные алгоритмы - это алгоритмы, которые начинают свое выполнение с того, что каждый объект заносят в свой собственный кластер и по мере выполнения объединяют кластеры, до тех пор, пока в конце не получает один кластер, включающий в себя все объекты набора. Дивизимные алгоритмы, напротив, сначала относят все объекты в один кластер и затем разделяют этот кластер до тех пор, пока каждый объект не окажется в своем собственном кластере.
Представлением результата иерархического алгоритма является дендрограмма - схема, показывающая, в какой последовательности происходило слияние объектов в кластер/разделение объектов на кластеры.
Достаточно ярким примером иерархического агломеративного алгоритма является
алгоритм "соседей". Это алгоритмы ближнего, дальнего и среднего соседей. Он
объединяет кластеры, исходя из расстояния между ближайшими, наиболее удаленными
или центральными объектами кластеров. Рассмотрим схему выполнения алгоритма
ближайшего соседа:
Результаты выполнения этого алгоритма хорошо представимы в виде дендрограммы, а кластеры на каждом из этапов его выполнения легко получимы путем проведения линии, перпедикулярной направлению распространения этой дендрограммы.
Итеративные алгоритмы называются так потому, что итеративно перераспределяют объекты между кластерами.
Общая идея алгоритмов *-means: Минимизация расстояний между объектами в
кластерах. Останов происходит, когда минимизировать расстояния больше уже
невозможно. Минимизируемая функция в случае k-means такова: -
объект кластеризации (точка) - центр кластера
(центроид). | X | = N, | C | =
M
На момент старта алгоритма должно быть известно число С (количество кластеров). Выбор числа С может базироваться на результатах предшествующих исследований, теоретических соображениях или интуиции.
Описание алгоритма 0. Первоначальное распределение объектов по кластерам.
Выбираются С точек. На первом шаге эти точки считаются центрами кластеров. Выбор
начальных центроидов может осуществляться путем подбора наблюдений для
максимизации начального расстояния, случайным выбором наблюдений или выбором
первых наблюдений.
1. Итеративное перераспределение объектов по кластерам. Объекты распределяются по кластерам путем подсчета расстояния от объекта до центров кластеров и выбора наименьшего.
2. Когда все объекты распределены по кластерам, заново считаются их центры.
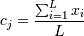
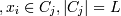 (можно считать по
каждой координате отдельно)
(можно считать по
каждой координате отдельно)
3. Если cj = cj − 1, то это означает, что кластерные центры стабилизировались и соответственно распределение закончено. Иначе переходим к шагу 1.
Сложным является выбор числа кластеров. В случае, если предположений нет, обычно делают несколько попыток, сравнивая результаты (скажем, сначала 2, потом 3 и т.д.). Проверка качества кластеризации После получений результатов кластерного анализа методом k-средних следует проверить правильность кластеризации (т.е. оценить, насколько кластеры отличаются друг от друга). Для этого рассчитываются средние значения для каждого кластера. При хорошей кластеризации должны быть получены сильно отличающиеся средние для всех измерений или хотя бы большей их части. Достоинства алгоритма k-средних:
Недостатки алгоритма k-средних:
Возможным решением этой проблемы является использование модификации алгоритма - алгоритм k-медианы;
данной проблемы является использование выборки данных.
Более строгой интерпретацией этого алгоритма является алгоритм hard c-means. Его отличия - в минимизируемой функции и строгости самого алгоритма:
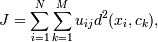 uij = 1, если
uij = 1, если 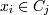 , и uij = 0,, если нет. То есть
минимизируется расстояние от точек до центроида, а не от центроида до точек.
, и uij = 0,, если нет. То есть
минимизируется расстояние от точек до центроида, а не от центроида до точек.
Тогда формула центроида тоже несколько меняется:
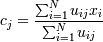
Сам же метод не меняется.
Farthest First - еще одна модификация k-means, особенностью его является изначальный выбор центроидов - от 2 и выше они выбираются по принципу удаленности от остальных(центроидом выбирается точка, наиболее отдаленная от остальных центроидов).
Нечеткие методы - это методы, основанные не на бинарной логике - где все четко - элемент либо принадлежит одному кластеру, либо другому - а на предположении, что каждый элемент в какой-то степени принадлежит определенному кластеру. m - мера нечеткости, она как раз определяет нечеткость алгоритма. Минимизируемая функция почти аналогична hard c-means:
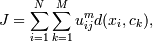
0. Выбираем число классов M, меру нечеткости 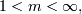 функцию расстояний
d(c,x) (обычно d(c,x) = | | x −
c | | 2), критерий окончания поиска 0 < ε < 1. Задаем матрицу
функцию расстояний
d(c,x) (обычно d(c,x) = | | x −
c | | 2), критерий окончания поиска 0 < ε < 1. Задаем матрицу 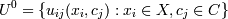 весов принадлежности
точки к кластеру
весов принадлежности
точки к кластеру 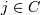 с центром cj для всех точек и кластеров
(можно взять принадлежности к кластеру из k-means или просто по рандому,
ограничения
с центром cj для всех точек и кластеров
(можно взять принадлежности к кластеру из k-means или просто по рандому,
ограничения 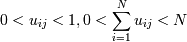 для
для 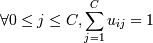 для
для 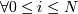 (вытекают в общем из
определения нечеткой принадлежности)).
(вытекают в общем из
определения нечеткой принадлежности)).
1. Вычисляем центроиды :
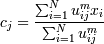
2. Перевычисляем веса :
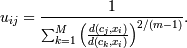
3. Проверяем | | Uk −
Uk − 1 | | < ε (чаще всего достаточно 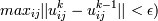 - если да, то
заканчиваем, если нет, то переходим к шагу 1.
- если да, то
заканчиваем, если нет, то переходим к шагу 1.
Другой класс алгоритмов - плотностные. Они так называются потому, что определяют кластер как группу объектов,расположенных достаточно кучно. Под кучностью понимают то, что в эпсилон-окрестности точки есть некоторое минимальное количество других объектов: d(xi,xj) < ε для некоторого количества j > Minpts.
Алгоритм DBSCAN обычно проводится над данными, упорядоченными в R-деревья (для удобства выборки окрестных точек). Но в общем случае этого не требует.
0. Выбираем окрестность ε, в которой мы будем требовать наличия Minpts объектов, и сам Minpts.
1. Берем произвольный еще не обработанный объект. Проверяем для него, что в эпсилон-окрестности точки есть некоторое минимальное количество других объектов: d(xi,xj) < ε для некоторого количества j > Minpts. Если это не так, то очевидно, что эта точка - шум. Берем следующую.
2. Если это не так, то помечаем эту точку как принадлежащую кластеру. Это так называемая корневая точка. Заносим окружающие ее точки в отдельную категорию.
2.1. Для каждой еще не обработанной точки из этой категории сначала помечаем ее как принадлежащую кластеру, а затем проверяем то же самое: что в эпсилон-окрестности точки есть некоторое минимальное количество других объектов: d(xi,xj) < ε для некоторого количества j > Minpts. Если это так, то заносим эти точки в эту же категорию.
2.2. После проверки выносим точку из этой временной категории. Очевидно, что рано или поздно точки в данной категории кончатся (мы достигнем границ кластера, где правило кучности не выполняется). Тогда переходим к шагу 1. Иначе возвращаемся к шагу 2.1.
Этот алгоритм имеет сложность O(NlogN). Очевидно, что основным его недостатком является неспособность связывать кластеры через узкие места, где правило плотности не выполняется.
Модельные алгоритмы подразумевают, что у нас есть некоторая модель кластера (его структуры), и мы стремимся найти и максимизировать сходства между этой моделью и имеющимися у нас данными, то есть выделить в данных такие модели, которые и будут кластерами. Часто при этом для представления моделей используется широко разработанный аппарат математической статистики.
Предполагается, что кроме известных нам из наших данных величин существуют еще и неизвестные нам, относящиеся к распределению по кластерам. То есть фактически эти неизвестные "создают" кластер, а мы наблюдаем только результат их деятельности. И именно эти неизвестные мы и стараемся максимально точно оценить.
Алгоритм использует широко известный метод максимизации ожиданий (Expectation
Maximization). В наиболее простом случае предполагается, что кластер - это
результаты наблюдений, распределенные нормально. Тогда для их характеристики
можно применять многомерную функцию Гаусса (многомерное распределение Гаусса)
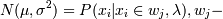 - одно из
распределений. И тогда основная задача - это определить, к какому из
распределений принадлежит каждая конкретная точка, оценив параметры этих
распределений исходя из реального распределения точек.
- одно из
распределений. И тогда основная задача - это определить, к какому из
распределений принадлежит каждая конкретная точка, оценив параметры этих
распределений исходя из реального распределения точек.
0. Инициализируем : 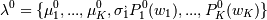 - среднее отклонение
распределений относительно начала координат (т.е. центры кластеров) и
вероятности этих распределений для каждой точки. K - число кластеров - задаем.
- среднее отклонение
распределений относительно начала координат (т.е. центры кластеров) и
вероятности этих распределений для каждой точки. K - число кластеров - задаем.
1. E-шаг:
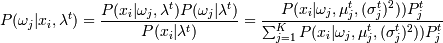 ,
,
где 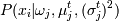 -функция плотности
распределения.
-функция плотности
распределения.
2. М-шаг:
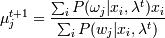
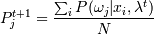
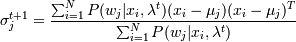
3. Вычисление 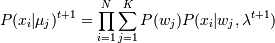 и сравнение с P(xi |
μj)t, если да, то стоп - найден
локальный максимум. Если нет, то переходим снова к шагу 1.
и сравнение с P(xi |
μj)t, если да, то стоп - найден
локальный максимум. Если нет, то переходим снова к шагу 1.
В алгоритме COBWEB реализовано вероятностное представление категорий. Принадлежность категории определяется не набором значений каждого свойства объекта, а вероятностью появления значения. Например, P(Aj = υij | Ck) - это условная вероятность, с которой свойство Aj, принимает значение υij, если объект относится к категории Ck. Для каждой категории в иерархии определены вероятности вхождения всех значений каждого свойства. При предъявлении нового экземпляра система COBWEB оценивает качество отнесения этого примера к существующей категории и модификации иерархии категорий в соответствии с новым представителем. Критерием оценки качества классификации является полезность категории (category utility). Критерий полезности категории был определен при исследовании человеческой категоризации. Он учитывает влияние категорий базового уровня и другие аспекты структуры человеческих категорий.
Критерий полезности категории максимизирует вероятность того, что два объекта, отнесенные к одной категории, имеют одинаковые значения свойств и значения свойств для объектов из различных категорий отличаются. Полезность категории определяется формулой
| CU = | ∑ | ∑ | ∑ | P(A = υij | Ck)P(Ck | A = υij)P(A = υij) |
| k | i | j |
Значения суммируются по всем категориям Ck, всем свойствам Aj и всем значениям свойств υij. Значение P(Aj = υij | Ck) называется предсказуемостью (predictability). Это вероятность того, что объект, для которого свойство Aj- принимает значение υij, относится к категории Ck. Чем выше это значение, тем вероятнее, что свойства двух объектов, отнесенных к одной категории, имеют одинаковые значения. Величина P(Ck | A = υij) называется предиктивностью (predictiveness). Это вероятность того, что для объектов из категории Ck свойство Aj принимает значение υij. Чем больше эта величина, тем менее вероятно, что для объектов, не относящихся к данной категории, это свойство будет принимать указанное значение. Значение P(A = υij) - это весовой коэффициент, усиливающий влияние наиболее распространенных свойств. Благодаря совместному учету этих значений высокая полезность категории означает высокую вероятность того, что объекты из одной категории обладают одинаковыми свойствами, и низкую вероятность наличия этих свойств у объектов из других категорий.
После некоторых преобразований (Байеса в частности) и некоторых агрументированных изменений мы получаем более правильную формулу:
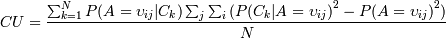 N -число категорий.
N -число категорий.
Алгоритм COBWEB имеет следующий вид.
cobweb(Node, Instance)
Begin
if узел Node - это лист, then
begin
создать два дочерних узла L1 и L2 для узла Node;
задать для узла L1 те же вероятности, что и для узла Node;
инициализировать вероятности для узла L2 соответствующими значениями объекта Instance;
добавить Instance к Node, обновив вероятности для узла Node ;
end
else
begin
добавить Instance к Node, обновив вероятности для узла Node;
для каждого дочернего узла С узла Node вычислить полезность категории при отнесении экземпляра Instance к категории С;
пусть S1 - значение полезности для наилучшей классификации C1;
пусть S2 - значение для второй наилучшей классификации C2;
пусть S3 - значение полезности для отнесения экземпляра к новой категории;
пусть S4 - значение для слияния C1 и C2 в одну категорию;
пусть S5 - значение для разделения C1 (замены дочерними категориями);
end
if S1 - максимальное значение CU, then
cobweb(C1, Instance) %отнести экземпляр к C1
else
if S3 - максимальное значение CU, then
инициализировать вероятности для новой категории Cm значениями Instance
else
if S4 - максимальное значение CU, then
begin
пусть Cm - результат слияния C1 и C2;
cobweb(Cm, Instance);
end
else
if S5 - максимальное значение CU, then
begin
разделить C1; % Cm - новая категория
cobweb(Cm, Instance)
end;
end
В алгоритме COBWEB реализован метод поиска экстремума в пространстве возможных кластеров с использованием критерия полезности категорий для оценки и выбора возможных способов категоризации.
Сначала вводится единственная категория, свойства которой совпадают со свойствами первого экземпляра. Для каждого последующего экземпляра алгоритм начинает свою работу с корневой категории и движется далее по дереву. На каждом уровне выполняется оценка эффективности категоризации на основе полезности категории. При этом оцениваются результаты следующих операций:
Для слияния двух узлов создается новый узел, для которого существующие узлы становятся дочерними. На основе значений вероятностей дочерних узлов вычисляются вероятности для нового узла. При разбиении один узел заменяется двумя дочерними.
Этот алгоритм достаточно эффективен и выполняет кластеризацию на разумное число классов. Поскольку в нем используется вероятностное представление принадлежности, получаемые категории являются гибкими и робастными. Кроме того, в нем проявляется эффект категорий базового уровня, поддерживается прототипирование и учитывается степень принадлежности. Он основан не на классической логике, а, подобно методам теории нечетких множеств, учитывает "неопределенность" категоризации как необходимый компонент обучения и рассуждений в гибкой и интеллектуальной манере.
Алгоритм рассматривает всю совокупность данных как сигнал в N-мерном пространстве атрибутов и пытается на основании вейвлет-преобразования выделить в этом сигнале поддиапазоны частот, в которых связанные компоненты и будут кластерами.
Для применения алгоритма надо выбрать, какой именно фильтр будет применяться (какое именно из вейвлет-преобразований будет применяться).
0. Квантификация данных. Именно за это алгоритм называется сетевым. Каждое
l-ное , 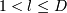 измерение D-мерного
пространства данных (то есть каждый атрибут) разделяется на ml отрезков длиной sl. Тогда в D-мерном пространстве
существует N точек Mj =
(μ1,...,μl,...,μd), где
μ - это некоторое количество отрезков длиной sl. Тогда
измерение D-мерного
пространства данных (то есть каждый атрибут) разделяется на ml отрезков длиной sl. Тогда в D-мерном пространстве
существует N точек Mj =
(μ1,...,μl,...,μd), где
μ - это некоторое количество отрезков длиной sl. Тогда 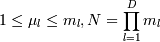 (если число ml = m одинаково по всем
осям, то N = mD) .
(если число ml = m одинаково по всем
осям, то N = mD) .
И тогда объекту 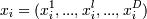 назначается в
сооветствие Mj, когда для
каждого l
назначается в
сооветствие Mj, когда для
каждого l 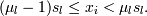 Фактически мы разбили
все D-мерное пространство, в котором расположены наши объекты, на некую
совокупность D-мерных прямоугольных призм (кубиков), характеризуемых наиболее
дальней от начала координат точкой призмы Mj и каждому кубику назначили в
соответствие все те объекты, которые попали внутрь него.
Фактически мы разбили
все D-мерное пространство, в котором расположены наши объекты, на некую
совокупность D-мерных прямоугольных призм (кубиков), характеризуемых наиболее
дальней от начала координат точкой призмы Mj и каждому кубику назначили в
соответствие все те объекты, которые попали внутрь него.
1. Применение вейвлет-преобразования. Теперь мы применяем дискретное вейвлет-преобразование к этим точкам Mj. Тогда на выходе мы получаем новую совокупность точек Tk в новом пространстве признаков. Оно в общем уже незначащее, но зато в нем точки группируются, они как бы стягиваются в области сильной связности. Это особенность вейвлет-преобразований - они увеличивают плотность кластера. Количество точек и количество кластеров в них зависит от конкретного вейвлет-преобразования и от количества его прогонов - чем оно более сложное и чем больше прогонов, тем меньше точек и кластеров.
2. Обнаружение кластеров в измененном пространстве признаков. В измененном пространстве признаков ищутся связанные компоненты </math>T_k</math>. Они являются кластерами. Более того, в общем случае многомерного пространства можно искать в подпространствах, которые также формируются вейвлет-преобразованием и в которых поиск гораздо легче в силу меньшей размерности этих пространств. В результате поиск сводится к поиску связанных компонент в двумерной картинке. В первом проходе находятся все связанные компоненты в картинке, и во втором - им назначают метки кластеров, отбрасывая уже отмеченные. Тогда мы получаем некоторое количество кластеров С и их меток cf.
3. Создание таблицы соответствия. На этом этапе через соответствие исходных точек Mj и полученных в результате преобразования Tk создается таблица соответствия. Соотвествие этих точек для каждого из фильтров разное, но всегда прослеживается, несмотря на то, что преобразование не всегда обратимо. Простейшим соответствием явлются индексы. В результате мы получаем принадлежность Mj к определенному кластеру cf.
4. А так как мы знаем, каким точкам соответствует Mj, мы получаем и соответствие этих кластеров конкретным точкам.
|
|
