Основная цель
Термин кластерный анализ (впервые ввел Tryon, 1939) в действительности включает в себя набор различных алгоритмов классификации. Общий вопрос, задаваемый исследователями во многих областях, состоит в том, как организовать наблюдаемые данные в наглядные структуры, т.е. развернуть таксономии. Например, биологи ставят цель разбить животных на различные виды, чтобы содержательно описать различия между ними. В соответствии с современной системой, принятой в биологии, человек принадлежит к приматам, млекопитающим, амниотам, позвоночным и животным. Заметьте, что в этой классификации, чем выше уровень агрегации, тем меньше сходства между членами в соответствующем классе. Человек имеет больше сходства с другими приматами (т.е. с обезьянами), чем с "отдаленными" членами семейства млекопитающих (например, собаками) и т.д. В последующих разделах будут рассмотрены общие методы кластерного анализа, см. Объединение (древовидная кластеризация), Двувходовое объединение и Метод K средних.
Проверка статистической значимости
Заметим, что предыдущие рассуждения ссылаются на алгоритмы кластеризации, но ничего не упоминают о проверке статистической значимости. Фактически, кластерный анализ является не столько обычным статистическим методом, сколько "набором" различных алгоритмов "распределения объектов по кластерам". Существует точка зрения, что в отличие от многих других статистических процедур, методы кластерного анализа используются в большинстве случаев тогда, когда вы не имеете каких-либо априорных гипотез относительно классов, но все еще находитесь в описательной стадии исследования. Следует понимать, что кластерный анализ определяет "наиболее возможно значимое решение". Поэтому проверка статистической значимости в действительности здесь неприменима, даже в случаях, когда известны p-уровни (как, например, в методе K средних).
Техника кластеризации применяется в самых разнообразных областях. Хартиган (Hartigan, 1975) дал прекрасный обзор многих опубликованных исследований, содержащих результаты, полученные методами кластерного анализа. Например, в области медицины кластеризация заболеваний, лечения заболеваний или симптомов заболеваний приводит к широко используемым таксономиям. В области психиатрии правильная диагностика кластеров симптомов, таких как паранойя, шизофрения и т.д., является решающей для успешной терапии. В археологии с помощью кластерного анализа исследователи пытаются установить таксономии каменных орудий, похоронных объектов и т.д. Известны широкие применения кластерного анализа в маркетинговых исследованиях. В общем, всякий раз, когда необходимо классифицировать "горы" информации к пригодным для дальнейшей обработки группам, кластерный анализ оказывается весьма полезным и эффективным.
Объединение (древовидная кластеризация)
Общая логика
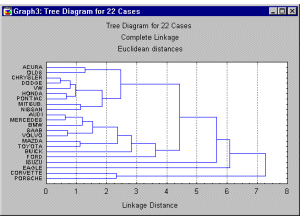
Приведенный в разделе Основная цель пример поясняет цель алгоритма объединения (древовидной кластеризации). Назначение этого алгоритма состоит в объединении объектов (например, животных) в достаточно большие кластеры, используя некоторую меру сходства или расстояние между объектами. Типичным результатом такой кластеризации является иерархическое дерево.
Рассмотрим горизонтальную древовидную диаграмму. Диаграмма начинается с каждого объекта в классе (в левой части диаграммы). Теперь представим себе, что постепенно (очень малыми шагами) вы "ослабляете" ваш критерий о том, какие объекты являются уникальными, а какие нет. Другими словами, вы понижаете порог, относящийся к решению об объединении двух или более объектов в один кластер.
В результате, вы связываете вместе всё большее и большее число объектов и агрегируете (объединяете) все больше и больше кластеров, состоящих из все сильнее различающихся элементов. Окончательно, на последнем шаге все объекты объединяются вместе. На этих диаграммах горизонтальные оси представляют расстояние объединения (в вертикальных древовидных диаграммах вертикальные оси представляют расстояние объединения). Так, для каждого узла в графе (там, где формируется новый кластер) вы можете видеть величину расстояния, для которого соответствующие элементы связываются в новый единственный кластер. Когда данные имеют ясную "структуру" в терминах кластеров объектов, сходных между собой, тогда эта структура, скорее всего, должна быть отражена в иерархическом дереве различными ветвями. В результате успешного анализа методом объединения появляется возможность обнаружить кластеры (ветви) и интерпретировать их.
Объединение или метод древовидной кластеризации используется при формировании кластеров несходства или расстояния между объектами. Эти расстояния могут определяться в одномерном или многомерном пространстве. Например, если вы должны кластеризовать типы еды в кафе, то можете принять во внимание количество содержащихся в ней калорий, цену, субъективную оценку вкуса и т.д. Наиболее прямой путь вычисления расстояний между объектами в многомерном пространстве состоит в вычислении евклидовых расстояний. Если вы имеете двух- или трёхмерное пространство, то эта мера является реальным геометрическим расстоянием между объектами в пространстве (как будто расстояния между объектами измерены рулеткой). Однако алгоритм объединения не "заботится" о том, являются ли "предоставленные" для этого расстояния настоящими или некоторыми другими производными мерами расстояния, что более значимо для исследователя; и задачей исследователей является подобрать правильный метод для специфических применений.
Евклидово расстояние. Это, по-видимому, наиболее общий тип расстояния. Оно попросту является геометрическим расстоянием в многомерном пространстве и вычисляется следующим образом:
расстояние(x,y) = {![]() i (xi - yi)2 }1/2
i (xi - yi)2 }1/2
Заметим, что евклидово расстояние (и его квадрат) вычисляется по исходным, а не по стандартизованным данным. Это обычный способ его вычисления, который имеет определенные преимущества (например, расстояние между двумя объектами не изменяется при введении в анализ нового объекта, который может оказаться выбросом). Тем не менее, на расстояния могут сильно влиять различия между осями, по координатам которых вычисляются эти расстояния. К примеру, если одна из осей измерена в сантиметрах, а вы потом переведете ее в миллиметры (умножая значения на 10), то окончательное евклидово расстояние (или квадрат евклидова расстояния), вычисляемое по координатам, сильно изменится, и, как следствие, результаты кластерного анализа могут сильно отличаться от предыдущих.
Квадрат евклидова расстояния. Иногда может возникнуть желание возвести в квадрат стандартное евклидово расстояние, чтобы придать большие веса более отдаленным друг от друга объектам. Это расстояние вычисляется следующим образом (см. также замечания в предыдущем пункте):
расстояние(x,y) = ![]() i (xi - yi)2
i (xi - yi)2
Расстояние городских кварталов (манхэттенское расстояние). Это расстояние является просто средним разностей по координатам. В большинстве случаев эта мера расстояния приводит к таким же результатам, как и для обычного расстояния Евклида. Однако отметим, что для этой меры влияние отдельных больших разностей (выбросов) уменьшается (так как они не возводятся в квадрат). Манхэттенское расстояние вычисляется по формуле:
расстояние(x,y) = ![]() i |xi - yi|
i |xi - yi|
Расстояние Чебышева. Это расстояние может оказаться полезным, когда желают определить два объекта как "различные", если они различаются по какой-либо одной координате (каким-либо одним измерением). Расстояние Чебышева вычисляется по формуле:
расстояние(x,y) = Максимум|xi - yi|
Степенное расстояние. Иногда желают прогрессивно увеличить или уменьшить вес, относящийся к размерности, для которой соответствующие объекты сильно отличаются. Это может быть достигнуто с использованием степенного расстояния. Степенное расстояние вычисляется по формуле:
расстояние(x,y) = (![]() i |xi - yi|p)1/r
i |xi - yi|p)1/r
где r и p - параметры, определяемые пользователем. Несколько примеров вычислений могут показать, как "работает" эта мера. Параметр p ответственен за постепенное взвешивание разностей по отдельным координатам, параметр r ответственен за прогрессивное взвешивание больших расстояний между объектами. Если оба параметра - r и p, равны двум, то это расстояние совпадает с расстоянием Евклида.
Процент несогласия. Эта мера используется в тех случаях, когда данные являются категориальными. Это расстояние вычисляется по формуле:
расстояние(x,y) = (Количество xi ![]() yi)/ i
yi)/ i
На первом шаге, когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами определяются выбранной мерой. Однако когда связываются вместе несколько объектов, возникает вопрос, как следует определить расстояния между кластерами? Другими словами, необходимо правило объединения или связи для двух кластеров. Здесь имеются различные возможности: например, вы можете связать два кластера вместе, когда любые два объекта в двух кластерах ближе друг к другу, чем соответствующее расстояние связи. Другими словами, вы используете "правило ближайшего соседа" для определения расстояния между кластерами; этот метод называется методом одиночной связи. Это правило строит "волокнистые" кластеры, т.е. кластеры, "сцепленные вместе" только отдельными элементами, случайно оказавшимися ближе остальных друг к другу. Как альтернативу вы можете использовать соседей в кластерах, которые находятся дальше всех остальных пар объектов друг от друга. Этот метод называется метод полной связи. Существует также множество других методов объединения кластеров, подобных тем, что были рассмотрены.
Одиночная связь (метод ближайшего соседа). Как было описано выше, в этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Это правило должно, в известном смысле, нанизывать объекты вместе для формирования кластеров, и результирующие кластеры имеют тенденцию быть представленными длинными "цепочками".
Полная связь (метод наиболее удаленных соседей). В этом методе расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. "наиболее удаленными соседями"). Этот метод обычно работает очень хорошо, когда объекты происходят на самом деле из реально различных "рощ". Если же кластеры имеют в некотором роде удлиненную форму или их естественный тип является "цепочечным", то этот метод непригоден.
Невзвешенное попарное среднее. В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. Метод эффективен, когда объекты в действительности формируют различные "рощи", однако он работает одинаково хорошо и в случаях протяженных ("цепочного" типа) кластеров. Отметим, что в своей книге Снит и Сокэл (Sneath, Sokal, 1973) вводят аббревиатуру UPGMA для ссылки на этот метод, как на метод невзвешенного попарного арифметического среднего - unweighted pair-group method using arithmetic averages.
Взвешенное попарное среднее. Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров (т.е. число объектов, содержащихся в них) используется в качестве весового коэффициента. Поэтому предлагаемый метод должен быть использован (скорее даже, чем предыдущий), когда предполагаются неравные размеры кластеров. В книге Снита и Сокэла (Sneath, Sokal, 1973) вводится аббревиатура WPGMA для ссылки на этот метод, как на метод взвешенного попарного арифметического среднего - weighted pair-group method using arithmetic averages.
Невзвешенный центроидный метод. В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести. Снит и Сокэл (Sneath and Sokal (1973)) используют аббревиатуру UPGMC для ссылки на этот метод, как на метод невзвешенного попарного центроидного усреднения - unweighted pair-group method using the centroid average.
Взвешенный центроидный метод (медиана). тот метод идентичен предыдущему, за исключением того, что при вычислениях используются веса для учёта разницы между размерами кластеров (т.е. числами объектов в них). Поэтому, если имеются (или подозреваются) значительные отличия в размерах кластеров, этот метод оказывается предпочтительнее предыдущего. Снит и Сокэл (Sneath, Sokal 1973) использовали аббревиатуру WPGMC для ссылок на него, как на метод невзвешенного попарного центроидного усреднения - weighted pair-group method using the centroid average.
Метод Варда. Этот метод отличается от всех других методов, поскольку он использует методы дисперсионного анализа для оценки расстояний между кластерами. Метод минимизирует сумму квадратов (SS) для любых двух (гипотетических) кластеров, которые могут быть сформированы на каждом шаге. Подробности можно найти в работе Варда (Ward, 1963). В целом метод представляется очень эффективным, однако он стремится создавать кластеры малого размера.
Для обзора других методов кластеризации, см. Двухвходовое объединение и Метод K средних.
Вводный обзор
Ранее этот метод обсуждался в терминах "объектов", которые должны быть кластеризованы (см. Объединение (древовидная кластеризация)). Во всех других видах анализа интересующий исследователя вопрос обычно выражается в терминах наблюдений или переменных. Оказывается, что кластеризация, как по наблюдениям, так и по переменным может привести к достаточно интересным результатам. Например, представьте, что медицинский исследователь собирает данные о различных характеристиках (переменные) состояний пациентов (наблюдений), страдающих сердечными заболеваниями. Исследователь может захотеть кластеризовать наблюдения (пациентов) для определения кластеров пациентов со сходными симптомами. В то же самое время исследователь может захотеть кластеризовать переменные для определения кластеров переменных, которые связаны со сходным физическим состоянием.
После этого обсуждения, относящегося к тому, кластеризовать наблюдения или переменные, можно задать вопрос, а почему бы не проводить кластеризацию в обоих направлениях? Модуль Кластерный анализ содержит эффективную двувходовую процедуру объединения, позволяющую сделать именно это. Однако двувходовое объединение используется (относительно редко) в обстоятельствах, когда ожидается, что и наблюдения и переменные одновременно вносят вклад в обнаружение осмысленных кластеров.
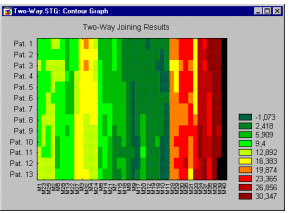
Так, возвращаясь к предыдущему примеру, можно предположить, что медицинскому исследователю требуется выделить кластеры пациентов, сходных по отношению к определенным кластерам характеристик физического состояния. Трудность с интерпретацией полученных результатов возникает вследствие того, что сходства между различными кластерами могут происходить из (или быть причиной) некоторого различия подмножеств переменных. Поэтому получающиеся кластеры являются по своей природе неоднородными. Возможно это кажется вначале немного туманным; в самом деле, в сравнении с другими описанными методами кластерного анализа (см. Объединение (древовидная кластеризация) и Метод K средних), двувходовое объединение является, вероятно, наименее часто используемым методом. Однако некоторые исследователи полагают, что он предлагает мощное средство разведочного анализа данных (за более подробной информацией вы можете обратиться к описанию этого метода у Хартигана (Hartigan, 1975)).
Метод K средних
Общая логика
Этот метод кластеризации существенно отличается от таких агломеративных методов, как Объединение (древовидная кластеризация) и Двувходовое объединение. Предположим, вы уже имеете гипотезы относительно числа кластеров (по наблюдениям или по переменным). Вы можете указать системе образовать ровно три кластера так, чтобы они были настолько различны, насколько это возможно. Это именно тот тип задач, которые решает алгоритм метода K средних. В общем случае метод K средних строит ровно K различных кластеров, расположенных на возможно больших расстояниях друг от друга.
В примере с физическим состоянием (см. Двувходовое объединение), медицинский исследователь может иметь "подозрение" из своего клинического опыта, что его пациенты в основном попадают в три различные категории. Далее он может захотеть узнать, может ли его интуиция быть подтверждена численно, то есть, в самом ли деле кластерный анализ K средних даст три кластера пациентов, как ожидалось? Если это так, то средние различных мер физических параметров для каждого кластера будут давать количественный способ представления гипотез исследователя (например, пациенты в кластере 1 имеют высокий параметр 1, меньший параметр 2 и т.д.).
С вычислительной точки зрения вы можете рассматривать этот метод, как дисперсионный анализ "наоборот". Программа начинает с K случайно выбранных кластеров, а затем изменяет принадлежность объектов к ним, чтобы: (1) - минимизировать изменчивость внутри кластеров, и (2) - максимизировать изменчивость между кластерами. Данный способ аналогичен методу "дисперсионный анализ (ANOVA) наоборот" в том смысле, что критерий значимости в дисперсионном анализе сравнивает межгрупповую изменчивость с внутригрупповой при проверке гипотезы о том, что средние в группах отличаются друг от друга. В кластеризации методом K средних программа перемещает объекты (т.е. наблюдения) из одних групп (кластеров) в другие для того, чтобы получить наиболее значимый результат при проведении дисперсионного анализа (ANOVA).
Обычно, когда результаты кластерного анализа методом K средних получены, можно рассчитать средние для каждого кластера по каждому измерению, чтобы оценить, насколько кластеры различаются друг от друга. В идеале вы должны получить сильно различающиеся средние для большинства, если не для всех измерений, используемых в анализе. Значения F-статистики, полученные для каждого измерения, являются другим индикатором того, насколько хорошо соответствующее измерение дискриминирует кластеры.
1. Электромагнитная волна (в религиозной терминологии релятивизма - "свет") имеет строго постоянную скорость 300 тыс.км/с, абсурдно не отсчитываемую ни от чего. Реально ЭМ-волны имеют разную скорость в веществе (например, ~200 тыс км/с в стекле и ~3 млн. км/с в поверхностных слоях металлов, разную скорость в эфире (см. статью "Температура эфира и красные смещения"), разную скорость для разных частот (см. статью "О скорости ЭМ-волн")
2. В релятивизме "свет" есть мифическое явление само по себе, а не физическая волна, являющаяся волнением определенной физической среды. Релятивистский "свет" - это волнение ничего в ничем. У него нет среды-носителя колебаний.
3. В релятивизме возможны манипуляции со временем (замедление), поэтому там нарушаются основополагающие для любой науки принцип причинности и принцип строгой логичности. В релятивизме при скорости света время останавливается (поэтому в нем абсурдно говорить о частоте фотона). В релятивизме возможны такие насилия над разумом, как утверждение о взаимном превышении возраста близнецов, движущихся с субсветовой скоростью, и прочие издевательства над логикой, присущие любой религии.
4. В гравитационном релятивизме (ОТО) вопреки наблюдаемым фактам утверждается об угловом отклонении ЭМ-волн в пустом пространстве под действием гравитации. Однако астрономам известно, что свет от затменных двойных звезд не подвержен такому отклонению, а те "подтверждающие теорию Эйнштейна факты", которые якобы наблюдались А. Эддингтоном в 1919 году в отношении Солнца, являются фальсификацией. Подробнее читайте в FAQ по эфирной физике.
|
|
