Здесь рассказывается, как писать простейшие XML-документы. Вы узнаете, что XML-документ строится из текстового содержимого, размеченного символьными тегами, такими как <SKU>, <Record_ID> и <author>, которые внешне выглядят как теги HTML. Однако в HTML вы ограничены примерно сотней предопределенных тегов, описывающих форматирование веб-страницы, а в XML можно создавать столько тегов, сколько нужно. Кроме того, эти теги обычно описывают тип содержимого, а не форматирование или информацию о компоновке документа. B XML не указывается, что данная часть документа является абзацем или неупорядоченным списком. Говорится лишь о том, что это книга, биография или календарь.
Хотя XML свободнее HTML в отношении допустимых тегов, он значительно строже в том, что касается расположения этих тегов и того, как они записываются. В частности, все XML-документы должны быть корректными. Правила корректности устанавливают ограничения, такие как «Все открытые теги должны быть закрыты» или «Значения атрибутов должны быть в кавычках». Эти правила не могут быть нарушены, что облегчает анализ XML-документов и несколько усложняет их написание, но тем не менее практически не ограничивает свободу выражения.
XML-документ всегда содержит текст, а не двоичные данные. Его может открыть любая программа, которая читает текстовые файлы. Пример 2-1 - это, пожалуй, простейший XML-документ, который только можно представить. И несмотря на это, он является корректным.
XML-анализаторы могут прочесть и понять его (по крайней мере, если о компьютерной программе вообще можно сказать, что она что-то понимает).
Пример 2-1. Очень простой, при этом полный XML-документ
<pеrson>
Алан Тьюринг
</person>
По самому распространенному сценарию этот документ представляет собой полное содержимое файла с именем person.xml или 2-l.xml. Однако XML не придирчив в отношении имен файлов. С точки зрения анализатора, файл может называться person.txt, person или "Эй ты", в этом файле совсем мало XML. Операционная система может не понимать таких имен, однако для XML-анализатора это не имеет значения. Документ даже не обязан быть файлом. Он может быть записью или полем базы данных. Программа CGI может генерировать его на лету в ответ на запрос браузера. XML-документ может даже храниться в нескольких файлах, хотя это и маловероятно для такого простого документа. Если он обслуживается веб-сервером, то, скорее всего, будет отнесен к MIME-типу application/xml или txt/xml. Однако конкретные XML-приложения могут использовать более конкретные MIME-типы, такие как application/mathml+xml, application/XSLT+xml, ima-ee/svff+xml, text/vnd.wap.wml или text/htm] (в особых случаях).
Документ в примере 2-1 состоит из одного элемента, который имеет тип person. Этот элемент ограничен начальным тегом <person> и конечным тегом </person>. Все, что находится между начальным и конечным тегами, называется содержимым элемента. Содержимым данного элемента является следующая текстовая строка:
Алан Тьюринг
Пробельные символы являются частью содержимого элемента, хотя многие приложения могут их игнорировать. Теги <person> и </person> называются разметкой. Строка Алан Тьюринг и окружающие ее пробельные символы представляют собой символьные данные. Тег - самая распространенная форма разметки в XML-документе, но существуют и другие ее виды, которые мы обсудим ниже.
На первый взгляд, теги XML выглядят так же, как и теги HTML. Начальные теги начинаются с символа <, а конечные теги - с </. И в тех и в других тегах далее следует имя элемента, и заканчиваются они символом >. Однако, в отличие от тегов HTML, по мере надобности можно создавать новые XML-теги. Например, для описания человека можно использовать теги <person> и </person>; для описания календаря - теги <calendar> и </calendar>. Имена тегов отражают тип содержимого внутри элемента, а не то, как это содержимое следует форматировать.
Существует особый синтаксис для пустых элементов - элементов без содержимого. Эти элементы обозначаются тегами, начинающимися с < и заканчивающимися />. Например, в XHTML- основанной на XML версии стандартного HTML - переносы строк и горизонтальные линии обозначаются <br/> и <hr/> вместо <br> и <hr>. Эти элементы в точности эквивалентны <br></br> и <hr></hr>. Решайте сами, какую форму использовать для пустых элементов. Однако то, что нельзя сделать в XML и XHTML (в отличие от HTML), - так это использовать только начальный тег, скажем, <br> или <hr>, без соответствующего конечного тега. Это будет нарушением корректности документа.
XML, в отличие от HTML, чувствителен к регистру. <Person> - это не то же самое, что <PERSON> или <person>. Если открыть тег <person>, то уже нельзя закрыть его тегом </PERS0N>, Используйте либо верхний, либо нижний регистр или тот и другой, как вам угодно. Только будьте последовательны в пределах одного элемента.
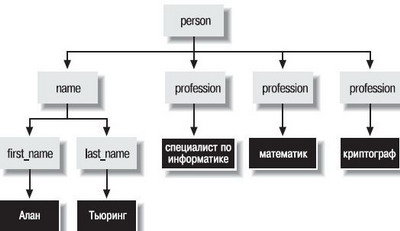
XML-документы имеют древовидную структуру. Чтобы объяснить этот принцип, посмотрим на чуть более сложный XML-документ. Пример 2-2 - это элемент person, содержащий информацию, размеченную в соответствии с ее значением.
Пример 2-2. Более сложный XML-документ, описывающий личность
<person>
<name>
<first_name>Алан</first_name> <last_name>Тьюринг</last_name>
</namе>
<profession> специалист no информатике </profession>
<profession>математик</profession>
<profession>криптограф</profession> </person>
Этот XML-документ все еще состоит из одного элемента person. Однако теперь этот элемент не просто содержит недифференцированные символьные данные. Он включает четыре дочерних элемента: элемент name и три элемента profession. Элемент name содержит два собственных дочерних элемента: first name и last name.
Элемент person называется родительским элементом для элемента name и трех элементов profession. Элемент name является родительским по отношению к элементам first_name и last_name. Элементы name и три элемента profession иногда называются одноуровневыми (sibling) по отношению друг к другу. Элементы first_name и last_name также являются одноуровневыми.
Как и в человеческом обществе, каждый родитель может иметь несколько детей - дочерних элементов. Однако в отличие от нас, в XML у каждого дочернего элемента только один родитель, а не два. Каждый элемент (за единственным исключением, которое мы отметим позже) имеет в точности одного родителя, то есть полностью включается в другой элемент. Если начальный тег элемента находится внутри другого элемента, тогда его конечный тег также должен быть внутри того же элемента. Перекрывающиеся теги, например <strong><em> это распространенный пример из HTML</strong></em>, в XML запрещены. Так как элемент em начинается внутри элемента strong, он должен и заканчиваться также внутри элемента strong.
В каждом XML-документе есть один элемент без родителя. Это первый элемент документа, содержащий все остальные элементы. В примерах 2-1 и 2-2 эту роль выполняет элемент person, и он называется корневым элементом документа, а иногда просто элементом документа. Любой корректный XML-документ имеет лишь один корневой элемент. Так как элементы не могут перекрываться, и все они, кроме корневого, имеют только одного родителя, XML-документ образует структуру, которую программисты называют деревом. На рис. 2.1 приведена схема этих отношений для примера 2-2. Серые прямоугольники изображают элементы. Черные прямоугольники представляют символьные данные. Стрелки обозначают отношения «включения».
Рис 2.1. Диаграмма древовидной структуры для примера 2-2
<biography>
<name><first_name>Алан</first_name> <last_name>Тьюринг<last_name>
</nаmе> был одним из первых, кто действительно заслужил право называться <emphasize>специалистом по информатике</ emphasize >. И хотя его разработки в этой области слишком многочисленны, чтобы их здесь перечислять, самые известные из них - это названные его именем < emphasize >тест Тьюринга</ emphasize > и < emphasize >машина Тьюринга</ emphasize >
<definition><term>тест Тьюринга</ term > на сегодня является стандартом определения действительной разумности компьютера, Этот тест компьютерам еще предстоит пройти,</definition>
<definition><term>машина Тьюринга</ term > - это абстрактный конечный автомат с бесконечной памятью, для которого может быть доказана эквивалентность любому другому конечному автомату со сколь угодно большой памятью, То, что является истиной для машины Тьюринга, является истиной и для всех эквивалентных машин, независимо от их реализации, </definition>
<name><last_name>Тьюринг</last_name></name> был также признанным <profession>математиком</profession> и <profession>криптографом</profession>. Его помощь союзникам в расшифровке кодов немецкой машины «Энигма» сыграла решающее значение. Он покончил жизнь самоубийством <date><day>7</day> <month>июня</month> <year>1954 г.</year></date> </bioqraphy>
Элементы в XML могут иметь атрибуты. Атрибут - это пара имя-значение, присоединяемая к начальному тегу элемента. Имена отделяются от значений знаком равенства и, по желанию, пробельными символами. Значения заключаются в одинарные или двойные кавычки. Например, наш элемент person имеет атрибут born со значением 1912/06/23 и атрибут died со значением 1954/06/07:
<person born="1912/06/23" died=" 1954/06/07">
Алан Тьюринг
</person>
Следующий элемент для XML-анализатора полностью аналогичен предыдущему. В нем лишь используются одинарные кавычки вместо двойных и добавлено несколько дополнительных пробельных символов с обеих сторон знаков равенства:
<person born = "1912/06/23" died = "1954/06/07">
Алан Тьюринг
</person>
Пробельные символы вокруг знака равенства - это исключительно дело вашего вкуса. Одинарные кавычки могут быть полезны в тех случаях, когда значения атрибутов сами содержат двойные кавычки.
В примере 2-4 показано, как можно использовать атрибуты для кодирования почти всей информации, что присутствует в ориентированном на данные документе из примера 2-2.
<реrson>
<name first="Алан" last="Тьюринг"/>
<profession value="специалист по информатике"/>
<profession value ="математик"/>
<profession value="криптограф"/> </person>
Подобный пример поднимает вопрос о том, в каком случае для хранения информации следует использовать дочерние элементы, а когда атрибуты. Это - предмет жарких дебатов. Некоторые специалисты утверждают, что атрибуты предназначены для метаданных об элементе, в то время как элементы - для собственно информации. Другие указывают на то, что не всегда легко определить, где данные, а где метаданные. И в самом деле, ответ зачастую зависит от того, для каких целей будет использоваться информация.
Бесспорно, что каждый элемент может иметь не более одного атрибута с данным именем. Это едва ли будет проблемой для таких атрибутов, как даты рождения или смерти, но может создать сложности для профессии, имени, адреса и всего остального, что может присутствовать в одном элементе более одного раза. Кроме того, атрибуты очень ограничены по своей структуре. Значение атрибута - это лишь текстовая строка. Деление даты на год, месяц и день с помощью косой черты - предел сложности внутренней структуры, доступной для кодирования внутри атрибута. Следовательно, структура, основанная на элементах, является значительно более гибкой и расширяемой. При этом атрибуты, конечно, удобнее для некоторых приложений. В конечном счете, если вы разрабатываете собственный словарь XML, то сами решаете, когда использовать элементы, а когда - атрибуты.
Атрибуты также полезны в повествовательных документах, что показано в примере 2-5. Здесь несколько более ясно, что именно относится к элементам, а что к атрибутам. Сам повествовательный текст располагается в виде символьных данных внутри элементов. Дополнительная информация, которая является примечанием к тексту, представлена атрибутами. Эта информация включает в себя ссылки на источник, URL изображений, гиперссылки, даты смерти и рождения. Но даже здесь это делается разными способами. Например, номера примечаний могут быть атрибутами элемента примечания, а не символьными данными.
Пример 2-5. Повествовательный XML-документ, использующий атрибуты
<biography xmlns:xlink="http://www.w3.org/1999/xlink/namespace/">
<image source="http://www.turing.org.uk/turing/pil/bus.jpg" width="152" height="345"/>
<person born="1912/06/23"
died="1954/06/07"><first_name>Алан</first_name> <last_name>Тьюринг</last_name> </person> был одним из первых, кто действительно заслужил право называться <emphasize>специалистом по информатике</emphasize>. И хотя его разработки в этой области слишком многочисленны, чтобы их здесь перечислять, самые известные из них - это названные его именем <emphasize xlink:type="simple" xlink:href="http://cogsci.ucsd.edu/~asaygin/tt/ttest.html">тест Тьюринга</emphasize> и <emphasize xlink:type="siniple" xlink: href="http://mothworld. wolf ram.com/TuringMachine. html">мaшинa Тьюринга</emphasize>,
<last_name>Tьюpинг</last_name> был также признанным <profession>математиком</profession> и <profession>криптографом</profession>. Его помощь союзникам в расшифровке кодов немецкой машины «Энигма» сыграла решающее значение,<footnote source="The Ultra Secret, F.W. Winterbotham, 1974">1</footnote>
Он покончил жизнь самоубийством <date><day>7</day> <month>июня</ month >
<year>1954
r.</year></date>
<footnote source="Alan Turing: the Enigma, Andrew Hodges, 1983">2</footnote>
</biography>
Когда тот или иной физик использует понятие "физический вакуум", он либо не понимает абсурдности этого термина, либо лукавит, являясь скрытым или явным приверженцем релятивистской идеологии.
Понять абсурдность этого понятия легче всего обратившись к истокам его возникновения. Рождено оно было Полем Дираком в 1930-х, когда стало ясно, что отрицание эфира в чистом виде, как это делал великий математик, но посредственный физик Анри Пуанкаре, уже нельзя. Слишком много фактов противоречит этому.
Для защиты релятивизма Поль Дирак ввел афизическое и алогичное понятие отрицательной энергии, а затем и существование "моря" двух компенсирующих друг друга энергий в вакууме - положительной и отрицательной, а также "моря" компенсирующих друг друга частиц - виртуальных (то есть кажущихся) электронов и позитронов в вакууме.
Однако такая постановка является внутренне противоречивой (виртуальные частицы ненаблюдаемы и их по произволу можно считать в одном случае отсутствующими, а в другом - присутствующими) и противоречащей релятивизму (то есть отрицанию эфира, так как при наличии таких частиц в вакууме релятивизм уже просто невозможен). Подробнее читайте в FAQ по эфирной физике.
|
|
