Процесс проектирования информационных систем является достаточно сложной задачей. Он начинается с построения инфологической модели данных (п. 2), т.е. идентификации сущностей. Затем необходимо выполнить следующие шаги процедуры проектирования даталогической модели.
1. Представить каждый стержень (независимую сущность) таблицей базы данных (базовой таблицей) и специфицировать первичный ключ этой базовой таблицы.
2. Представить каждую ассоциацию (связь вида "многие-ко-многим" или "многие-ко-многим-ко-многим" и т.д. между сущностями) как базовую таблицу. Использовать в этой таблице внешние ключи для идентификации участников ассоциации и специфицировать ограничения, связанные с каждым из этих внешних ключей.
3. Представить каждую характеристику как базовую таблицу с внешним ключом, идентифицирующим сущность, описываемую этой характеристикой. Специфицировать ограничения на внешний ключ этой таблицы и ее первичный ключ – по всей вероятности, комбинации этого внешнего ключа и свойства, которое гарантирует "уникальность в рамках описываемой сущности".
4. Представить каждое обозначение, которое не рассматривалось в предыдущем пункте, как базовую таблицу с внешним ключом, идентифицирующим обозначаемую сущность. Специфицировать связанные с каждым таким внешним ключом ограничения.
5. Представить каждое свойство как поле в базовой таблице, представляющей сущность, которая непосредственно описывается этим свойством.
6. Для того чтобы исключить в проекте непреднамеренные нарушения каких-либо принципов нормализации, выполнить описанную в п. 4.6 процедуру нормализации.
7. Если в процессе нормализации было произведено разделение каких-либо таблиц, то следует модифицировать инфологическую модель базы данных и повторить перечисленные шаги.
8. Указать ограничения целостности проектируемой базы данных и дать (если это необходимо) краткое описание полученных таблиц и их полей.
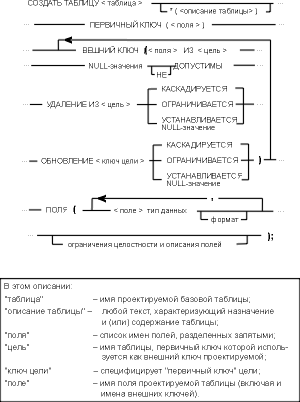
На рис. 4.6 показан синтаксис предложения, предлагаемого для регистрации принимаемых проектных решений.
Для примера приведем описания таблиц "Блюда" и "Состав":
СОЗДАТЬ ТАБЛИЦУ Блюда *( Стержневая сущность )
ПЕРВИЧНЫЙ КЛЮЧ ( БЛ )
ПОЛЯ ( БЛ Целое, Блюдо Текст 60, Вид Текст 7 )
ОГРАНИЧЕНИЯ ( 1. Значения поля Блюдо должны быть
уникальными; при нарушении вывод
сообщения "Такое блюдо уже есть".
2. Значения поля Вид должны принадлежать
набору: Закуска, Суп, Горячее, Десерт,
Напиток; при нарушении вывод сообщения
"Можно лишь Закуска, Суп, Горячее,
Десерт, Напиток");
СОЗДАТЬ ТАБЛИЦУ Состав *( Связывает Блюда и Продукты )
ПЕРВИЧНЫЙ КЛЮЧ ( БЛ, ПР )
ВНЕШНИЙ КЛЮЧ ( БЛ ИЗ Блюда
NULL-значения НЕ ДОПУСТИМЫ
УДАЛЕНИЕ ИЗ Блюда КАСКАДИРУЕТСЯ
ОБНОВЛЕНИЕ Блюда.БЛ КАСКАДИРУЕТСЯ)
ВНЕШНИЙ КЛЮЧ ( ПР ИЗ Продукты
NULL-значения НЕ ДОПУСТИМЫ
УДАЛЕНИЕ ИЗ Продукты ОГРАНИЧИВАЕТСЯ
ОБНОВЛЕНИЕ Продукты.ПР КАСКАДИРУЕТСЯ)
ПОЛЯ ( БЛ Целое, ПР Целое, Вес Целое )
ОГРАНИЧЕНИЯ ( 1. Значения полей БЛ и ПР должны принадлежать
набору значений из соответствующих полей таблиц
Блюда и Продукты; при нарушении вывод сообщения
"Такого блюда нет" или "Такого продукта нет".
2. Значение поля Вес должно лежать в пределах
от 0.1 до 500 г. );
Рассмотренный язык описания данных, основанный на языке SQL [5], позволяет дать удобное и полное описание любой сущности и, следовательно, всей базы данных. Однако такое описание, как и любое подробное описание, не отличается наглядностью. Для достижения большей иллюстративности целесообразно дополнять проект инфологической моделью, но менее громоздкой, чем рассмотренная в главе 2.
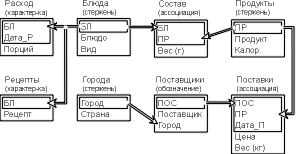
Для наиболее распространенных реляционных баз данных можно предложить язык инфологического моделирования "Таблица-связь", пример использования которого приведен на рис. 4.7. В нем все сущности изображаются одностолбцовыми таблицами с заголовками, состоящими из имени и типа сущности. Строки таблицы – это перечень атрибутов сущности, а те из них, которые составляют первичный ключ, распологаются рядом и обводятся рамкой. Связи между сущностями указываются стрелками, направленными от первичных ключей или их составляющих.
[Назад] [Содержание] [Вперед]
|
|
