Ключевым компонентом любой распределенной системы является файловая система. Как и в централизованных системах, в распределенной системе функцией файловой системы является хранение программ и данных и предоставление доступа к ним по мере необходимости. Файловая система поддерживается одной или более машинами, называемыми файл-серверами. Файл-серверы перехватывают запросы на чтение или запись файлов, поступающие от других машин (не серверов). Эти другие машины называются клиентами. Каждый посланный запрос проверяется и выполняется, а ответ отсылается обратно. Файл-серверы обычно содержат иерархические файловые системы, каждая из которых имеет корневой каталог и каталоги более низких уровней. Рабочая станция может подсоединять и монтировать эти файловые системы к своим локальным файловым системам. При этом монтируемые файловые системы остаются на серверах.
Важно понимать различие между файловым сервисом и файловым сервером. Файловый сервис - это описание функций, которые файловая система предлагает своим пользователям. Это описание включает имеющиеся примитивы, их параметры и функции, которые они выполняют. С точки зрения пользователей файловый сервис определяет то, с чем пользователи могут работать, но ничего не говорит о том, как все это реализовано. В сущности, файловый сервис определяет интерфейс файловой системы с клиентами.
Файловый сервер - это процесс, который выполняется на отдельной машине и помогает реализовывать файловый сервис. В системе может быть один файловый сервер или несколько, но в хорошо организованной распределенной системе пользователи не знают, как реализована файловая система. В частности, они не знают количество файловых серверов, их месторасположение и функции. Они только знают, что если процедура определена в файловом сервисе, то требуемая работа каким-то образом выполняется, и им возвращаются требуемые результаты. Более того, пользователи даже не должны знать, что файловый сервис является распределенным. В идеале он должен выглядеть также, как и в централизованной файловой системе.
Так как обычно файловый сервер - это просто пользовательский процесс (или иногда процесс ядра), выполняющийся на некоторой машине, в системе может быть несколько файловых серверов, каждый из которых предлагает различный файловый сервис. Например, в распределенной системе может быть два сервера, которые обеспечивают файловые сервисы систем UNIX и MS-DOS соответственно, и любой пользовательский процесс пользуется подходящим сервисом.
Файловый сервис в распределенных файловых системах (впрочем как и в централизованных) имеет две функционально различные части: собственно файловый сервис и сервис каталогов. Первый имеет дело с операциями над отдельными файлами, такими, как чтение, запись или добавление, а второй - с созданием каталогов и управлением ими, добавлением и удалением файлов из каталогов и т.п.
Для любого файлового сервиса, независимо от того, централизован он или распределен, самым главным является вопрос, что такое файл? Во многих системах, таких как UNIX и MS DOS, файл - это неинтерпретируемая последовательность байтов. Значение и структура информации в файле является заботой прикладных программ, операционную систему это не интересует.
В ОС мейнфреймов поддерживаются разные типы логической организации файлов, каждый с различными свойствами. Файл может быть организован как последовательность записей, и у операционной системы имеются вызовы, которые позволяют работать на уровне этих записей. Большинство современных распределенных файловых систем поддерживают определение файла как последовательности байтов, а не последовательности записей. Файл характеризуется атрибутами: именем, размером, датой создания, идентификатором владельца, адресом и другими.
Важным аспектом файловой модели является возможность модификации файла после его создания. Обычно файлы могут модифицироваться, но в некоторых распределенных системах единственными операциями с файлами являются СОЗДАТЬ и ПРОЧИТАТЬ. Такие файлы называются неизменяемыми. Для неизменяемых файлов намного легче осуществить кэширование файла и его репликацию (тиражирование), так как исключается все проблемы, связанные с обновлением всех копий файла при его изменении.
Файловый сервис может быть разделен на два типа в зависимости от того, поддерживает ли он модель загрузки-выгрузки или модель удаленного доступа. В модели загрузки-выгрузки пользователю предлагаются средства чтения или записи файла целиком. Эта модель предполагает следующую схему обработки файла: чтение файла с сервера на машину клиента, обработка файла на машине клиента и запись обновленного файла на сервер. Преимуществом этой модели является ее концептуальная простота. Кроме того, передача файла целиком очень эффективна. Главным недостатком этой модели являются высокие требования к дискам клиентов. Кроме того, неэффективно перемещать весь файл, если нужна его маленькая часть.
Другой тип файлового сервиса соответствует модели удаленного доступа, которая предполагает поддержку большого количества операций над файлами: открытие и закрытие файлов, чтение и запись частей файла, позиционирование в файле, проверка и изменение атрибутов файла и так далее. В то время как в модели загрузки-выгрузки файловый сервер обеспечивал только хранение и перемещение файлов, в данном случае вся файловая система выполняется на серверах, а не на клиентских машинах. Преимуществом такого подхода являются низкие требования к дисковому пространству на клиентских машинах, а также исключение необходимости передачи целого файла, когда нужна только его часть.
Природа сервиса каталогов не зависит от типа используемой модели файлового сервиса. В распределенных системах используются те же принципы организации каталогов, что и в централизованных, в том числе многоуровневая организация каталогов.
Принципиальной проблемой, связанной со способами именования файлов, является обеспечение прозрачности. В данном контексте прозрачность понимается в двух слабо различимых смыслах. Первый - прозрачность расположения - означает, что имена не дают возможности определить месторасположение файла. Например, имя /server1/dir1/ dir2/x говорит, что файл x расположен на сервере 1, но не указывает, где расположен этот сервер. Сервер может перемещаться по сети, а полное имя файла при этом не меняется. Следовательно, такая система обладает прозрачностью расположения.
Предположим, что файл x очень большой, а на сервере 1 мало места, предположим далее, что на сервере 2 места много. Система может захотеть переместить автоматически файл x на сервер 2. К сожалению, когда первый компонент всех имен - это имя сервера, система не может переместить файл на другой сервер автоматически, даже если каталоги dir1 и dir2 находятся на обоих серверах. Программы, имеющие встроенные строки имен файлов, не будут правильно работать в этом случае. Система, в которой файлы могут перемещаться без изменения имен, обладает свойством независимости от расположения. Распределенная система, которая включает имена серверов или машин непосредственно в имена файлов, не является независимой от расположения. Система, базирующаяся на удаленном монтировании, также не обладает этим свойством, так как в ней невозможно переместить файл из одной группы файлов в другую и продолжать после этого пользоваться старыми именами. Независимости от расположения трудно достичь, но это желаемое свойство распределенной системы.
Большинство распределенных систем используют какую-либо форму двухуровневого именования: на одном уровне файлы имеют символические имена, такие как prog.c, предназначенные для использования людьми, а на другом - внутренние, двоичные имена, для использования самой системой. Каталоги обеспечивают отображение между двумя этими уровнями имен. Отличием распределенных систем от централизованных является возможность соответствия одному символьному имени нескольких двоичных имен. Обычно это используется для представления оригинального файла и его архивных копий. Имея несколько двоичных имен, можно при недоступности одной из копий файла получить доступ к другой. Этот метод обеспечивает отказоустойчивость за счет избыточности.
Когда два или более пользователей разделяют один файл, необходимо точно определить семантику чтения и записи, чтобы избежать проблем. В централизованных системах, разрешающих разделение файлов, таких как UNIX, обычно определяется, что, когда операция ЧТЕНИЕ следует за операцией ЗАПИСЬ, то читается только что обновленный файл. Аналогично, когда операция чтения следует за двумя операциями записи, то читается файл, измененный последней операцией записи. Тем самым система придерживается абсолютного временного упорядочивания всех операций, и всегда возвращает самое последнее значение. Будем называть эту модель семантикой UNIX'а. В централизованной системе (и даже на мультипроцессоре с разделяемой памятью) ее легко и понять, и реализовать.
Семантика UNIX может быть обеспечена и в распределенных системах, но только, если в ней имеется лишь один файловый сервер, и клиенты не кэшируют файлы. Для этого все операции чтения и записи направляются на файловый сервер, который обрабатывает их строго последовательно. На практике, однако, производительность распределенной системы, в которой все запросы к файлам идут на один сервер, часто становится неудовлетворительной. Эта проблема иногда решается путем разрешения клиентам обрабатывать локальные копии часто используемых файлов в своих личных кэшах. Если клиент сделает локальную копию файла в своем локальном кэше и начнет ее модифицировать, а вскоре после этого другой клиент прочитает этот файл с сервера, то он получит неверную копию файла. Одним из способов устранения этого недостатка является немедленный возврат всех изменений в кэшированном файле на сервер. Такой подход хотя и концептуально прост, но не эффективен.
Другим решением является введение так называемой сессионной семантики, в соответствии с которой изменения в открытом файле сначала виды только процессу, который модифицирует файл, и только после закрытия файла эти изменения могут видеть другие процессы. При использовании сессионной семантики возникает проблема одновременного использования одного и того же файла двумя или более клиентами. Одним из решений этой проблемы является принятие правила, в соответствии с которым окончательным является тот вариант, который был закрыт последним. Менее эффективным, но гораздо более простым в реализации, является вариант, при котором окончательным результирующим файлом на сервере может оказаться любой из этих файлов.
Следующий подход к разделению файлов заключается в том, чтобы сделать все файлы неизменяемыми. Тогда файл нельзя открыть для записи, а можно выполнять только операции СОЗДАТЬ и ЧИТАТЬ. Тогда для изменения файла остается только возможность создать полностью новый файл и поместить его в каталог под именем старого файла. Следовательно, хотя файл и нельзя модифицировать, его можно заменить (автоматически) новым файлом. Другими словами, хотя файлы и нельзя обновлять, но каталоги обновлять можно. Таким образом, проблема, связанная с одновременным использованием файла, просто исчезнет.
Четвертый способ работы с разделяемыми файлами в распределенных системах - это использование механизма неделимых транзакций.
Итак, было рассмотрено четыре различных подхода к работе с разделяемыми файлами в распределенных системах.
Семантика UNIX. Каждая операция над файлом немедленно становится видимой для всех процессов.
Сессионная семантика. Изменения не видны до тех пор, пока файл не закрывается.
Неизменяемые файлы. Модификации невозможны, разделение файлов и репликация упрощаются.
Транзакции. Все изменения делаются по принципу "все или ничего".
Рассмотрим прежде всего вопрос о распределении серверной и клиентской частей между машинами. В некоторых системах (например, NFS) нет разницы между клиентом и сервером, на всех машинах работает одно и то же базовое программное обеспечение, так что любая машина, которая хочет предложить файловый сервис, свободно может это сделать. Для этого ей достаточно экспортировать имена выбранных каталогов, чтобы другие машины могли иметь к ним доступ.
В других системах файловый сервер - это только пользовательская программа, так что система может быть сконфигурирована как клиент, как сервер или как клиент и сервер одновременно. Третьим, крайним случаем, является система, в которой клиенты и серверы - это принципиально различные машины, как в терминах аппаратуры, так и в терминах программного обеспечения. Серверы могут даже работать под управлением другой операционной системы.
Вторым важным вопросом реализации файловой системы является структуризация сервиса файлов и каталогов. Один подход заключается в комбинировании этих двух сервисов на одном сервере. При другом подходе эти сервисы разделяются. В последнем случае при открытии файла требуется обращение к серверу каталогов, который отображает символьное имя в двоичное, а затем обращение к файловому серверу с двоичным именем для действительного чтения или записи файла.
Аргументом в пользу разделения сервисов является тот факт, что они на самом деле слабо связаны, поэтому их раздельная реализация более гибкая. Например, можно реализовать сервер каталогов MS-DOS и сервер каталогов UNIX, которые будут использовать один и тот же файловый сервер для физического хранения файлов. Разделение этих функций также упрощает программное обеспечение. Недостатком является то, что использование двух серверов увеличивает интенсивность сетевого обмена.
Постоянный поиск имен, особенно при использовании нескольких серверов каталогов, может приводить к большим накладным расходам. В некоторых системах делается попытка улучшить производительность за счет кэширования имен. При открытии файла кэш проверяется на наличие в нем нужного имени. Если оно там есть, то этап поиска, выполняемый сервером каталогов, пропускается, и двоичный адрес извлекается из кэша.
Последний рассматриваемый здесь структурный вопрос связан с хранением на серверах информации о состоянии клиентов. Существует две конкурирующие точки зрения.
Первая состоит в том, что сервер не должен хранить такую информацию (сервер stateless). Другими словами, когда клиент посылает запрос на сервер, сервер его выполняет, отсылает ответ, а затем удаляет из своих внутренних таблиц всю информацию о запросе. Между запросами на сервере не хранится никакой текущей информации о состоянии клиента. Другая точка зрения состоит в том, что сервер должен хранить такую информацию (сервер statefull).
Рассмотрим эту проблему на примере файлового сервера, имеющего команды ОТКРЫТЬ, ПРОЧИТАТЬ, ЗАПИСАТЬ и ЗАКРЫТЬ файл. Открывая файлы, statefull-сервер должен запоминать, какие файлы открыл каждый пользователь. Обычно при открытии файла пользователю дается дескриптор файла или другое число, которое используется при последующих вызовах для его идентификации. При поступлении вызова, сервер использует дескриптор файла для определения, какой файл нужен. Таблица, отображающая дескрипторы файлов на сами файлы, является информацией о состоянии клиентов.
Для сервера stateless каждый запрос должен содержать исчерпывающую информацию (полное имя файла, смещение в файле и т.п.), необходимую серверу для выполнения требуемой операции. Очевидно, что эта информация увеличивает длину сообщения.
Однако при отказе statefull-сервера теряются все его таблицы, и после перезагрузки неизвестно, какие файлы открыл каждый пользователь. Последовательные попытки провести операции чтения или записи с открытыми файлами будут безуспешными. Stateless-серверы в этом плане являются более отказоустойчивыми, и это аргумент в их пользу.
Преимущества обоих подходов можно обобщить следующим образом:
Stateless-серверы:
отказоустойчивы;
не нужны вызовы OPEN/CLOSE;
меньше памяти сервера расходуется на таблицы;
нет ограничений на число открытых файлов;
отказ клиента не создает проблем для сервера.
Statefull-серверы:
более короткие сообщения при запросах;
лучше производительность;
возможно опережающее чтение;
легче достичь идемпотентности;
возможна блокировка файлов.
В системах, состоящих из клиентов и серверов, потенциально имеется четыре различных места для хранения файлов и их частей: диск сервера, память сервера, диск клиента (если имеется) и память клиента. Наиболее подходящим местом для хранения всех файлов является диск сервера. Он обычно имеет большую емкость, и файлы становятся доступными всем клиентам. Кроме того, поскольку в этом случае существует только одна копия каждого файла, то не возникает проблемы согласования состояний копий.
Проблемой при использовании диска сервера является производительность. Перед тем, как клиент сможет прочитать файл, файл должен быть переписан с диска сервера в его оперативную память, а затем передан по сети в память клиента. Обе передачи занимают время.
Значительное увеличение производительности может быть достигнуто за счет кэширования файлов в памяти сервера. Требуются алгоритмы для определения, какие файлы или их части следует хранить в кэш-памяти.
При выборе алгоритма должны решаться две задачи. Во-первых, какими единицами оперирует кэш. Этими единицами могут быть или дисковые блоки, или целые файлы. Если это целые файлы, то они могут храниться на диске непрерывными областями (по крайней мере в виде больших участков), при этом уменьшается число обменов между памятью и диском а, следовательно, обеспечивается высокая производительность. Кэширование блоков диска позволяет более эффективно использовать память кэша и дисковое пространство.
Во-вторых, необходимо определить правило замены данных при заполнении кэш-памяти. Здесь можно использовать любой стандартный алгоритм кэширования, например, алгоритм LRU (least recently used), соответствии с которым вытесняется блок, к которому дольше всего не было обращения.
Кэш-память на сервере легко реализуется и совершенно прозрачна для клиента. Так как сервер может синхронизировать работу памяти и диска, с точки зрения клиентов существует только одна копия каждого файла, так что проблема согласования не возникает.
Хотя кэширование на сервере исключает обмен с диском при каждом доступе, все еще остается обмен по сети. Существует только один путь избавиться от обмена по сети - это кэширование на стороне клиента, которое, однако, порождает много сложностей.
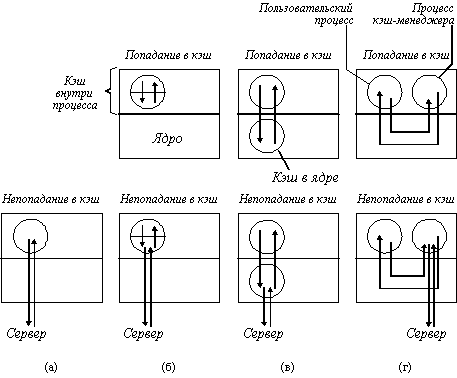
Так как в большинстве систем используется кэширование в памяти клиента, а не на его диске, то мы рассмотрим только этот случай. При проектировании такого варианта имеется три возможности размещения кэша (рисунок 15.1). Самый простой состоит в кэшировании файлов непосредственно внутри адресного пространства каждого пользовательского процесса. Обычно кэш управляется с помощью библиотеки системных вызов. По мере того, как файлы открываются, закрываются, читаются и пишутся, библиотека просто сохраняет наиболее часто используемые файлы. Когда процесс завершается, все модифицированные файлы записываются назад на сервер. Хотя эта схема реализуется с чрезвычайно низкими издержками, она эффективна только тогда, когда отдельные процессы часто повторно открывают и закрывают файлы. Таким является процесс менеджера базы данных, но обычные программы чаще всего читают каждый файл однократно, так что кэширование с помощью библиотеки в этом случае не дает выигрыша.
Рис. 15.1. Различные способы выполнения кэша в клиентской
памяти
а - без кэширования; б - кэширование внутри каждого процесса; в -
кэширование в ядре;
г - кэш-менеджер как пользовательский процесс
Другим местом кэширования является ядро. Недостатком этого варианта является то, что во всех случаях требуется выполнять системные вызовы, даже в случае успешного обращения к кэш-памяти (файл оказался в кэше). Но преимуществом является то, что файлы остаются в кэше и после завершения процессов. Например, предположим, что двухпроходный компилятор выполняется, как два процесса. Первый проход записывает промежуточный файл, который читается вторым проходом. На рисунке 16.1,в показано, что после завершения процесса первого прохода промежуточный файл, вероятно, будет находиться в кэше, так что вызов сервера не потребуется.
Третьим вариантом организации кэша является создание отдельного процесса пользовательского уровня - кэш-менеджера. Преимущество этого подхода заключается в том, что ядро освобождается от кода файловой системы и тем самым реализуются все достоинства микроядер.
С другой стороны, когда ядро управляет кэшем, оно может динамически решить, сколько памяти выделить для программ, а сколько для кэша. Когда же кэш-менеджер пользовательского уровня работает на машине с виртуальной памятью, то понятно, что ядро может решить выгрузить некоторые, или даже все страницы кэша на диск, так что для так называемого "попадания в кэш" требуется подкачка одной или более страниц. Нечего и говорить, что это полностью дискредитирует идею кэширования. Однако, если в системе имеется возможность фиксировать некоторые страницы в памяти, то такая парадоксальная ситуация может быть исключена.
Как и везде, нельзя получить что-либо, не заплатив чем-то за это. Кэширование на стороне клиента вносит в систему проблему несогласованности данных.
Одним из путей решения проблемы согласования является использование алгоритма сквозной записи. Когда кэшируемый элемент (файл или блок) модифицируется, новое значение записывается в кэш и одновременно посылается на сервер. Теперь другой процесс, читающий этот файл, получает самую последнюю версию.
Один из недостатков алгоритма сквозной записи состоит в том, что он уменьшает интенсивность сетевого обмена только при чтении, при записи интенсивность сетевого обмена та же самая, что и без кэширования. Многие разработчики систем находят это неприемлемым и предлагают следующий алгоритм, использующий отложенную запись: вместо того, чтобы выполнять запись на сервер, клиент просто помечает, что файл изменен. Примерно каждые 30 секунд все изменения в файлах собираются вместе и отсылаются на сервер за один прием. Одна большая запись обычно более эффективна, чем много маленьких.
Следующим шагом в этом направлении является принятие сессионной семантики, в соответствии с которой запись файла на сервер производится только после его закрытия. Этот алгоритм называется "запись-по-закрытию". Как мы видели раньше, этот путь приводит к тому, что если две копии одного файла кэшируются на разных машинах и последовательно записываются на сервер, то второй записывается поверх первого. Однако это не так уж плохо, как кажется на первый взгляд. В однопроцессорной системе два процесса могут открыть и читать файл, модифицировать его в своих адресных пространствах, а затем записать его назад. Следовательно, алгоритм "запись-по-закрытию", основанный на сессионной семантике, не намного хуже варианта, уже используемого в однопроцессорной системе.
Совершенно отличный подход к проблеме согласования - это использование алгоритма централизованного управления (этот подход соответствует семантике UNIX). Когда файл открыт, машина, открывшая его, посылает сообщение файловому серверу, чтобы оповестить его об этом факте. Файл-сервер сохраняет информацию о том, кто открыл какой файл, и о том, открыт ли он для чтения, для записи, или для того и другого. Если файл открыт для чтения, то нет никаких препятствий для разрешения другим процессам открыть его для чтения, но открытие его для записи должно быть запрещено. Аналогично, если некоторый процесс открыл файл для записи, то все другие виды доступа должны быть предотвращены. При закрытии файла также необходимо оповестить файл-сервер для того, чтобы он обновил свои таблицы, содержащие данные об открытых файлах. Модифицированный файл также может быть выгружен на сервер в такой момент.
Четыре алгоритма управления кэшированием обобщаются следующим образом:
1. Сквозная запись. Этот метод эффективен частично, так как уменьшает интенсивность только операций чтения, а интенсивность операций записи остается неизменной.
2. Отложенная запись. Производительность лучше, но результат чтения кэшированного файла не всегда однозначен.
3. "Запись-по-закрытию". Удовлетворяет сессионной семантике.
4. Централизованное управление. Ненадежен вследствие своей централизованной природы.
Подводя итоги обсуждения проблемы кэширования, нужно отметить, что кэширование на сервере несложно реализуется и почти всегда дает эффект, независимо от того, реализовано кэширование у клиента или нет. Кэширование на сервере не влияет на семантику файловой системы, видимую клиентом. Кэширование у клиента напротив дает увеличение производительности, но увеличивает и сложность семантики.
Распределенные системы часто обеспечивают репликацию (тиражирование) файлов в качестве одной из услуг, предоставляемых клиентам. Репликация - это асинхронный перенос изменений данных исходной файловой системы в файловые системы, принадлежащие различным узлам распределенной файловой системы. Другими словами, система оперирует несколькими копиями файлов, причем каждая копия находится на отдельном файловом сервере. Имеется несколько причин для предоставления этого сервиса, главными из которых являются:
1. Увеличение надежности за счет наличия независимых копий каждого файла на разных файл-серверах.
2. Распределение нагрузки между несколькими серверами.
Как обычно, ключевым вопросом, связанным с репликацией является прозрачность. До какой степени пользователи должны быть в курсе того, что некоторые файлы реплицируются? Должны ли они играть какую-либо роль в процессе репликации или репликация должна выполняться полностью автоматически? В одних системах пользователи полностью вовлечены в этот процесс, в других система все делает без их ведома. В последнем случае говорят, что система репликационно прозрачна.
На рисунке 15.2 показаны три возможных способа репликации. При использовании первого способа (а) программист сам управляет всем процессом репликации. Когда процесс создает файл, он делает это на одном определенном сервере. Затем, если пожелает, он может сделать дополнительные копии на других серверах. Если сервер каталогов разрешает сделать несколько копий файла, то сетевые адреса всех копий могут быть ассоциированы с именем файла, как показано на рисунке снизу, и когда имя найдено, это означает, что найдены все копии. Чтобы сделать концепцию репликации более понятной, рассмотрим, как может быть реализована репликация в системах, основанных на удаленном монтировании, типа UNIX. Предположим, что рабочий каталог программиста имеет имя /machine1/usr/ast. После создания файла, например, /machine1/usr/ast/xyz, программист, процесс или библиотека могут использовать команду копирования для того, чтобы сделать копии /machine2/usr/ast/xyz и machine3/usr/ast/xyz. Возможно программа использует в качестве аргумента строку /usr/ast/xyz и последовательно попытается открывать копии, пока не достигнет успеха. Эта схема хотя и работает, но имеет много недостатков, и по этим причинам ее не стоит использовать в распределенных системах.
На рисунке 15.2,б показан альтернативный подход - ленивая репликация. Здесь создается только одна копия каждого файла на некотором сервере. Позже сервер сам автоматически выполнит репликации на другие серверы без участия программиста. Эта система должна быть достаточно быстрой для того, чтобы обновлять все эти копии, если потребуется.
Последним рассмотрим метод, использующий групповые связи (рисунок 16.2,в). В этом методе все системные вызовы ЗАПИСАТЬ передаются одновременно на все серверы, таким образом копии создаются одновременно с созданием оригинала. Имеется два принципиальных различия в использовании групповых связей и ленивой репликации. Во-первых, при ленивой репликации адресуется один сервер, а не группа. Во-вторых, ленивая репликация происходит в фоновом режиме, когда сервер имеет промежуток свободного времени, а при групповой репликации все копии создаются в одно и то же время.
Рассмотрим, как могут быть изменены существующие реплицированные файлы. Существует два хорошо известных алгоритма решения этой проблемы.
Первый алгоритм, называемый "репликация первой копии", требует, чтобы один сервер был выделен как первичный. Остальные серверы являются вторичными. Когда реплицированный файл модифицируется, изменение посылается на первичный сервер, который выполняет изменения локально, а затем посылает изменения на вторичные серверы.

Рис. 15.2. а) Точная репликация файла; б) Ленивая репликация
файла;
в) Репликация файла, использующая группу
Чтобы предотвратить ситуацию, когда из-за отказа первичный сервер не успевает оповестить об изменениях все вторичные серверы, изменения должны быть сохранены в постоянном запоминающем устройстве еще до изменения первичной копии. В этом случае после перезагрузки сервера есть возможность сделать проверку, не проводились ли какие-нибудь обновления в момент краха. Недостаток этого алгоритма типичен для централизованных систем - пониженная надежность. Чтобы избежать его, используется метод, предложенный Гиффордом и известный как "голосование". Пусть имеется n копий, тогда изменения должны быть внесены в любые W копий. При этом серверы, на которых хранятся копии, должны отслеживать порядковые номера их версий. В случае, когда какой-либо сервер выполняет операцию чтения, он обращается с запросом к любым R серверам. Если R+W > n, то, хотя бы один сервер содержит последнюю версию, которую можно определить по максимальному номеру.
Интересной модификацией этого алгоритма является алгоритм "голосования с приведениями". В большинстве приложений операции чтения встречаются гораздо чаще, чем операции записи, поэтому R обычно делают небольшим, а W - близким к N. При этом выход из строя нескольких серверов приводит к отсутствию кворума для записи. Голосование с приведениями решает эту проблему путем создания фиктивного сервера без дисков для каждого отказавшего или отключенного сервера. Фиктивный сервер не участвует в кворуме чтения (прежде всего, у него нет файлов), но он может присоединиться к кворуму записи, причем он просто записывает в никуда передаваемый ему файл. Запись только тогда успешна, когда хотя бы один сервер настоящий.
Когда отказавший сервер перезапускается, то он должен получить кворум чтения для обнаружения последней версии, которую он копирует к себе перед тем, как начать обычные операции. В остальном этот алгоритм подобен основному.
Одной из самых известных сетевых файловых систем является Network File System (NFS) фирмы Sun Microsystems. NFS была первоначально создана для UNIX-компьютеров. Сейчас она поддерживает как UNIX, так и другие ОС, включая MS DOS. NFS поддерживает неоднородные системы, например, MS-DOS-клиенты и UNIX-серверы.
Основная идея NFS - позволить произвольному набору пользователей разделять общую файловую систему. Чаще всего все пользователи принадлежат одной локальной сети, но не обязательно. Можно выполнять NFS и на глобальной сети. Каждый NFS-сервер предоставляет один или более своих каталогов для доступа удаленным клиентам. Каталог объявляется доступным со всеми своими подкаталогами. Список каталогов, которые сервер передает, содержится в файле /etc/exports, так что эти каталоги экспортируются сразу автоматически при загрузке сервера. Клиенты получают доступ к экспортируемым каталогам путем монтирования. Многие рабочие станции Sun - бездисковые, но и в этом случае можно монтировать удаленную файловую систему на корневой каталог, при этом вся файловая система целиком располагается на сервере. При выполнении программ почти нет различий, расположен ли файл локально или на удаленном диске. Если два или более клиента одновременно смонтировали один и тот же каталог, то они могут связываться путем разделения файла.
Так как одной из целей NFS является поддержка неоднородных систем с клиентами и серверами, выполняющими различные ОС на различной аппаратуре, то особенно важно, чтобы был хорошо определен интерфейс между клиентами и серверами. Только в этом случае станет возможным написание программного обеспечения клиентской части для новых операционных систем рабочих станций, которое будет правильно работать с существующими серверами. Это цель достигается двумя протоколами.
Первый NFS-протокол управляет монтированием. Клиент может послать полное имя каталога серверу и запросить разрешение на монтирование этого каталога на какое-либо место собственного дерева каталогов. При этом серверу не указывается, в какое место будет монтироваться каталог сервера, так как ему это безразлично. Получив имя, сервер проверяет законность этого запроса и возвращает клиенту описатель файла, содержащий тип файловой системы, диск, номер дескриптора (inode) каталога, информацию безопасности. Операции чтения и записи файлов из монтируемых файловых систем используют этот описатель файла. Монтирование может выполняться автоматически с помощью командных файлов при загрузке. Существует другой вариант автоматического монтирования: при загрузке ОС на рабочей станции удаленная файловая система не монтируется, но при первом открытии удаленного файла ОС посылает запросы каждому серверу, и, после обнаружения этого файла, монтирует каталог того сервера, на котором этот файл расположен.
Второй NFS-протокол используется для доступа к удаленным файлам и каталогам. Клиенты могут послать запрос серверу для выполнения какого-либо действия над каталогом или операции чтения или записи файла. Кроме того, они могут запросить атрибуты файла, такие как тип, размер, время создания и модификации. Большая часть системных вызовов UNIX поддерживается NFS, за исключением open и close. Исключение open и close не случайно. Вместо операции открытия удаленного файла клиент посылает серверу сообщение, содержащее имя файла, с запросом отыскать его (lookup) и вернуть описатель файла. В отличие от вызова open, вызов lookup не копирует никакую информацию во внутренние системные таблицы сервера. Вызов read содержит описатель того файла, который нужно читать, смещение в уже читаемом файле и количество байтов, которые нужно прочитать. Преимуществом такой схемы является то, что сервер не должен запоминать ничего об открытых файлах. Таким образом, если сервер откажет, а затем будет восстановлен, информация об открытых файлах не потеряется, потому что ее нет. Серверы, подобные этому, не хранящие постоянную информацию об открытых файлах, называются stateless.
В противоположность этому в UNIX System V в удаленной файловой системе RFS требуется, чтобы файл был открыт, прежде чем его можно будет прочитать или записать. После этого сервер создает таблицу, сохраняющую информацию о том, что файл открыт, и о текущем читателе. Недостаток этого подхода состоит в том, что когда сервер отказывает, после его перезапуска все его открытые связи теряются, и программы пользователей портятся. В NFS такого недостатка нет.
К сожалению метод NFS затрудняет блокировку файлов. В UNIX файл может быть открыт и заблокирован так, что другие процессы не имеют к нему доступа. Когда файл закрывается, блокировка снимается. В stateless-системах, подобных NFS, блокирование не может быть связано с открытием файла, так как сервер не знает, какой файл открыт. Следовательно, NFS требует специальных дополнительных средств управления блокированием.
Реализация кодов клиента и сервера в NFS имеет многоуровневую структуру (рисунок 5.10).
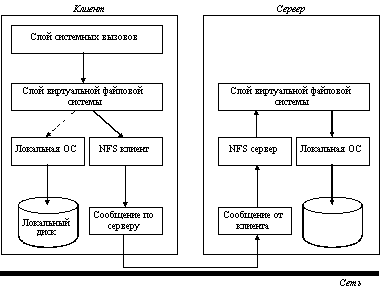
Рис. 5.10. Многоуровневая структура NFS
Верхний уровень клиента - уровень системных вызовов, таких как OPEN, READ, CLOSE. После грамматического разбора вызова и проверки параметров, этот уровень обращается ко второму уровню - уровню виртуальной файловой системы (VFS). В структуре vnode имеется информация о том, является ли файл удаленным или локальным. Чтобы понять, как используются vnode, рассмотрим последовательность выполнения системных вызовов MOUNT, READ, OPEN. Чтобы смонтировать удаленную файловую систему, системный администратор вызывает программу монтирования, указывая удаленный каталог, локальный каталог, на который должен монтироваться удаленный каталог, и другую информацию. Программа монтирования выполняет грамматический разбор имени удаленного каталога и определяет имя машины, где находится удаленный каталог. Если каталог существует и является доступным для удаленного монтирования, то сервер возвращает описатель каталога программе монтирования, которая путем выполнения системного вызова MOUNT передает этот описатель в ядро.
Затем ядро создает vnode для удаленного каталога и обращается с запросом к клиент-программе для создания rnode (удаленного inode) в ее внутренних таблицах. Каждый vnode указывает либо на какой-нибудь rnode в NFS клиент-коде, либо на inode в локальной ОС.
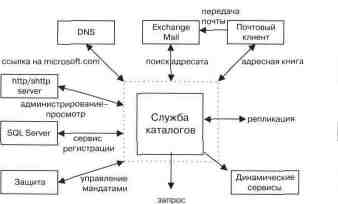
Согласно словарю Ожегова, каталог — это составленный в определенном порядке перечень каких-либо однородных предметов (книг, экспонатов, товаров)'. Точно так же, как каталог выставки содержит информацию об экспонатах, каталог файловой системы предоставляет информацию о файлах. Отличительная особенность такого каталога — возможность систематизации хранимой информации, быстрого поиска нужной, а также добавления и расширения самого каталога. Служба каталогов операционной системы хранит информацию об объектах системы и позволяет манипулировать ими.
Служба каталогов Active Directory (AD) — сервис, интегрированный с Windows NT Server. Она обеспечивает иерархический вид сети, наращиваемость и расширяемость, а также функции распределенной безопасности. Эта служба легко интегрируется с Интернетом, позволяет использовать простые и интуитивно понятные имена объектов, пригодна для использования в организациях любого размера и легко масштабируется. Доступ к ней возможен с помощью таких знакомых инструментов, как программа просмотра ресурсов Интернета.
AD не только позволяет выполнять различные административные задачи, но и является поставщиком различных услуг в системе. На приведенном ниже рисунке схематично изображены основные функции службы каталогов.
В Active Directory концепция пространства имен Интернета объединена с системными службами каталогов, что дает возможность единым образом управлять различными пространствами имен в гетерогенных средах корпоративных сетей. В качестве основного в AD используется легкий протокол доступа к каталогу LDAP (lightweight directory access protocol), позволяющий действовать за рамками операционной системы, объединяя различные пространства имен. Active Directory может включать в себя каталоги других приложений или сетевых операционных систем, а также управлять ими, что значительно снижает нагрузку на администраторов и накладные расходы.
Каталог — поставщик услуг в системе
Active Directory не является каталогом Х.500, как иногда считают. Она использует лишь информационную модель Х.500 (без избыточности, присущей последнему), а в качестве протокола доступа — LDAP. В результате достигается так необходимая в гетерогенных системах высокая степень взаимодействия.
LDAP — стандартный протокол доступа к каталогам (RFC1777) — был разработан как альтернатива протоколу доступа Х.500. В Active Directory поддерживаются как LDAP v2, так и LDAP v3.
HTTP — стандартный протокол для отображения страниц Web. Active Directory дает возможность просмотреть любой объект в виде страницы Web. Расширения Internet Information Server, поставляемые совместно со службой каталога, преобразуют запросы к объектам каталога в страницы HTML.
Active Directory позволяет централизовано администрировать все ресурсы, любые произвольные объекты и сервисы: файлы, периферийные устройства, базы данных, подключения к Web, учетные записи и др. В качестве поискового сервиса используется DNS. Все объекты внутри домена объединяются в организационные единицы (OU), составляющие иерархичные структуры. В свою очередь, домены могут объединяться в деревья.
Давайте, прежде чем перейти к устройствам и особенностям службы каталогов Active Directory, остановимся на некоторых базовых терминах и концепциях. Возможно, какие-то из них покажутся Вам знакомыми.
Сфера влияния. Сфера влияния службы каталогов велика: любые объекты (пользователи, файлы, принтеры и др.), серверы в сети, домены и даже глобальные сети. А раз так, напрашивается вывод: возможности такой службы каталогов, как AD, практически безграничны, что делает ее полезной на отдельном компьютере, в большой сети, и в нескольких сетях.
Пространство имен. Как и любой каталог, Active Directory представляет собой некоторое пространство имен, то есть некоторую область, в которой данное имя может быть разрешено. Под разрешением имен понимается процесс, позволяющий сопоставить имя с объектом, ему соответствующим, или с информацией о таком объекте. К примеру, в файловой системе имя файла разрешается в расположение файла на диске.
Объект. Под объектом
подразумевается отдельный набор атрибутов, соответствующих чему-либо
конкретному: например, пользователю, компьютеру или приложению. В атрибутах
содержатся данные о субъекте, представленном данным объектом. Например, атрибуты
пользователя могут включать его имя, фамилию, адреса домашний и
электронной
почты, семейное положение, заработную плату и т. д.
Контейнер. Контейнер — это объект каталога, который может содержать в себе другие объекты (как, например, папка —это контейнер для документов, а шкаф — контейнер для папок). Контейнер каталога является контейнером объектов каталога.
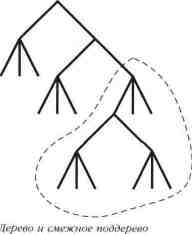
Дерево. Деревом называется иерархическая структура из объектов. Объекты, располагающиеся на ветвях этого дерева, называются листьями. В листьях не содержится других объектов, то есть листья не могут быть контейнерами. Контейнерами являются узловые точки дерева (места, из которых выходят ветви). Неразрывная часть дерева, включающая всех членов контейнера, называется смежным поддеревом. На рисунке внешний вид дерева показывает взаимосвязи между объектами.
Имя. Имена используются для идентификации объектов в Active Directory. Существует два вида имен: отличительное имя DN (distinguished name) и относительно отличительное имя RDN (relatively distinguished name).
Отличительное имя объекта содержит имя домена, в котором находится объект, а также полный путь к этому объекту в иерархии контейнера. Например, отличительное имя для идентификации пользователя Fyodor Zubanov в домене MicrosoftAO.RU будет выглядеть следующим образом:
/0=Internet/DC=RU/DC=MiсrosoftAO/CN=Users/CN=Fyodor Zubanov
Относительное отличительное имя объекта — часть отличительного имени, являющаяся атрибутом объекта. В приведенном примере таковым для объекта пользователя Fyodor Zubanov является
CN=Fyodor Zubanov, a RDN его родительского объекта — CN=Users.
Контексты имен и разделы. Active Directory состоит из
одного или нескольких контекстов имен или разделов. Контекст имени — это
любое смежное поддерево каталога.
Контексты имен являются единицами
тиражирования. Для любого одиночного сервера всегда есть три контекста имен:
— схема;
— конфигурация (топология тиражирования и относящиеся к нему метаданные);
—один или несколько контекстов имен пользователей (поддеревья, содержащие действительные объекты каталога).
Домены. Домены, как указывалось выше, являются
организационными единицами безопасности в сети. Active Directory состоит из
одного или нескольких доменов. Рабочая станция является доменом. Домен может
охватывать несколько физических точек. В каждом домене — своя политика
безопасности; отношения домена с другими также индивидуальны.
Домены,
объединенные общей схемой, конфигурацией и глобальным каталогом, образуют дерево
доменов. Несколько доменных деревьев могут быть объединены в лес.
Дерево доменов. Дерево доменов состоит из нескольких доменов, использующих одну и ту же схему и конфигурацию, и образующих единое пространство имен. Домены в дереве связаны между собой доверительными отношениями. Служба Каталогов Active Directory состоит из одного или нескольких доменных деревьев.
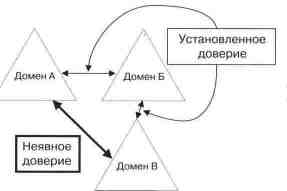
Доверительные отношения Kerberos
Деревья можно рассматривать и с точки зрения доверительных отношений, и с точки зрения пространства имен. В Windows NT 5.0 доверительные отношения между доменами основываются на протоколе защиты Kerberos. Эти отношения транзитивны, то есть если домен А доверяет домену Б, а домен Б доверяет домену В, то домен А также доверяет домену В. На рисунке изображены домены с точки зрения доверия.
С другой стороны, домены можно рассматривать с точки зрения отличительных имен. При этом четко прослеживается иерархическая структура доменов и становится проще поиск по всему дереву.
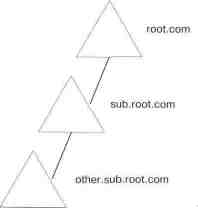
Взгляд на домены с точки зрения пространства имен
Строго говоря, в Active Directory нет ограничений на формирование пространства смежных имен из несмежных доменов и каталогов. И все же лучше, чтобы пространство имен было организовано по той же логике, что и структура.
Лес. Лес — это набор несмежных деревьев, не образующих единое пространство имен. В то же время все деревья в лесу используют одну и ту же схему, конфигурацию и глобальный каталог и связаны между собой Kerberos — отношениями доверия. В отличие от деревьев, у леса нет определенного имени. Он существует в виде поперечных ссылок и иерархических доверительных отношений, известных деревьям, его образующим. Для обращения к лесу используется имя дерева в корне доверяющего дерева.
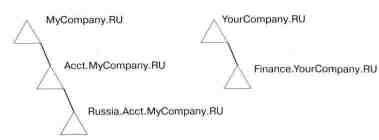
Несколько деревьев в лесу
Узлы. Узел — это место расположения в сети серверов с Active Directory, В качестве узлов могут выступать одна или несколько подсетей TCP/IP, что позволяет конфигурировать доступ к каталогу и тиражирование с учетом физической сети. Когда пользователь входит в сеть, сервер с Active Directory не надо долго искать — ведь он находится в том же самом узле и рабочей станции «известно», как добраться до него по TCP/IP.
Схема. Схема Active Directory представляет собой набор экземпляров классов объектов, хранящихся в каталоге. Это отличает ее от схем других каталогов, которые, как правило, хранятся в текстовых файлах и прочитываются при загрузке. Хранение схемы в каталоге имеет ряд преимуществ. Например, приложения могут обращаться к каталогу и читать списки доступных объектов, а также динамически изменять схему, добавляя в нее новые атрибуты и классы. Модификация схемы сопровождается созданием или модификацией объектов, хранящихся в каталоге. Все внесенные изменения незамедлительно становятся доступны для других приложений. Любые объекты схемы (впрочем, как и любые объекты Active Directory) защищены списками контроля доступа, что гарантирует их от изменений лицами, не имеющими на это прав.
В основу модели данных службы каталогов Active Directory положена модель данных Х.500. В каталоге хранятся различные объекты, описанные атрибутами. Классы объектов, которые допустимо хранить в каталоге, задаются схемой. Для каждого класса объектов в схеме определены обязательные и возможные дополнительные атрибуты экземпляров класса, а также то, класс какого объекта может быть родительским по отношению к рассматриваемому.
Active Directory может состоять из нескольких разделов или контекстов имен. В отличительном имени объекта содержится информация, достаточная для успешного поиска копии раздела, содержащего объект. Однако часто пользователю или приложению неизвестно ни отличительное имя объекта, ни раздел, где он может находиться. Глобальный каталог позволяет пользователям и приложениям определять положение объектов в дереве доменов Active Directory по одному или нескольким атрибутам.
В глобальном каталоге содержится частичная копия каждого из контекстов пользовательских имен, а также схема и конфигурационные контексты имен. Это означает, что в глобальном каталоге хранятся копии всех объектов Active Directory, но с сокращенным набором атрибутов. К хранимым относятся атрибуты наиболее часто используемые при поиске (например имя пользователя, имя входа в систему и т. п.) и достаточные для обнаружения полной реплики объекта. Глобальный каталог позволяет быстро находить нужные объекты, не требуя указаний, в каком домене находится объект, а также использования смежного расширенного пространства имен.
Теперь, ознакомившись с базовыми терминами и концепциями, попытаемся составить из них единую четкую картину — поговорим об устройстве Active Directory подробно.
Основная структурная единица Active Directory — дерево доменов, связанных доверительными отношениями друг с другом. Внутри каждого домена может располагаться иерархия организационных единиц (OU). Иерархия OU внутри одного домена никак не связана с иерархией OU в других доменах. Наоборот, они полностью независимы.
Такая двухъярусная иерархичная структура предоставляет высокую степень свободы в администрировании деревьев доменов. Например, всем деревом доменов целиком может управлять центральная служба информационных технологий (ИТ), а во всех доменах будут созданы свои собственные организационные единицы, где учтены как работники, ответственные за локальную поддержку на местах, так и ресурсы, обеспечивающие эту поддержку.
В каждом отдельном домене могут быть созданы дополнительные OU для выполнения конкретных задач. Так в домене головного офиса — OU отдела кадров и бухгалтерии, в филиалах — OU торговых представительств. При этом административные права для каждой из этих OU могут делегироваться центральной службой ИТ сотрудникам упомянутых групп. Последние же, будучи наделены административными полномочиями только в рамках своих OU, никак не смогут помешать службе ИТ выполнять глобальное администрирование или вмешаться в деятельность другой OU.
Такая гибкость позволяет организовать каталог в точном соответствии со структурой Вашего предприятия. Причем, возможно отразить как централизованную, так и децентрализованную, а также некоторую смешанную модель управления предприятием. Например, дерево доменов может быть организовано по централизованной модели, а OU внутри доменов — по децентрализованной.
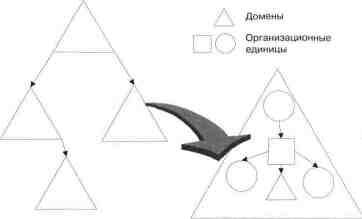
Архитектура Active Directory
Как уже упоминалось, внутри каждого домена — своя политика безопасности (подробнее об этом — в главе 2). Этой политикой определяются, в частности, требования к паролям, время жизни билетов Кегberos, блокировки учетных записей и т. д. При создании учетной записи в домене для нее генерируется идентификатор безопасности (SID), частью которого является идентификатор домена, выдавшего SID. Это позволяет легко определять, какому домену принадлежит пользователь или группа и каковы их права доступа к ресурсам. Таким образом, можно говорить о физических границах безопасности домена, в рамках которых и выполняется его администрирование.
Организационные единицы являются контейнерами, в которых могут содержаться другие организационные единицы или объекты (пользователи, группы, принтеры или ресурсы распределенной файловой системы). Разрешение создавать объекты или изменять их атрибуты может быть выдано отдельным пользователям или группам, что позволяет более четко разделять административные полномочия.
Определение схемы, данное при первом ознакомлении с этим термином, несколько расплывчато и, возможно, не дает общего понимания ее назначения. В схеме задано, какие объекты и с какими свойствами допустимы в каталоге. Во время установки Active Directory на первый контроллер доменов в лесу, служба каталогов по умолчанию создает схему, где содержатся все объекты и заданы свойства, необходимые для нормального функционирования службы каталогов. Предусматривается также тиражирование каталога на все контроллеры домена, которые будут включены в лес позднее.
Каталог содержит необходимую информацию о пользователях и объектах данной организации. Такие свойства Active Directory, как отказоустойчивость и расширяемость, позволяют использовать этот сервис в различных приложениях, например, по учету кадров. Стандартно в Active Directory уже определены такие атрибуты пользователя, как его имя, фамилия, номера телефонов, название офиса, домашний адрес. Но если понадобятся такие сведения, как зарплата сотрудника, его трудовой стаж, медицинская страховка, сведения о поощрениях и т. п,, то эти параметры можно задать дополнительно. Active Directory позволяет «наращивать» схему, добавлять в нее новые свойства и классы на основе существующих и с наследованием их свойств.
Также можно задавать новые свойства, в том числе и существующим классам. При этом все свойства можно разделить на обязательные и возможные. Все обязательные свойства необходимо указывать при создании объекта. Например объект «пользователь» обязательно должен иметь общее имя en (common name), пароль и SamAccountName (имя, используемое для обратной совместимости с предыдущими версиями).
Возможные свойства можно и не указывать. Они лишь выполняют вспомогательные функции и могут быть полезны, например, для администраторов или для других пользователей. Проиллюстрируем сказанное на примере приложения по учету кадров. Всех сотрудников предприятия можно условно разделить на две группы: постоянные и временные. Для постоянных сотрудников целесообразно создать новый класс FullTimeEmp. В качестве возможных свойств этого класса можно добавить в схему зарплату и семейное положение. При этом права на чтение и изменение этих свойств будут иметь только сотрудники отдела кадров, а на чтение — лишь сам сотрудник. Администраторы сети также не имеют прав доступа к этим сведениям.
Понятно, что такая свобода модификации и наращивания каталога должна опираться на мощные механизмы хранения и поиска информации. В Active Directory таким механизмом хранения служит ESE (Extensible Storage Engine) — улучшенная версия Jet-базы данных, использующейся в Microsoft Exchange версий 4 и 5.х2. В новой базе может содержаться до 17 терабайт данных, до 10 миллионов объектов.
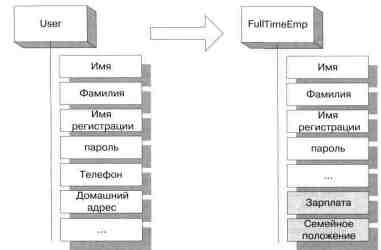
Пример модификации схемы
Еще одна особенность ESE — там хранятся только реально используемые значения свойств. Например, для объекта user определено по умолчанию порядка 50 свойств. Но если Вы описали только 4 (имя, фамилию, общее имя и пароль), то место для хранения будет отведено только для этих атрибутов. По мере описания других атрибутов место для них будет выделяться динамически.
ESE позволяет хранить свойства, имеющие несколько значений, например, несколько телефонных номеров одного пользователя. При этом совсем не надо создавать атрибуты каждого телефонного номера.
Подробнее о классах и атрибутах схемы, а также о том, как вносить в нее изменения, мы поговорим в одном из следующих разделов этой главы.
Одна из задач службы каталогов Active Directory — обеспечить однотипный взгляд на сети независимо от того, сколько и каких пространств имен и каталогов в них используется. Вы можете включать в AD, а затем организовывать каталоги, независимо от их расположения и использующих их операционных систем.
Другая важная особенность Active Directory — избыточная поддержка нескольких стандартных систем именований. В качестве собственной системы имен в AD применяется DNS (Domain Name System); в то же время она может использовать LDAP или HTTP для обмена информацией с приложениями или иными каталогами.
В Active Directory объединены лучшие возможности Х.500 и сервиса обнаружения DNS . DNS — сервис, наиболее часто используемый как в Интернете, так и в интрасетях. Он с успехом применяется для преобразования имени в IP-адрес как в масштабах Интернета, так и в небольших сетях.
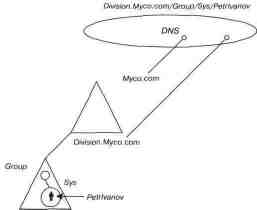
DNS как поисковая служба Windows NT
Active Directory использует DNS в качестве своего поискового сервиса. Имя домена в AD — не что иное,-как полностью определенное имя DNS. Например, fyodor.ru может быть как доменом DNS, так и доменом Windows NT. (Вспомните, что в предыдущих версиях Windows NT имя домена было NetBIOS-именем.) Указывая имя FyodorZ@microsoft.com, можно в равной степени рассматривать его и как почтовый адрес в Интернете, и как имя пользователя в домене Windows NT. На рисунке видно, что домены Windows NT могут размещаться в Интернете или интрасетях так же, как и любые иные ресурсы — посредством DNS.
Традиционно DNS был присущ один недостаток — статичность базы, что вело к необходимости обновлять данные и тиражировать изменения на другие серверы DNS вручную. В Windows NT 4.0 было реализовано решение, объединяющее сервис DNS с сервисом WINS и позволявшее динамически обновлять базу имен. Кроме того, в состав операционной системы был включен графический инструмент для администрирования DNS, что позволяло легко освоить эту «науку» даже неискушенным пользователям.
«Сладкая парочка» DNS+WINS работала следующим образом. При поступлении от DNS-клиента запроса на разрешение имени (например, mydesktop.mycorp.ru) разрешение имени хоста выполнялось на сервере WINS, к которому обращался сервер DNS, и которому возвращался разрешенный IP-адрес. Такая конфигурация делала возможным использование DHCP (Dynamic Host Configuration Protocol) для динамического назначения адресов. Хотя интеграция DNS с WINS и была временным решением, она хоть немного скрасила жизнь администраторам до принятия стандарта на динамический DNS3.
В динамическом сервере DNS обновлением и тиражированием базы занимается непосредственно сервер. Серверы, на которых установлена служба каталогов Active Directory, используют динамический DNS для публикации самих себя в базе DNS. Если Вы уже начали применять комбинацию WINS-DNS, то можете считать, что подготовили почву для прозрачного перехода к динамическому DNS.
Форма именований, принятая в каталоге, влияет, как на пользователей, так и на приложения. Например, если Вы желаете отыскать объект в каталоге, то должны точно указать имя свойства, применяемого в качестве критерия поиска.
В различных стандартах (как де-факто, так и де-юре) используются различные форматы имен. Многие из них поддерживаются в Active Directory, что позволяет пользователям, например, обращаться к объектам привычным образом. Перечислим некоторые из поддерживаемых систем именований.
• RFC822. Этот стандарт именований хорошо знаком пользователям Интернета. Кто из Вас не встречался с формой имя@домен, отправляя или получая сообщения по электронной почте? Если Вы, например, хотите задать вопрос Билу Гейтсу, то можете воспользоваться адресом askbill@microsoft.com. Адрес в таком формате можно не только поместить на визитной карточке, но и использовать для входа и систему.
• HTTP URL. Как упоминалось ранее, к службе каталогов Active Directory можно обратиться по протоколу HTTP, Для этого необходимо указать имя URL, формат которого также хорошо знаком пользователям Интернета: http : //имя-домена/путь-к-странице. При этом имя домена — это имя сервера, на котором установлена служба каталога, а путь к странице — путь в иерархичной структуре каталога к интересующему объекту. Например:
• LDAP URL и имена Х.500. В Active Directory
поддерживается доступ и по протоколу LDAP. То, что имена LDAP сложнее по
сравнению с именами Интернета, не так важно — ведь обычно LDAP
используется приложениями. В рамках LDAP действуют соглашения об
именовании Х.500, называемые атрибутированным именованием. Имя при этом
состоит из URL сервера, на котором располагается каталог, и далее —
атрибутированного имени объекта. Например: LDAP://My
Server.MyCorp.Ru/CN=IvanDemidov,OU=Russian,OU=Finance, OU=Division,0=MyCorp,C=RU • Имена UNC. В Active Directory поддерживается также и
соглашение об универсальном именовании, которое традиционно используется в
сетях Windows NT для ссылок на совместно используемые ресурсы: тома,
принтеры и файлы. Вы можете обратиться к файлу, опубликованному в Active
Directory, например, так: \\MyServer.MyCorp,Ru\Division.Finance.Russian,MyVolume\WordDocs\ YearBudget.doc В каталоге LDAP пространство имен может быть либо смежным,
либо раздельным. В первом случае имя дочернего домена всегда содержит имя
родительского домена. Например, если домен с именем DC=Finanсе, DC=MyCorp,
DC=Ru — дочерний для домена DC=MyCorp, DC=Ru, то это пространство смежных
имен. Имя родительского домена всегда может быть восстановлено при
отбрасывании первой части дочернего имени. В пространстве раздельных имен родительский и дочерний домены
не связаны друг с другом непосредственно. Например, хотя домен
DC=Finance,DC=Ru — дочерний для домена DC=MyCorp,DC=Ru, его имя
не содержит имени родительского домена. Смежные имена или раздельные важно при поиске. В случае
применения смежных имен на контроллере домена всегда создаются
ссылки (referrals) на дочерние домены. При использовании раздельных
имен поиск останавливается и ссылки не создаются. Одновременное использование смежных и раздельных имен
делает механизм поиска в древовидной структуре сложным для
понимания. Поэтому в Active Directory вводятся понятия деревьев и леса. Тиражирование Active
Directory Active Directory использует тиражирование типа мульти-мастер.
Как уже упоминалось, в этой службе каталогов более не существует
различий между контроллерами доменов — они все равноправны.
Изменения, внесенные в каталог на одном контроллере, тиражируются на
остальные. Но хотя концептуально такой подход проще существовавшей в
предыдущих версиях модели с одним главным и несколькими
резервными контроллерами домена, он требует принятия специальных мер по
синхронизации тиражируемой информации. Тиражирование Active Directory
основано не на временных интервалах, а на последовательных номерах обновлений
USN (Update Sequence Numbers). В каждом контроллере домена имеется таблица,
где записаны как свой собственный номер USN, так и USN партнеров по
тиражированию. При тиражировании происходит сравнение последнего известного
USN партнера с тем, который сообщается. И если сообщенный номер больше
записанного, запрашиваются все изменения у партнера по тиражированию
(такой тип тиражирования носит название запрашиваемого). После
обновления данных USN на контроллере домена становится равным
значению, полученному от партнера. Если данные одного и того же объекта изменились сразу на
нескольких контроллерах домена, то обновление выполняется
следующим образом. • По номеру версии. У каждого свойства свой номер
версии. С помощью этого номера определяется «наиболее актуальное», то
есть имеющее наибольший номер версии, свойство. Это не всегда
верное решение, однако оно позволяет согласовывать версии без
дополнительных переговоров с партнером по тиражированию и гарантирует
идентичность данных на всех контроллерах доменов. • По временной отметке. Если свойства имеют одинаковый
номер версии, то проверяется временная отметка, создаваемая вместе с
номером версии при модификации свойств. При этом предполагается, что все
контроллеры домена синхронизованы по времени. Предпочтение отдается версии,
созданной позднее. И опять же, это не всегда верно, но лучше обслуживать
пользователей, чем заниматься длительными переговорами относительно того,
кто «главнее». • По размеру буфера. Если и номер версии, и временные
отметки совпадают, то выполняется сравнение в двоичном виде, причем
предпочтение получает то свойство, которое в двоичном виде
занимает больший объем. Если размеры одинаковы, то считается, что обе
версии идентичны и в расчет не принимается ни одна из них. Давайте проиллюстрируем все сказанное на примере. Допустим,
что два администратора на разных контроллерах домена вносят изменения
в свойства группы AcctUsers. Один из них предоставил право модификации
каталога FinRus, а второй — право модификации каталога FinAdmin, но сделал
это на минуту позже первого. При согласовании версий на третьем контроллере
домена будет обнаружено, что номера версий совпадают, а время модификации на
втором контроллере — более позднее. Поэтому в расчет будет принято только
изменение, сделанное вторым администратором. Замечание. Все операции согласования заносятся в
журнал, так что администраторы могут при необходимости восстановить
прежние значения. Концепция узлов (sites) используется продуктами семейства
Microsoft BackOffice для минимизации графика в глобальной сети. К
сожалению, в каждом продукте эта концепция трактуется по-своему. В Windows NT
5.0 вводится еще одно новшество: концепция не оптимизирована под
какое-либо определенное приложение, а предполагает в качестве основы
сеть IP, для которой обеспечиваются наилучшие условия подключений. В
будущем планируется, что все приложения BackOffice будут использовать
именно эту концепцию узла. Узел с Active Directory состоит из одной или нескольких
подсетей IP. Администратор может определять эти подсети, а также добавлять к
ним новые. При этом он исходит из следующих посылок: • оптимизация графика тиражирования между узлами по
медленным линиям; • создание клиентам наилучших условий для быстрого
обнаружения ближайших к ним контроллеров. Тиражирование внутри узла и между узлами осуществляется по
различным топологиям. Внутри узла контроллер домена задерживает
оповещение о сделанных изменениях на некоторый устанавливаемый
промежуток времени (по умолчанию равный 10 минутам). В отличие от Microsoft Exchange в Active Directory можно изменять
топологию тиражирования внутри узла. По умолчанию это двунаправленное
кольцо, однако Вы можете полностью переопределить топологию и задать
ее, скажем, в виде звезды. В любом случае служба каталогов будет отслеживать целостность
топологии, то есть ни один контроллер домена не будет исключен
из процесса тиражирования. Для этого на всех контроллерах домена
исполняется отдельный контрольный процесс, так называемый КСС (Knowledge
Consistency Checker). КСС восстанавливает топологию тиражирования в случае
нарушения. Концепция поиска ближайшего ресурса или контроллера домена
позволяет сократить трафик в низкоскоростных частях глобальных
сетей. Для поиска ближайших ресурсов или контроллеров домена клиенты могут
использовать информацию об узле. Начиная вход в сеть, клиент получает от
контроллера домена имя узла, к которому принадлежит, имя узла к которому
относится контроллер домена, а также информацию о том, является ли данный
контроллер домена ближайшим к клиенту. Если это не ближайший контроллер, то
клиент может обратиться к контроллеру домена в собственном узле и в
дальнейшем работать с ним, как с ближайшим контроллером. Так как данная
информация сохраняется в реестре, клиент может ее использовать при
следующем входе в сеть. Если пользователь перемещается со своей рабочей станцией в
новое место, то при входе в сеть станция обращается к прежнему
контроллеру домена. Только в этом случае он уже не является ближайшим, и
сообщает клиенту информацию о ближайшем узле. Эта информация может
быть использована клиентом для доступа к DNS и определения адреса ближайшего
контроллера домена. Вспомним определения, данные в начале этой главы. Итак,
дерево характеризуется: • иерархией доменов; • пространством смежных имен; • доверительными отношениями Kerberos между доменами; • использованием общей схемы; • принадлежностью к общему глобальному каталогу. Лес
характеризуется: • одним или несколькими наборами деревьев; • раздельными пространствами имен между этими деревьями; • доверительными отношениями Kerberos между доменами; • использованием общей схемы; • принадлежностью к общему глобальному каталогу. На рисунке изображен пример леса. DNS-имя корневого домена в
левом поддереве — microsoft-com.; LDAP-имя этого домена в Active
Directory можно записать как DC=microsoft, DOCOM, o=Internet. Корневое
имя домена во втором поддереве — DC=MSN, DC=COM, o=Internet. Хорошо
видно, что пространства имен разделены. Поддомены в каждом из деревьев принадлежат к смежному
пространству имен. Например LDAP-имя для российского домена внутри
Microsoft могло бы выглядеть как DC=russia,DC=microsoft,DC=COM,o=Internet.
Концепция смежных деревьев в лесу позволяет понять многие
механизмы: как осуществляется поиск в лесу или в поддеревьях, почему
объекты безопасности остаются действительными в рамках леса и др.
Можно формировать виртуальные команды пользователей, находящихся
в разных деревьях леса, а также включать в лес любое дерево.
Последнее свойство используется, например, при слиянии предприятий или
начальном разворачивании сети. Для обеспечения работы дерева или леса необходимы метаданные.
Они хранятся в двух контейнерах (конфигурации и схемы), в
каждом из которых своя система имен и топология тиражирования. В
конфигурационном контейнере содержится информация, связующая для
деревьев в лесу: о доступных контроллерах домена, узлах и вообще всех
контроллерах домена. При добавлении в домен нового контроллера
конфигурационная информация обновляется и тиражируется. Возможно, неискушенный читатель, ознакомившись с
предыдущим разделом, решит, что автор бредит, настолько рассуждения о
деревьях и лесе на первый взгляд кажутся бессвязными. Могу лишь
посоветовать абстрагироваться от привычного восприятия леса и деревьев как
объектов природы и настроиться на то, что это объекты Active Directory.
Как и любыми, объектами службы каталогов необходимо
управлять. Представьте себе небольшую фирму, организовавшую деревья и леса
Active Directory в соответствии со своей структурой. Более
чем очевидно, что это нельзя сделать раз и навсегда. Предприятие может
расти, его структура — перестраиваться, отделы и подразделения —
исчезать или создаваться заново. В соответствии с этими изменениями
надо будет модифицировать и структуру сети, и такие возможности в
Active Directory предусмотрены. К операциям реструктуризации и
переименования объектов в каталоге относятся: • простое добавление доменов; • простое удаление доменов; • переименование доменов; • переразмещение деревьев доменов и лесов; • слияние деревьев в лес. Добавление домена — самая простая из перечисленных
операций. Домен можно подключить к дереву во время установки контроллера
домена. Все что для этого нужно сделать — указать существующий в
Active Directory домен в качестве родительского. При этом между
доменами будут установлены доверительные отношения Kerberos, что
позволит новому домену присоединиться к дереву. Удаление домена не является удалением в полном смысле
этого слова — домен просто исключается из дерева. Проделать эту
операцию можно в любое время. Но предварительно следует убедиться, что у
исключаемого домена нет дочерних доменов — иначе доверительные отношения
дочернего домена окажутся разорванными, и он также будет исключен из
дерева. Любой объект в каталоге Active Directory может иметь
несколько имен: общее, относительное и т. п. Единственным всегда неизменным
идентификатором объекта является Глобальный уникальный идентификатор
GU1D (Globally Unique Identifier). GUID - это многозначное число, создаваемое
контроллерами домена. Алгоритм создания идентификатора не допускает
дублирования. Именно этот никогда не изменяемый идентификатор может
использоваться в Active Directory для того, чтобы свободно
переименовывать домены, как и любые объекты4. GUID также позволяет перемещать домены в дереве или в
лесу. Во время частичного тиражирования в глобальный каталог заносится
подмножество свойств объекта. В это подмножество входит и GUID.
Если объект перемещен, то глобальный каталог может использовать GUID для
поиска объекта и его отличительного имени на основе нового относительного
ID и LDAP-пути к новому местоположению. 4 В Windows NT 5.0 скорее всего не будет реализован механизм
переименования доменов, так как разработчики столкнулись с целым рядом
непредвиденных трудностей, преодоление которых перенесено к моменту
выхода Windows NT 6.0. Включение домена в лес не сложнее подключения к дереву
доменов и рассматривалось ранее. Если используется сервер динамического DNS Windows NT 5.0, то
при перемещении или переименовании домена средствами администрирования
автоматически выполняется коррекция записей в базе DNS. При использовании
UNIX DNS-сервера создается файл, в который заносятся и подлежащие удалению,
и новые записи. Дополнительно в Windows NT Workstation 5.0 автоматически
изменяются настройки TCP/IP, и вносится новое имя домена. Понятие же "физического вакуума" в релятивистской квантовой теории поля подразумевает, что во-первых, он не имеет физической природы, в нем лишь виртуальные частицы у которых нет физической системы отсчета, это "фантомы", во-вторых, "физический вакуум" - это наинизшее состояние поля, "нуль-точка", что противоречит реальным фактам, так как, на самом деле, вся энергия материи содержится в эфире и нет иной энергии и иного носителя полей и вещества кроме самого эфира. В отличие от лукавого понятия "физический вакуум", как бы совместимого с релятивизмом, понятие "эфир" подразумевает наличие базового уровня всей физической материи, имеющего как собственную систему отсчета (обнаруживаемую экспериментально, например, через фоновое космичекое излучение, - тепловое излучение самого эфира), так и являющимся носителем 100% энергии вселенной, а не "нуль-точкой" или "остаточными", "нулевыми колебаниями пространства". Подробнее читайте в FAQ по эфирной физике.
HTTP://MyServer.MyCorp.Ru/BIN/Division/Finance/Russian/IvanDemido

Смежные и раздельные пространства имен
Узлы и домены
Деревья и леса
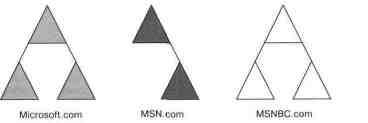
Пример леса
Управление деревом и лесом
Знаете ли Вы, что электромагнитное и другие поля есть различные типы колебаний, деформаций и вариаций давления в эфире.
![]()
